1. Introduction
深度神经网络(DNN)的泛化性能相当依赖于训练集的规模(size)和丰富性(variations). 但是在很多场景下无法搜集到如此多的数据, 如皮肤病, 卫星图片(飞机残骸). 尽管每种特殊的情况发生的概率很低, 人为处理的成本也很低, 但当我们有大量的”特殊情况”时, 问题就变得复杂了起来.
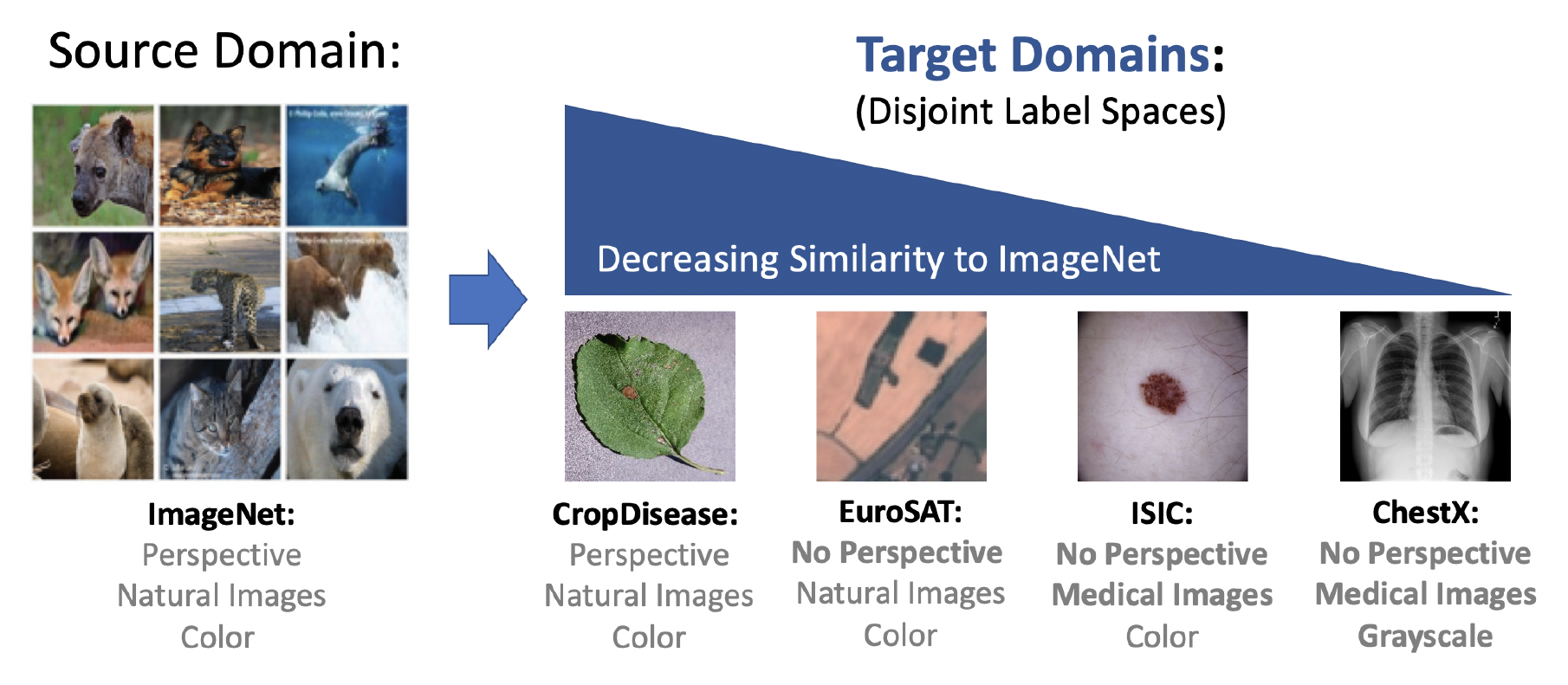
图 1. 不同数据集的域差异
与DNN相比, 人类在某些情况下可以快速地从少量样本中学习新的类别, 如:
- 类别在样本间表现出可预测的变化时
- 前景与背景的对比比较明显时
但人也不是万能的, 在遇到(与之前完全不同的)全新的领域或场景时也会表现得不如人意, 如:
- 皮肤病诊断
- 放射学诊断 (应该是指医学影像诊断)
少样本学习
meta-training vs meta-testing: 类别不重复, 少量的监督样本
Chen等人(A closer look at FSL)1 指出基于 meta-learning 的少样本学习方法在 domain shift 较大的时候表现还不如传统的 pre-training + fine-tuning. 因此本文提出了 跨域少样本学习 (cross-domain few-shot learning, CS-FSL) 并建立起 benchmark, 以 ImageNet 为参照, 本文给出四个类型的数据集:
- 农业: CropDiseases2 彩色, 自然图像, 有自身的特点 (相似度 ❤❤❤❤)
- 卫星图: EuroSAT3 彩色, 自然图像, 无透视变形 (相似度 ❤❤❤)
- 皮肤病: ISIC20184 彩色, 医学影像, 无透视变形 (相似度 ❤❤)
- X光片: ChextX5 灰度, 医学影像, 无透视变形 (相似度 ❤)
2. 跨域少样本学习
我们定义”域” \(P\) 为输入空间 \(\mathcal{X}\) 和标签空间 \(\mathcal{Y}\) 的联合分布. \(P_{\mathcal{X}}\) 表示边际分布. 令 \((x, y)\) 表示 \(P\) 中的一个样本 \(x\) 和对应的标签 \(y\) . 那么对于模型 \(f_{\theta}:\mathcal{X}\rightarrow\mathcal{Y}\) 和损失函数 \(l\) , 期望误差为
\[\epsilon(f_{\theta})=E_{(x, y)\sim P}[l(f_{\theta}(x), y)].\]在 CS-FSL 中, 我们有源域 \($(\mathcal{X}_s, \mathcal{Y}_s)\)$ 和目标域 \($(\mathcal{X}_t, \mathcal{Y}_t)\)$ 以及对应的联合分布 \($P_s\)$ 和 \($P_t\)$ , 并且 \($P_{\mathcal{X_s}}\neq P_{\mathcal{X}_t}\)$ .
base 类的数据从源域采样, novel 类的数据从目标域采样.
- 训练时, 模型在 base 类数据上训练.
- 测试时, 模型在 novel 类数据上测试. 其中会提供支撑集(support set) \(S=\{x_i, y_i\}_{i=1}^{K\times N}\), 其中包含 \(K\) 和类别, 每个类别 \(N\) 个带标签的样本, 称为 K-way N-shot 的少样本学习. 在模型适应到支撑集后使用查询集(query set)测试.
3. 研究方法
3.1 元学习 Meta-Learning
以 task 的形式训练模型. 每个 task 从固定的分布中抽取 \(\mathcal{T}_i\sim P(\mathcal{T})\) . 比如, 在 FSL 中, 每个 task 都是一个小型数据集 \(D_i:=\{x_j,y_j\}_{j=1}^{K\times N}\) . 使用 \(P_s(\mathcal{T})\) 和 \(P_t(\mathcal{T})\) 分别表示源域和目标域上的 task.
meta-training 阶段: 模型在 \(T\) 个 task \(\{\mathcal{T}_i\}_{i=1}^T\) 上训练, 这 \(T\) 个 采样于 \(P_s(\mathcal{T})\) .
meta-testing 阶段: 希望模型可以快速适应于新的 task \(T_j\sim P_t(\mathcal{T})\) .
在 meta-learning 中潜在的存在这样的假设: \(P_s(\mathcal{T})=P_t(\mathcal{T})\), 这也是在跨域的时候表现差的原因.
3.2 迁移学习 Transfer Learning
初始模型 \(f_{\theta}\) 在 base 类上用标准的监督学习的方法训练, 然后在 novel 类上重用. 已有的用于 FSL 的方法:
- 固定 \(f_{\theta}\) 的参数, 仅用作特征提取器, 在 novel 类上 fine-tune. 但在少样本的情况下及其容易过拟合.
3.2.1 单模型方法
特征层:
- 固定的特征提取器 (Fixed): 不更新模型
- Fine-tune: 用 novel 类的支撑集更新整个模型
- Fine-tune 最后 k 层 (Ft last-k): 仅用 novel 类的支撑集更新最后 k 层, k 取 1, 2, 3
- Transductive(传导性的) fine-tune (Transductive Ft): novel 类查询图片的 统计值通过 BN 来使用.
分类器:
-
Linear classifier
-
Mean-centroid classifier (基于原型6的方法)
-
Cosine-similarity based classifier (直接学习原型1) \(c_{i,k}=\frac{f_{\theta}(\hat{x}_i)^T\mathbf{w}_k}{\Vert f_{\theta}(\hat{x}_i)^T\Vert\Vert\mathbf{w}_k\Vert}\) 其中 \(\mathbf{W}_k\) 为代表第 k 个类别向量, 可以看作原型, 但是是通过反向传播学出来的.
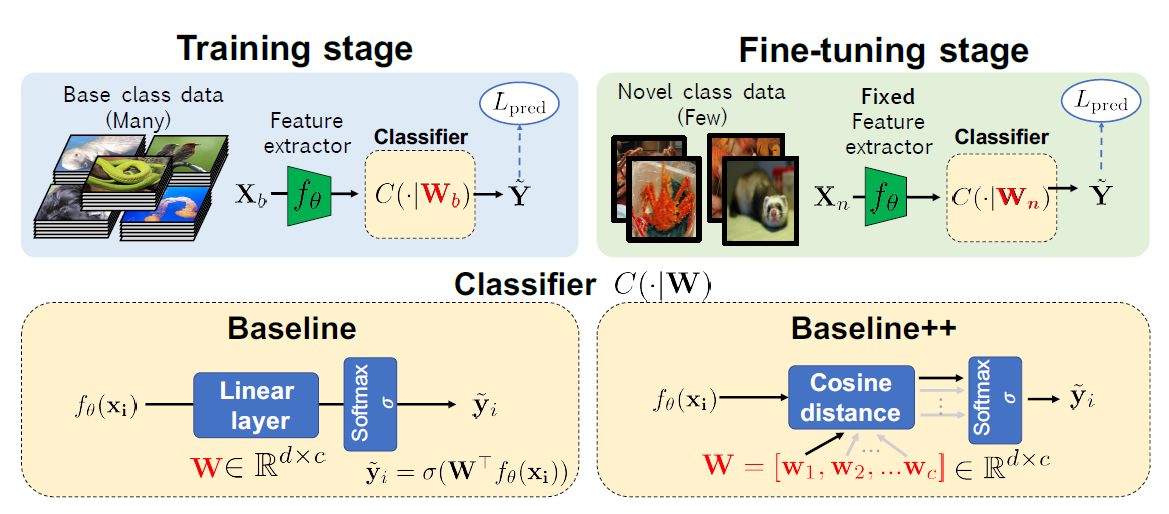
图 2. 元学习分类器
3.2.2 多模型方法 (论文提出的方法)
假设我们有 \(C\) 个分别在不同数据集上预训练的模型 \(\{M_c\}_{c=1}^C\) , 记所有预训练模型的所有网络层为 \(F\), 给定支撑集 \(S=\{(x_i, y_i)\}_{i=1}^{K\times N}\) 其中 \((x_i, y_i)\sim P_t\) , 我们的目标是寻找 \(F\) 的子集 \(I\) 来产生特征向量使得测试误差最小:
\[\underset{I\subseteq F,\;(x, y)\sim P_t}{\arg\min}l(f_s(T(\{a(x):a \in I\})), y)\]其中 \(T(\cdot)\) 是结合一组特征向量的函数, \(a\) 是 \(I\) 中的网络层, \(f_s\) 是线性分类器.
\(I\) 的筛选方法:
- 每一个预训练模型的每一层都训练一个分类器, 然后每个模型最好的层加入 \(I_1\)
- 把 \(I_1\) 中的层累进式地加入 \(I\), 可以降低误差则保留, 否则丢弃
4. 实验
4.1 四个数据集 + 三种训练方法 + 三种分类器
- 元学习
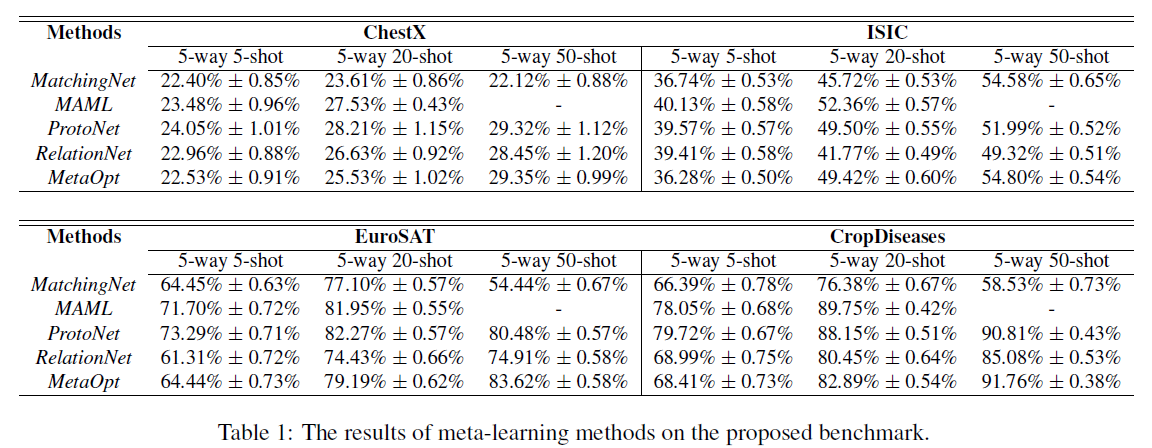
图 3. 元学习实验
- 单模型迁移
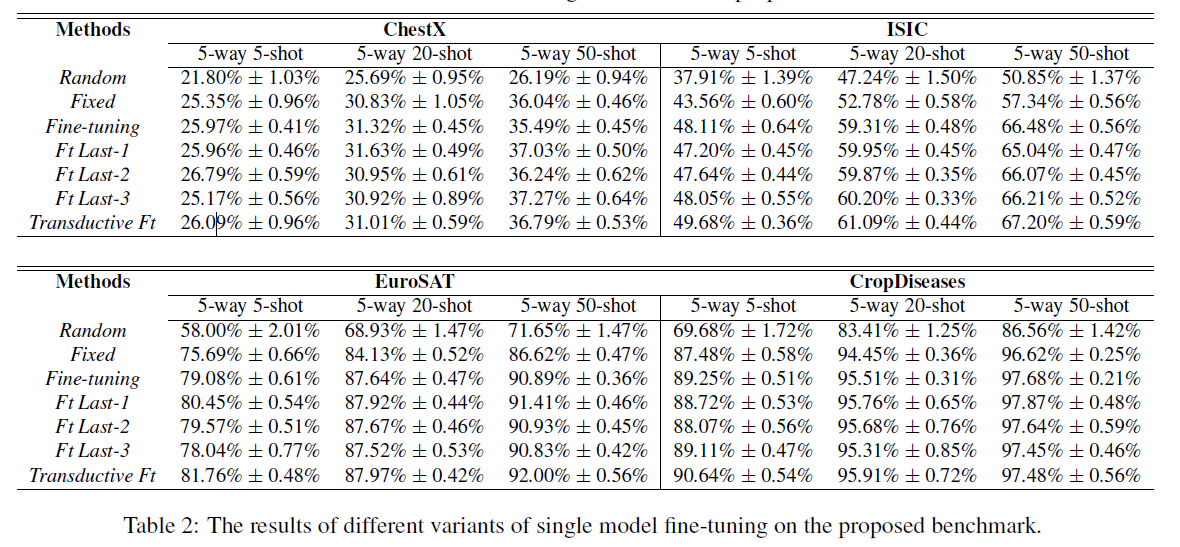
图 4. 单模型迁移实验
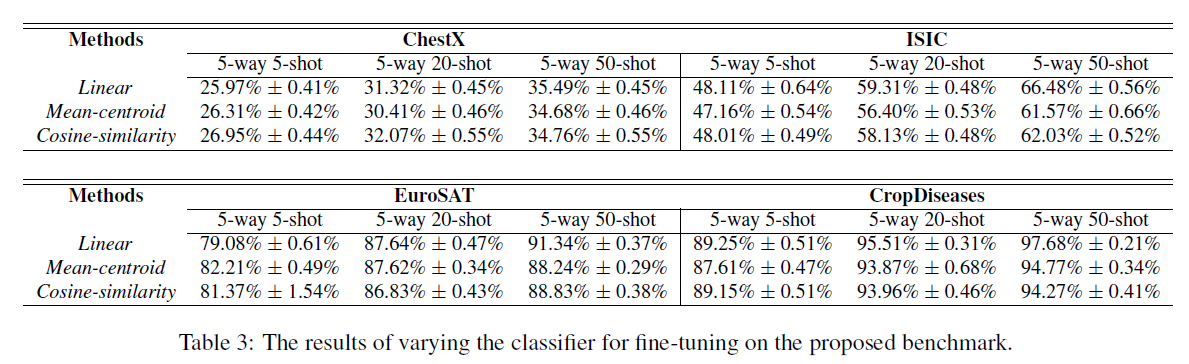
图 5. 单模型迁移实验 分类器
- 多模型迁移
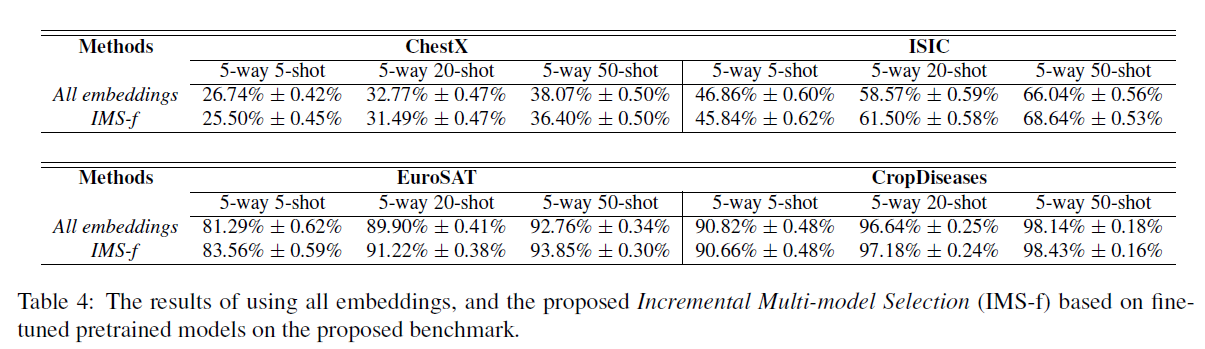
图 6. 多模型迁移实验
4.2 单模型迁移方法, 微调对参数的影响
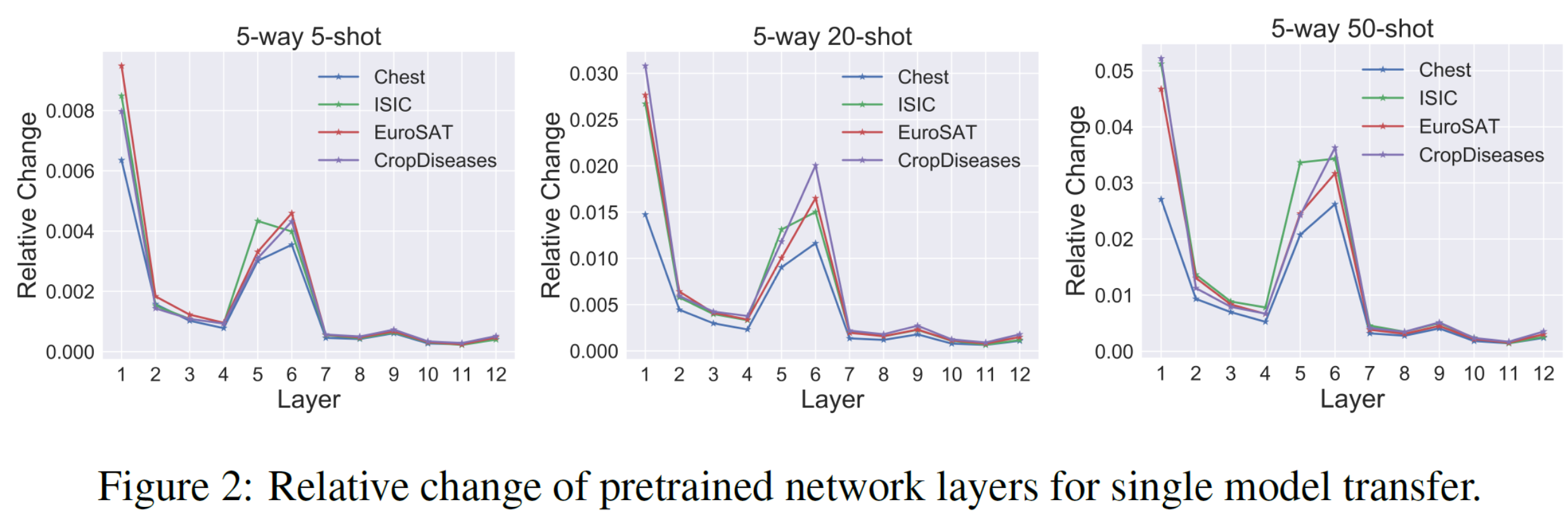
图 7. 不同层对参数重新初始化的敏感性
- 第一层的参数变化最大: 说明跨域学习所需要的低级特征是相当不同的
- 有一些层的参数变化很小
对此的解释是模型内层的异质性特点(heterogeneous characteristic)7 , 即网络层是可以分为 ambient(周围的) 和 critical(关键的) 两类的, 即层的鲁棒性:
- 重置 ambient 层的参数对模型几乎没有影响
- 充值 critical 层的参数让模型几乎失去预测能力(变成随机输出)
4.3 多模型迁移方法, 预训练模型的选择性
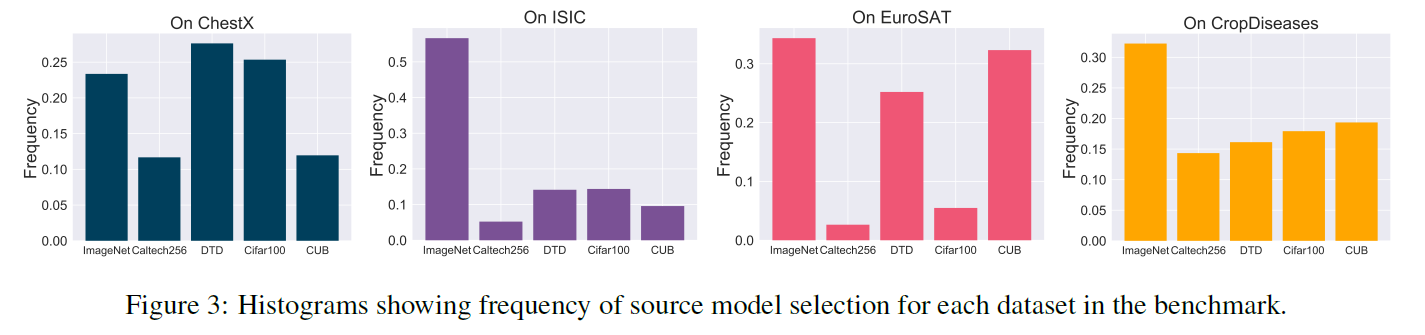
图 8. 预训练模型对不同数据集的影响
使用前面提到的模型选择的方法重复每个实验600个episodes, 并统计模型被选择的频率.
- 不同数据集对预训练模型是有倾向性的
References
-
A closer look at few-shot classification
Wei-Yu Chen, Yen-Cheng Liu, Zsolt Kira et al.
[link]. In ICLR 2019 ↩ ↩2 -
Using deep learning for image-based plant disease detection
Sharada P Mohanty, David P Hughes, and Marcel Salathe
[link]. In Frontiers in plant science, 7:1419, 2016. ↩ -
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification
Patrick Helber, Benjamin Bischke, Andreas Dengel et al
[link]. In IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(7):2217–2226, 2019. ↩ -
The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions
Philipp Tschandl, Cliff Rosendahl, and Harald Kittler
[link]. In Scientific data, 5:180161, 2018. ↩ -
ChestX-Ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases
Xiaosong Wang, Yifan Peng, Le Lu et al
[link]. In CVPR 2017 ↩ -
Prototypical Networks for Few-shot Learning
Jake Snell, Kevin Swersky, Richard Zemel
[link]. In NeurIPS 2017 ↩ -
Are All Layers Created Equal?
Chiyuan Zhang, Samy Bengio, Yoram Singer
[link]. In Arxiv 1902.01996 ↩