Welcome to Jarvis's Blog!
欢迎来到 Jarvis 的博客!
-
多尺度上下文信息 (Multi-Scale Context)
上下文信息 (context), 长期依赖 (long-range dependencies), 注意力 (attention) 这些概念提出的目的都是希望我们的特征能够在卷积等局部操作的基础上, 更多的吸收图像全局的信息, 从而提高特征的判别性. 这些概念一开始在 NLP 任务中得到了广泛的思考, 比如 LSTM, Attention 机制 (因为自然语言是天然的序列, 长距离的特征依赖尤为明显), 而近年来人们发现在 CV 中对这些概念的扩展和应用也能极大的提高特征的表达能力.
-
PSPNet: Segmentation Network
场景解析 (scene parsing) 属于语义分割, 但需要分割场景中更多的类别, 因此会遇到大量外观相似的类别而导致混淆. PSPNet 的思想是某些混淆可以通过关注上下文来解决. 比如车和船的外观可能很像 (纹理相似), 但船一般在水里 (“水”为上下文), 车一般在路上 (“道路”为上下文), 因此在分类的时候同时关注上下文特征是有益的.
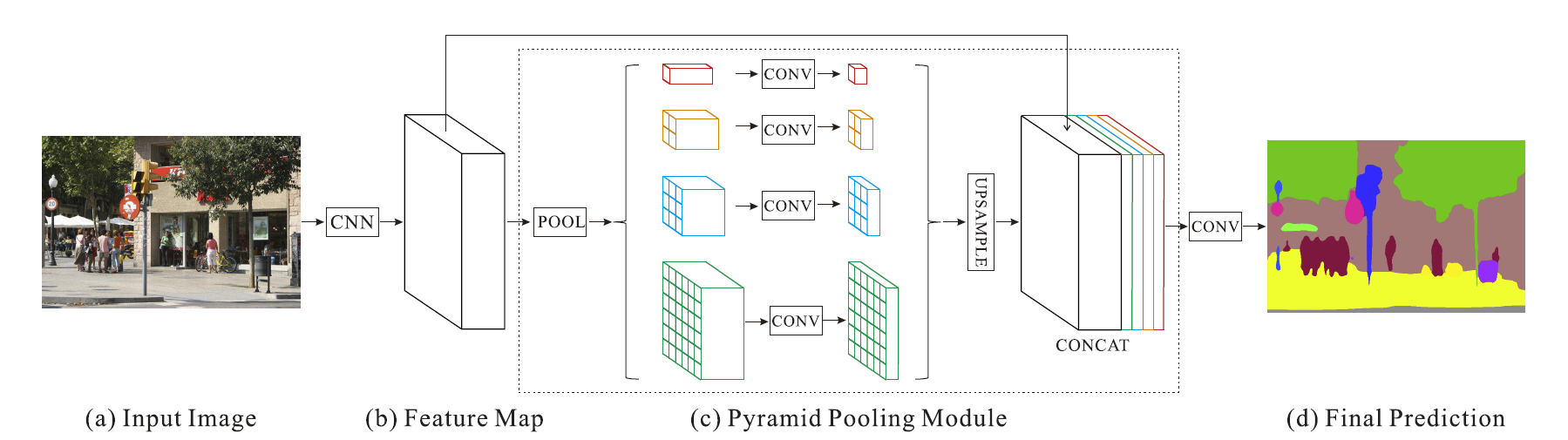
-
归纳性偏好 (Inductive Bias)
深度神经网络为什么适合图像特征的提取和分析? 为什么近年来火热的对比学习能把无监督下的特征表示很好的学出来? 深度神经网络到底有什么魔法? 要思考上面的问题, 首先要了解一个概念: 归纳性偏好(inductive bias).

-
FSS1000 数据集
Few-Shot Segmentation (FSS) 是元学习中的一类分割任务, 希望训练出的模型可以在少量有标签的样本下就能泛化到新的类别上. 对比 ImageNet 上百万图像的分类任务目的是识别不同类别的物体, FSS 是从大量类别中学习广泛的特征, 并在少量有标签样本的引导下识别新类别的物体. 所以我们应当期望训练集中包含大量的类别帮助模型学习广泛的特征. 但是 FSS 经典的几个数据集 PASCAL VOC 和 COCO 只有 20 个 80 个类别, 因此港科大和腾讯联合退出了 FSS 1000 数据集用于 FSS, 其中包含了 1000 个类别.
-
半监督学习(Semi-Supervised Learning, SSL)
深度学习 (deep learning) 通过监督学习 (supervised learning) 在大量的机器学习任务上取得了瞩目的成就, 如 ImageNet 上超过 90% 的分类准确率, Cityscapes 上超过 85% 的分割准确率. 然而, 实现高精度的分类, 分割等任务需要大规模有标签的训练数据, 如 ImageNet 的百万张图像或是 Cityscapes 上数千张 1080p 分辨率图像的像素级标注, 都需要耗费大量的人力物力, 同时在这些数据上训练的模型往往在跨域的数据泛化上仍然具有挑战性 (如医学图像). 虽然数据标注难以获取, 但从多种渠道收集无标注数据是相对容易的, 因此研究者逐渐把目光转向如何利用少部分有标注数据和大规模的无标注数据来训练模型 (比如, 有标签数据占整体的 1-10%). 这种同时利用少量有标注数据和大量无标注数据训练模型的方法称为半监督学习 (semi-supervised learning, SSL).
-
PyTorch 训练慢的问题
本文记录了使用 PyTorch 训练模型时张量不连续导致速度极慢的问题.
-
Useful Figures in Deep Learning
- 序列平均值的统一表示 (Unified Representation of Sequence Averages)
- 变分下界与VAE (Variantional Lower Bound and VAE)
- 大模型(三): 多模态大模型 (Multimodal Models)
- 大 Batch Size 训练模型(Large Batch Training)
- 大模型(二): DeepMind 的 Scaling Laws 有什么不同?
- 大模型(一): Scaling Laws - OpenAI 提出的科学法则
- Transformer 的参数量和计算量
- ChatGPT 70 款插件测评 惊艳的开发过程与宏大的商业化愿景
- HTTPS 配置教程 (A Tutorial for HTTPS)
- 生成扩散模型(五): 采样加速 (Generative Diffusion Model: Sampling Acceleration)