Welcome to Jarvis's Blog!
欢迎来到 Jarvis 的博客!
-
正态分布的若干结论 (Conclusions of Gaussian distributions)
本文记录一些遇到的有关正态分布的计算和结论.
正态分布的形式, 正态分布的 KL 散度, 正态分布随机变量的和, 重参数化技巧
-
生成扩散模型(二): VAE 观点 (Generative Diffusion Model: From the Perspective of VAE)
我们在前面一篇文章《生成扩散模型(一): 基础》中通过迭代式的图像加噪和去噪的角度分析了生成扩散模型, 并最终推导出了和 DDPM 论文中一样的损失函数. 如果我们把图像加噪的过程看作编码, 把去噪的过程看作解码, 那么这两个过程合起来就可以看作一个自动编码器 (autoencoder).
-
生成扩散模型(一): 基础 (Generative Diffusion Model: Basic)
说起生成模型, 我们最先想到的应该就是大名鼎鼎的 GAN 和 VAE 了. 其他还有一些小众的如 Flow 模型, VQ-VAE 等. 过去的八年里我们已经见识了深度生成模型在图像生成方面取得的进展, 如 BigGAN. 近两年, 有另一个小众的——生成扩散模型 (Diffusion Model)——异军突起, 尤其是在 OpenAI 和 Google 把扩散模型和 Visual-Language 语言模型结合起来给出了惊人的 “文本 –> 图像” 生成效果之后.

-
匈牙利算法 (Hungarian Algorithm)
最近在看 DETR 和 MaskFormer 的时候, 遇到两个集合最优匹配的问题. 其中用到的算法便是匈牙利算法.
匈牙利算法(Hungarian Algorithm) 是一种在多项式时间内求解的分配问题的组合优化算法, 由 Harold Kuhn 在1955年完善并发表. 算法的命名是因为该算法很大程度上是基于两位匈牙利数学家 Dénes Kőnig and Jenő Egerváry 的工作而来的. James Munkres 在 1957 年证明了该算法的复杂度是(强)多项式时间的, 此后该算法也被称为 Kuhn-Munkres 算法或 Munkres 分配算法. 原始算法的时间复杂度为 \(O(n^4)\), Edmonds 和 Karp, 以及 Tomizawa 发现该算法可以优化到 \(O(n^3)\).
-
Prompt 学习和微调 (Prompt Learning and Tuning)
Self-Attention 和 Transformer 自从问世就成为了自然语言处理领域的新星. 得益于全局的注意力机制和并行化的训练, 基于 Transformer 的自然语言模型能够方便的编码长距离依赖关系, 同时在大规模自然语言数据集上并行训练成为可能. 但由于自然语言任务种类繁多, 且任务之间的差别不太大, 所以为每个任务单独微调一份大模型很不划算. 在 CV 中, 不同的图像识别任务往往也需要微调整个大模型, 也显得不够经济. Prompt Learning 的提出给这个问题提供了一个很好的方向.
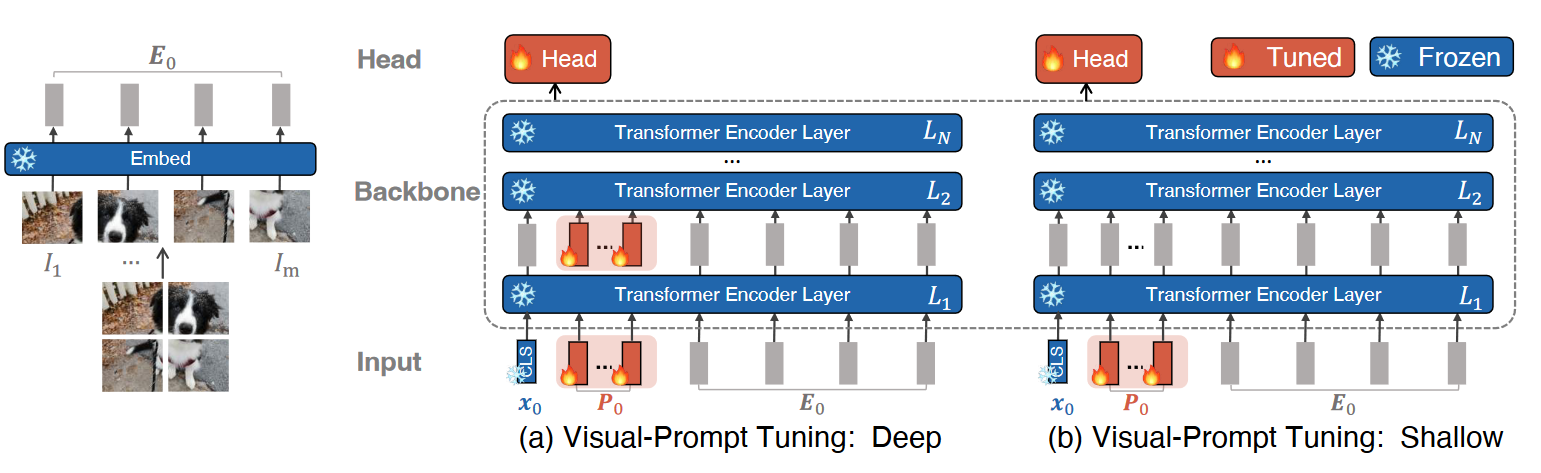
-
注意力机制和 Transformer (Attention and Transformer)
Self-Attention 和 Transformer 自从问世就成为了自然语言处理领域的新星. 得益于全局的注意力机制和并行化的训练, 基于 Transformer 的自然语言模型能够方便的编码的长距离依赖关系, 同时在大规模自然语言数据集上并行训练成为可能.

-
MongoDB + Omniboard 实验管理
本文面向机器学习工作者, 使用 Sacred 库来管理实验: MongoDB 存储实验数据, Omniboard 可视化数据库.
我们前面已经介绍过在机器学习实验中如何使用 Sacred (见 Sacred 教程), 这里我们将介绍如何使用 MongoDB 对 Sacred 进行实验管理, 并使用 Omniboard 可视化实验信息.
- 序列平均值的统一表示 (Unified Representation of Sequence Averages)
- 变分下界与VAE (Variantional Lower Bound and VAE)
- 大模型(三): 多模态大模型 (Multimodal Models)
- 大 Batch Size 训练模型(Large Batch Training)
- 大模型(二): DeepMind 的 Scaling Laws 有什么不同?
- 大模型(一): Scaling Laws - OpenAI 提出的科学法则
- Transformer 的参数量和计算量
- ChatGPT 70 款插件测评 惊艳的开发过程与宏大的商业化愿景
- HTTPS 配置教程 (A Tutorial for HTTPS)
- 生成扩散模型(五): 采样加速 (Generative Diffusion Model: Sampling Acceleration)