本文假设读者已经懂得了 Tensorflow 的一些基础概念, 如果不懂, 则移步 TF 官网 .
在 Tensorflow 中我们一般使用 tf.train.Saver() 定义的存储器对象来保存模型, 并得到形如下面列表的文件:
checkpoint
model.ckpt.data-00000-of-00001
model.ckpt.index
model.ckpt.meta
其中 checkpoint 文件中记录了该储存器历史上所有保存过的模型(三件套文件)的名称, 以及最近一次保存的文件, 这里我们并不需要 checkpoint .
Tensorflow 模型冻结是指把计算图的定义和模型权重合并到同一个文件中, 可以按照以下步骤实施:
- 恢复已保存的计算图: 把预先保存的计算图(meta graph) 载入到默认的计算图中, 并将计算图序列化.
- 加载权重: 开启一个会话(Session), 把权重载入到计算图中
- 删除推导所需以外的计算图元数据(metadata): 冻结模型之后是不需要训练的, 所以只保留推导(inference) 部分的计算图 (这部分可以通过指定模型输出来自动完成)
- 保存到硬盘: 序列化冻结的 graph_def 协议缓冲区(Protobuf) 并转储到硬盘
注意: 前两步实际上就是 Tensorflow 中的加载计算图和权重, 关键的部分就是图的冻结, 而冻结 TF 已经提供了函数.
1. 模型的保存
TF 使用 saver = tf.train.Saver() 定义一个存储器对象, 然后使用 saver.save() 函数保存模型. saver 定义时可以指定需要保存的变量列表, 最大的检查点数量, 是否保存计算图等. 官网例子如下:
1
2
3
4
5
6
7
8
9
10
11
12
v1 = tf.Variable(..., name='v1')
v2 = tf.Variable(..., name='v2')
# 使用字典指定要保存的变量, 此时可以为每个变量重命名(保存的名字)
saver = tf.train.Saver({'v1': v1, 'v2': v2})
# 使用列表指定要保存的变量, 变量名字不变. 以下两种保存方式等价
saver = tf.train.Saver([v1, v2])
saver = tf.train.Saver({v.op.name: v for v in [v1, v2]})
# 保存相应变量到指定文件, 如果指定 global_step, 则实际保存的名称变为 model.ckpt-xxxx
saver.save(sess, "./model.ckpt", global_step)
每保存一次, 就会产生前言所述的四个文件, 其中 checkpoint 文件会更新. 其中 saver.save() 函数的 write_meta_graph 参数默认为 True , 即保存权重时同时保存计算图到 meta 文件.
2. 模型的读取
TF 模型的读取分为两种, 一种是我们仅读取模型变量, 即 index 文件和 data 文件; 另一种是读取计算图. 通常来说如果是我们自己保存的模型, 那么完全可以设置 saver.save() 函数的 write_meta_graph 参数为 False 以节省空间和保存的时间, 因为我们可以使用已有的代码直接重新构建计算图. 当然如果为了模型迁移到其他地方, 则最好同时保存变量和计算图.
2.1 读取计算图
2.1.1 读取计算图核心函数
从 meta 文件读取计算图使用 tf.train.import_meta_graph() 函数, 比如:
1
2
with tf.Session() as sess:
new_saver = tf.train.import_meta_graph("model.ckpt.meta")
此时计算图就会加载到 sess 的默认计算图中, 这样我们就无需再次使用大量的脚本来定义计算图了. 实际上使用上面这两行代码即可完成计算图的读取. 注意可能我们获取的模型(meta文件)同时包含定义在CPU主机(host)和GPU等设备(device)上的, 上面的代码保留了原始的设备信息. 此时如果我们想同时加载模型权重, 那么如果当前没有指定设备的话就会出现错误, 因为tensorflow无法按照模型中的定义把某些变量(的值)放在指定的设备上. 那么有一个办法是增加一个参数清楚设备信息.
1
2
with tf.Session() as sess:
new_saver = tf.train.import_meta_graph("model.ckpt.meta", clear_devices=True)
2.1 节剩下的内容我们尝试探索一下 TF 中图的一些内容和基本结构, 不感兴趣可以跳过直接看 2.2 节.
2.1.2 获取计算图内的任意变量/操作
接下来可以使用 get_all_collection_keys() 来获取该计算图中所有的收集器的键:
1
2
3
4
5
6
7
8
sess.graph.get_all_collection_keys()
# 或
sess.graph.collections
# 或
tf.get_default_graph().get_all_collection_keys()
# 输出
['summaries', 'train_op', 'trainable_variables', 'variables']
进一步我们可以通过 get_collection() 函数来获取每个收集器的内容:
1
2
3
4
from pprint import pprint
pprint(sess.graph.get_collection("summaries"))
pprint(sess.graph.get_collection("variables"))
...
通过浏览 variables , trainable_variables , sumamries 和 train_op 中的变量我们可以初步推断计算图的结构和重要信息. 此外, 读取计算图后还可以直接使用 tf.summary.FileWriter() 保存计算图到 tensorboard, 从而获得更直观的计算图.
要注意的是, get_collection() 方法只能获得保存在收集器中的变量, 而无法看到其他操作(如 placeholder), 除非在脚本中构建计算图时刻意把某些操作加入到某个 collection . 所以我们可以用更骚的方法来获取这些没有包含在 collection 中的操作:
1
2
3
4
sess.graph.get_operations()
# 或
for op in sess.graph.get_operations():
print(op.name, op.values())
函数 get_operations() 返回一个列表, 列表的每个元素均为计算图中的一个 Operation 对象. 举个栗子, 当我们使用 reshape() 函数时 tf.reshape(x, [-1, 28, 28, -1]) 在计算图中会产生这样的计算节点

图 1: Tensorboard 中操作 tf.reshape(x, shape) 的计算图
其中 x 就是上图中左下角的 input , 右侧的小柱状图表示我对 Reshape 的输出做了 summary 并命名为 input . Tensorboard 中类似于 shape 这样的小圆点表示常数(类型仍然是 Operation), 点击后可以看到该操作的属性
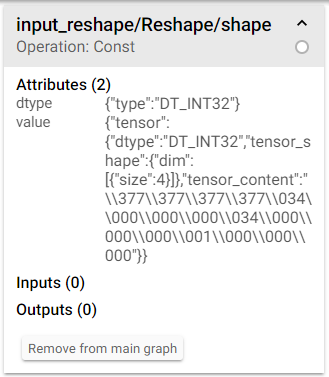
图 2: Tensorboard 中常量 shape 的属性
而属性中的 tensor_content 的值就是该常数被赋予的值. 实际上我们也可以通过代码开查看计算图中操作的属性:
1
sess.graph.get_operation_by_name("input_reshape/Reshape/shape").node_def
通过名称索引该 reshape 操作, 并获取其 node_def 属性即可得到和图 2 相同的信息. 注意到, shape 的值是一个字符串 "\377\377\377\377\034\000\000\000\034\000\000\000\001\000\000\000" , 该字符串可以这么理解: 没饿过形如 \377 的单元表示一个字节, 该字节用八进制来表示, 比如 \377 还原为二进制为 011 111 111, 由于我们可以看到该常量的类型为 DT_INT32, 即四个字节, 所以每四个字节拼成一个长整型数字, 即 \377\377\377\377 表示成十六进制为FFFFFFFF , 十进制为 -1; 而 \034\000\000\000 (注意这里是小端表示法, litter endian, 即从后往前读取字节)表示成十六进制为 1C000000 , 十进制为 28 .
2.2 读取模型变量
2.2.1 读取模型变量核心函数
读取模型权重也很简单, 仍然使用 tf.train.Saver() 来读取:
1
2
3
4
5
6
# 首先定义一系列变量
...
# 载入变量的值
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, "path/to/model.ckpt")
注意模型路径中应当以诸如 .ckpt 之类的来结尾, 即需要保证实际存在的文件是 model.ckpt.data-00000-of-00001 和 model.ckpt.index , 而指定的路径是 model.ckpt 即可. 类似地, 如果我们只需要载入部分模型变量, 则和保存模型变量类似地可以在 tf.train.Saver() 中使用字典或列表来指定相应的变量. 注意, 载入的模型变量是不需要再初始化的(即不需要 tf.variable_initializer() 初始化), 所以如果只载入部分变量, 则要么手动指定, 要么先初始化所有的变量, 再从检查点载入变量的值.
2.2.2 获取任意模型变量的属性
另外, 我们还可以使用 TF 内置的函数 tf.train.get_checkpoint_state() 来获得最近的一次检查点的文件名:
1
2
3
ckpt = tf.train.get_checkpoint_state(log_dir)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
有时候我们需要浏览变量中变量名/形状/值, 则可以预先通过下面的代码进行查看:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from tensorflow.python import pywrap_tensorflow as pt
reader = pt.NewCheckpointReader("path/to/model.ckpt")
# 获取 变量名: 形状
vars = reader.get_variable_to_shape_map()
for k in sorted(vars):
print(k, vars[k])
# 获取 变量名: 类型
vars = reader.get_variable_to_dtype_map()
for k in sorted(vars):
print(k, vars[k])
# 获取张量的值
value = reader.get_tensor("tensor_name")
其中 get_variable_to_shape_map() 函数会生成一个 {变量名: 形状} 的字典, 而 get_variable_to_dtype_map() 类似. 而 get_tensor() 函数会返回相应变量名的变量值, 返回一个 numpy 数组.
另一种获取方法则是 TF 官方文档给出的使用 tensorflow.python.tools.insepct_checkpoint , 示例代码如下, 不再赘述:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from tensorflow.python.tools import inspect_checkpoint as chkp
# 打印检查点所有的变量
chkp.print_tensors_in_checkpoint_file("/tmp/model.ckpt", tensor_name='', all_tensors=True)
# tensor_name: v1
# [ 1. 1. 1.]
# tensor_name: v2
# [-1. -1. -1. -1. -1.]
# 仅打印检查点中的 v1 变量
chkp.print_tensors_in_checkpoint_file("/tmp/model.ckpt", tensor_name='v1', all_tensors=False)
# tensor_name: v1
# [ 1. 1. 1.]
3. 模型的冻结
我们从已有的三个检查点文件出发生成冻结模型:
model.ckpt.data-00000-of-00001
model.ckpt.index
model.ckpt.meta
假设我们已经通过上面模型的读取知道了我们需要的最终输出的张量名为 "Accuracy/prediction" 和 "Metric/Dice" , 则按照前言部分的步骤来冻结模型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import tensorflow as tf
# 指定模型输出, 这样可以允许自动裁剪无关节点. 这里认为使用逗号分割
output_nodes = ["Accuracy/prediction", "Metric/Dice"]
# 1. 加载模型
saver = tf.train.import_meta_graph("model.ckpt.meta", clear_devices=True)
with tf.Session(graph=tf.get_default_graph()) as sess:
# 序列化模型
input_graph_def = sess.graph.as_graph_def()
# 2. 载入权重
saver.restore(sess, "model.ckpt")
# 3. 转换变量为常量
output_graph_def = tf.graph_util.convert_variables_to_constants(sess,
input_graph_def,
output_nodes)
# 4. 写入文件
with open("frozen_model.pb", "wb") as f:
f.write(output_graph_def.SerializeToString())
注意, 我们冻结模型的目的是不再训练, 而仅仅做正向推导使用, 所以才会把变量转换为常量后同计算图结构保存在协议缓冲区文件(.pb)中, 因此需要在计算图中预先定义输出节点的名称.
4. 模型的执行
模型的执行过程也很简单, 首先从协议缓冲区文件(*.pb)中读取模型, 然后导入计算图
1
2
3
4
5
6
7
8
# 读取模型并保存到序列化模型对象中
with open(frozen_graph_path, "rb") as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
# 导入计算图
graph = tf.Graph()
with graph.as_default():
tf.import_graph_def(graph_def, name="MyGraph")
之后就是获取输入和输出的张量对象, 注意, 在 TF 的计算图结构中, 我们只能使用 feed_dict 把数值数组传入张量 Tensor , 同时也只能获取张量的值, 而不能给Operation 赋值. 由于我们导入序列化模型到计算图时给定了 name 参数, 所以导入所有操作都会加上 MyGraph 前缀.
接下来我们获取输入和输出对应的张量:
1
2
3
4
x_tensor = graph.get_tensor_by_name("MyGraph/input/image-input:0")
y_tensor = graph.get_tensor_by_name("MyGraph/input/label-input:0")
keep_prob = graph.get_tensor_by_name("MyGraph/dropout/Placeholder:0")
y_target_tensor = graph.get_tensor_by_name("MyGraph/accuracy/accuracy:0")
注意 TF 中的张量名均是 op:num 的形式, 其中的 op 表示产生该张量的操作名(可由 tensor.op.name 获取), 而冒号后面的数字表示该张量是其对应操作的第几个输出, 下面的图给出了张量和操作名的关系
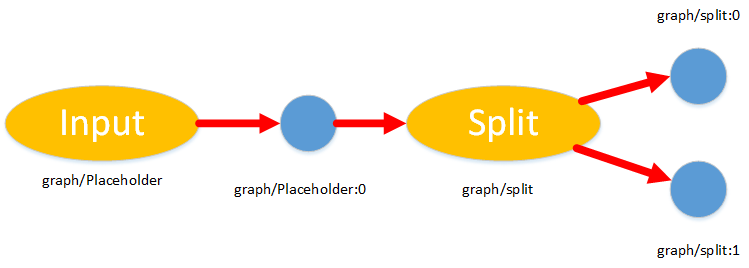
图 3: Tensorflow 中张量和相应操作的命名关系
最后我们提取 mnist 的数据, 并执行验证:
1
2
3
4
5
6
7
8
9
10
11
12
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("mnist_data", one_hot=True)
x_values, y_values = mnist.test.next_batch(10000)
with tf.Session(graph=graph) as sess:
acc = sess.run(acc_tensor, feed_dict={x_tensor: x_values,
y_tensor: y_values,
keep_prob: 1.0})
print(acc)
# 输出
0.9665