深度神经网络在大数据上取得了骄人的成绩, 但在仅有少量样本时表现得不尽如人意. 为了解决该问题, 小样本学习(Few-Shot Learning, FSL)被越来越多的研究者所关注. FSL 可以在十分有限的监督信息(带标注的样本)下, 充分利用先验信息来提升模型的表现. 本文对 FSL 的做一个综述, 并指出了 FSL 方法要解决的核心问题是不可靠的经验风险最小化. 基于先验信息如何被用于解决该核心问题, FSL 方法可以划分为三种类型:
- 数据增广
- 缩小模型的假设空间
- 设计更好的优化算法
1. 引言
为了能够从有限的监督信息中学习模型, 人们提出了小样本学习(Few-Shot Learning, FSL)的概念1, 一旦某些类别已经被模型学到, 那么这个学习的过程中就会有信息被抽象出来, 使得该模型对其他类别的学习更有效. 当只有一个样本有监督信息时, FSL 也成为单样本学习(One-Shot Learning). FSL 可以通过结合先验信息从少量样本中学习新的任务.
FSL 有许多使用场景. (1) 用于测试 AI 程序是否能像人那样做出决策. (2) 帮助工业界减轻收集大规模训练数据的负担, 比如 ResNet2 在 1000 类图像分类数据集上获得了人类水平的表现, 但该数据集包含了百万张图像及标注. (3) 因为某些原因, 数据集的监督信息难以获得的情况, 如医学图像的标注需要专家进行, 药品研发的过程中可能产生毒性等等. 这些因素使得收集大量的有标注数据时困难的.
本文主要内容来自以下文献:
- Few-Shot Learning Survey3
2. 基本概念
考虑有监督的学习任务 \(T\) , FSL 处理的数据集 \(D=\{D^{train}, D^{test}\}\) 中, \(D^{train}=\{(x^{(i)}, y^{(i)})\}_{i=1}^I\) 为训练集, 且 \(I\) 是很小的整数, \(D^{test}=\{x^{test}\}\) 为测试集. 通常, 我们考虑 N-way-K-shot 分类任务时, \(D^{train}\) 包含来自于 \(N\) 个类别, 每类 \(K\) 个共 \(I=KN\) 个样本. 令 \(p(x, y)\) 表示输入 \(x\) 和标签 \(y\) 的联合分布, \(\hat{h}\) 为从 \(x\) 映射到 \(y\) 的最优假设(即模型). FSL 即是要在训练集 \(D^{train}\) 上学习一个假设 \(\hat{h}\) , 并在测试集上评估假设的好坏. 通常根据先验知识我们可以选择一个假设空间 \(\mathcal{H}\) 来缩小寻找最优假设的范围, 同时把假设参数化以便于优化 \(h(\cdot;\theta)\) , 参数为 \(\theta\) . 优化算法则负责在 \(\mathcal{H}\) 中搜索对于 \(D^{train}\) 最优的 \(\theta\) . 通过模型的预测值 \(\hat{y}=h(x;\theta)\) 和真实结果 \(y\) 之间的损失函数 \(l(\hat{y}, y)\) 来衡量算法和模型的表现.
2.1 问题定义
FSL 是机器学习的一个子领域, 因此我们首先回顾机器学习的定义.
Definition 1. (Machine Learning4) A computer program is said to learn from experience \(E\) with respect to some classes of task \(T\) and performance measure \(P\) if its performance can improve with \(E\) on \(T\) measured by \(P\) .
所以一个机器学习问题由 \(E, T, P\) 三部分组成. 比如 (1) 图像识别任务(\(T\)), 我们希望得到高的分类准确率(\(P\)), 而训练模型使用的是大规模图像数据集(\(E\)) 如 ImageNet. (2) AlphaGo程序执行的下围棋的任务(\(T\)), 其目标是高胜率(\(P\)), 训练模型使用的是数千万场人类专家的下棋记录和大规模的自我博弈(\(E\)).
FSL 是一种特殊的机器学习任务, 这类任务只能使用少量的监督信息构成训练数据集. FSL 的定义如下:
Definition 2. (Few-Shot Learning) A type of machine learning problem(specified by \(E, T\) and \(P\)) where \(E\) contains a little supervised information for the target \(T\).
2.2 相关问题
为了更好的了解 FSL, 这一小节列举一些和 FSL 相关的问题类别做比较.
- 半监督学习(Semi-supervised Learning) 是同时从有标注和无标注的数据中学习最优假设 \(\hat{h}\) . 正样本半监督学习(Positive-unlabeled learning) 是一类特殊的半监督学习, 只有正样本和无标注样本可以使用. 主动学习(active learning) 则由算法选择可以提供有用信息(informative)的无标注数据由专家给出标注, 反馈给模型学习. 所以 FSL 既可以是监督学习, 也可以是半监督学习, 取决于从有限的监督信息中可以获得哪种数据.
- 不平衡学习(Imbalance Learning) 从类别 \(y\) 的分布严重倾斜的数据集中学习. FSL 任务中每类数据本来就很少.
- 迁移学习(Transfer Learning) 是把知识从数据量丰富的源域迁移到数据量不足的目标域. 领域自适应(domain adaption) 就是一种迁移学习问题. 另一种相关的迁移学习叫零样本学习(zero-shot learning), 它需要在已有类别中学习特征, 并根据已有特征的组合来判断新的从未见过的类别. 根据 FSL 的定义, FSL 不一定是迁移学习, 但当我们使用额外监督信息来提升目标数据集的表现时, 这本质上就是一种迁移学习, 只不过源域中的数据可能也不多.
- 元学习(Meta Learning)/学会学习(Learning to Learn) 通过提供的数据集和元学习器(meta-learner)从其他地方学到的知识在新的任务 \(T\) 上提升表现 \(P\) . 具体来说, 元学习器在许多任务中学习元信息(一般知识), 并能够使用任务相关的信息快速泛化到新的任务上. 许多 FSL 都是元学习方法, 使用元学习器作为先验信息.
2.3 核心问题
这一部分我们通过公式推导来看一下要解决 FSL 的问题, 应该从哪些方面着手.
通常机器学习中监督学习任务的目标函数写为:
\[\min_{\theta}\sum_{(x^{(u)}, y^{(i)})\in D^{train}}l(h(x^{(i)};\theta), y),\]其中 \(l\) 表示损失函数, \(h\in\mathcal{H}\) 表示假设(即模型), \(\theta\) 为模型参数. 学习算法试图寻找最优的 \(\theta\) 来最小化该目标函数.
2.3.1 经验风险最小化
如果已经给定假设空间 \(\mathcal{H}\) ,任务 \(T\), 和数据分布 \(p(x, y)\), 那么我们当然希望选择最好的假设以最小化期望风险(expected risk) \(R\) , 定义为:
\[R(h)=\int l(h(x), y)dp(x, y)=\mathbb{E}[l(h(x), y)].\]不幸的是绝大部分情况下我们并不知道数据分布 \(p(x, y)\), 我们往往只能获得一些数据样本 \(D^{train}=\{(x^{(i)}, y^{(i)})\}_i^I\) , 所以我们在这些数据独立同分布(i.i.d.)的假设下, 使用经验风险(empirical risk) \(R_I\) 来估计期望风险 \(R\). 经验风险定义为数据集 \(D^{train}\) 上 \(I\) 个样本损失的平均值:
\[R_I(h)=\frac1n\sum_{i=1}^Il(h(x^{(i)}), y),\]而学习过程通过经验风险最小化(Empirical Risk Minimization, ERM)来完成.
下面我们对误差进行分解, 首先给出三种最优解的定义:
- \(\hat{h}=\arg\min_fR(h)\), 表示 \(\hat{h}\) 是 \(R\) 的全局最优解
- \(h^\*=\arg\min_{h\in\mathcal{H}}R(h)\), 表示 \(h^*\) 是 \(R\) 在假设空间 \(\mathcal{H}\) 中的最优解
- \(h_I=\arg\min_{h\in\mathcal{H}}R_I(h)\), 表示 \(h_I\) 是 \(R_I\) 在假设空间 \(\mathcal{H}\) 中的最优解
为了简便, 假设三种最优解都是唯一的. 对于随机的一个训练集, 某个学习任务上训练出来的模型的总误差可以表示为:
\[\mathbb{E}[R(h_I)-R(\hat{h})]=\underbrace{\mathbb{E}[R(h^*)-R(\hat{h})]}_{\displaystyle\mathcal{E}_{app}(\mathcal{H})}+\underbrace{\mathbb{E}[R(h_I)-R(h^*)]}_{\displaystyle\mathcal{E}_{est}(\mathcal{H, I})},\]其中近似误差 \(\mathcal{E}_{app}(\mathcal{H})\) 衡量的是设置假设空间导致的误差, 即为模型误差; 而估计误差 \(\mathcal{E}_{est}(\mathcal{H, I})\) 则衡量的是使用经验误差代替期望误差产生的影响. 注意上述公式中没有优化算法的误差, 即我们暂且认为优化算法均能找到当前约束条件下的全局最优解.
总结下来可以发现影响总误差的由三个因素 (1) 假设空间 \(\mathcal{H}\) 的选择是否合理, 能否包含全局最优解, 我们称之为模型因素 (2) 数据集 \(D^{train}\) 及其大小 \(I\), 称之为数据因素 (3) 优化算法能否找到当前条件下的全局最优解, 称之为算法因素.
2.3.2 不可靠的经验风险最小化
注意到数据因素导致的估计误差随着数据集的增大可以收敛到 \(0\) (如何证明?):
\[\lim_{I\rightarrow\infty}\mathcal{E}_{est}(\mathcal{H, I})=\lim_{I\rightarrow\infty}\mathbb{E}[R(h_I)-R(h^*)]=0,\]这意味着数据集越大, 可以尽可能地降低估计误差的影响. 但这恰恰是 FSL 的短板——缺乏数据. 这使得 \(R_I(h)\) 对与 \(R(h^*)\) 的估计非常不准确, 这是 FSL 的核心问题: 经验风险最小值点 \(h_I\) 变得不可靠. 因此 FSL 比常规的学习任务变得更难. 下图很直观的表现了这种差别.

图 1. 大数据集和小数据集上的误差
2.3.3 FSL 方法的分类
FSL 必须使用先验信息来辅助任务的解决, 因此根据先验信息的不同使用方法可以分为三类:
| 因素/类别 | 先验信息使用 |
|---|---|
| 数据 | 使用先验信息增广数据集 \(D^{train}\) 从 \(I\) 个样本到 \(\tilde{I}\) 个样本 , 从而提高经验风险最小值点的准确性 |
| 模型 | 基于先验信息约束假设空间 \(\mathcal{H}\) 到更小的范围 |
| 算法 | 利用先验信息搜索出假设空间中使得假设 \(h^*\) 最优的参数 \(\theta\) |
三类先验信息的使用效果可以由以下示意图来反映:
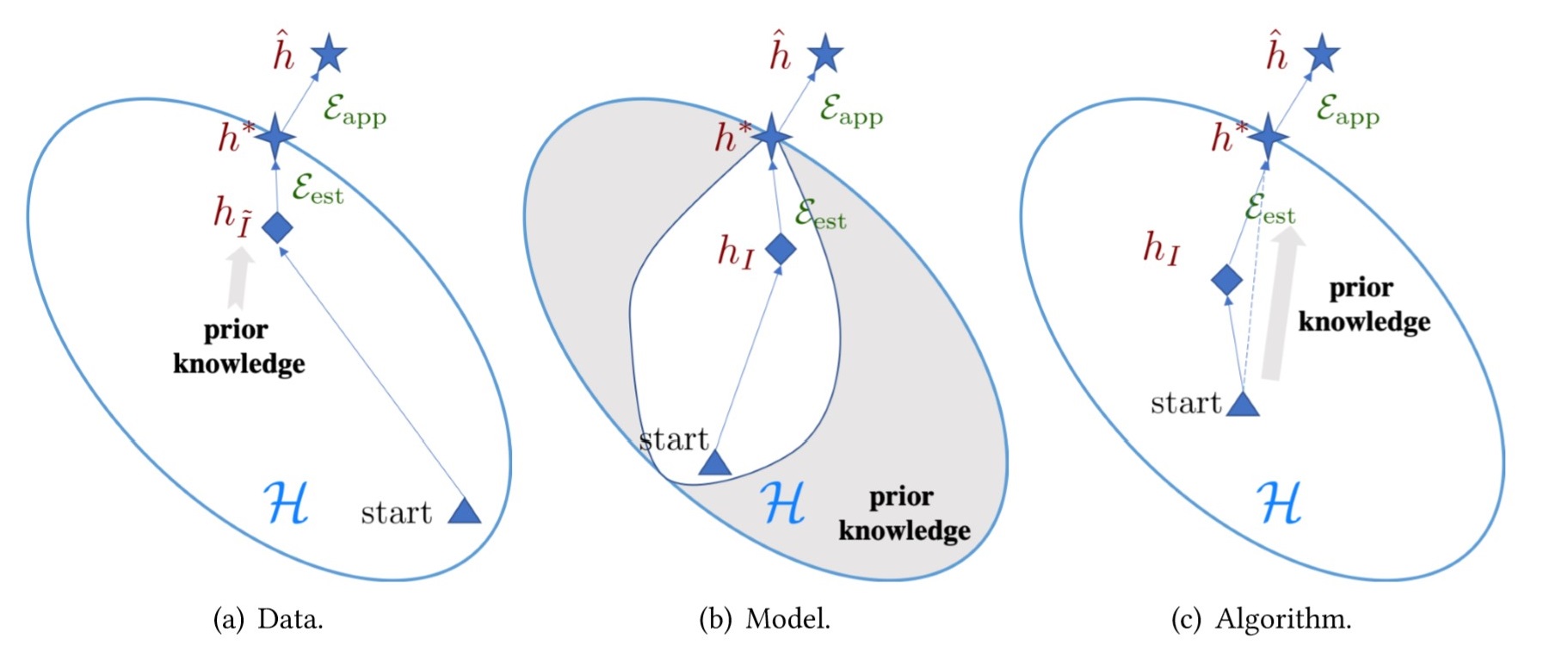
图 2. FSL 方法从数据(左), 模型(中)和算法(右)三个方面来减小误差. 图(a)中数据集被增广到 $$ \tilde{I} $$ , 因此得到更大的数据集使得 ERM 可以得到更可靠的假设 $$ h_{\tilde{I}} $$ . 图(b)中的假设空间被先验信息约束到了更小的范围. 图(c)中根据先验信息优化策略有所改变.
3. 基于数据的方法
3.1 训练集 \(D^{train}\) 数据增广
3.1.1 人工规则
基于人工规则的数据增广方法通常包括:
- 平移 (translating)
- 翻转 (flipping)
- 错切 (shearing)
- 缩放 (scaling)
- 镜像 (reflecting)
- 裁剪 (cropping)
- 旋转 (rotating)
- 加噪 (noising)
- 亮度 (birghtness)
- 对比度 (contrast)
- 饱和度 (saturation)
(注: 后期增加各类框架的API)
3.1.2 学习数据变换
基于学习的数据增广方法是含参的增广方法, 先验信息嵌入到增广模型的参数中.
3.2 结合其他数据集的增广
4. 基于模型的方法
基于模型的方法又可以从建模策略分为四类:
| 策略 | 先验信息 | 如何约束参数空间 \(\mathcal{H}\) |
|---|---|---|
| multitask learning | 其他任务 \(T\) 及相应的数据集 \(D\) | 参数共享 |
| embedding learning | 从/和其他任务 \(T\) 学到的嵌入 | 特征降维, 在低维嵌入空间中分类 |
| learning with external memory | 从其他任务 \(T\) 学到的嵌入与记忆交互 | |
| generative modeling | 从其他任务学到的先验模型 | 限制分布的形式 |
4.1 多任务学习 Multitask Learning
多任务学习同时学习多个任务, 利用多任务的共同信息和每个人物的特有信息进行学习. 因此适用于 FSL. 当多任务学习处理不同域的数据集时, 也成为域适应 (domain adaption). 多任务学习的多个任务的假设空间存在较强的关联, 这种关联可以通过共享参数来表示. 根据是否显式地约束参数空间, 多任务学习可以分为:
- 硬 (Hard) 参数共享
- 软 (Soft) 参数共享 软共享不进行参数的强约束, 只鼓励不同任务的参数尽可能满足某种条件 (比如使用正则化函数 \(L_1, L_2\) 约束不同任务参数的距离). 因此多任务参数软共享时, 不同任务仍然具有不同的假设空间和参数.
4.2 嵌入学习 (Embedding Learning)
嵌入 (embedding) 在机器学习中通常表示数据点 \(x_i\in\mathcal{X}\subset\mathbb{R}^d\) 在一个低维特征空间中的特征映射 \(z_i\in\mathcal{Z}\subset\mathbb{R}^m,~m < d\), 通常表示为一个向量. 嵌入学习则是考虑如何训练嵌入模型使得在特征空间中的各数据点的嵌入仍然保持原始的相似和不相似的关系. 嵌入函数的参数则需要从先验知识中学习, 并且可以考虑把任务有关 (task-specific) 的信息引入嵌入函数的参数中. 嵌入函数主要用于分类任务.
嵌入学习分类的依据是嵌入的相似性, 即计算测试数据 \(x^{test}\in D^{test}\) 和训练数据 \(x_i\in D^{train}\) 之间的相似性, 从而把相似度最高的那个训练样本的标签赋给测试数据. 嵌入学习有如下几个重要的组成部分:
- 测试数据的嵌入函数 \(f(\cdot)\)
- 训练样本的嵌入函数 \(g(\cdot)\)
- 度量 \(s(\cdot, \cdot)\)
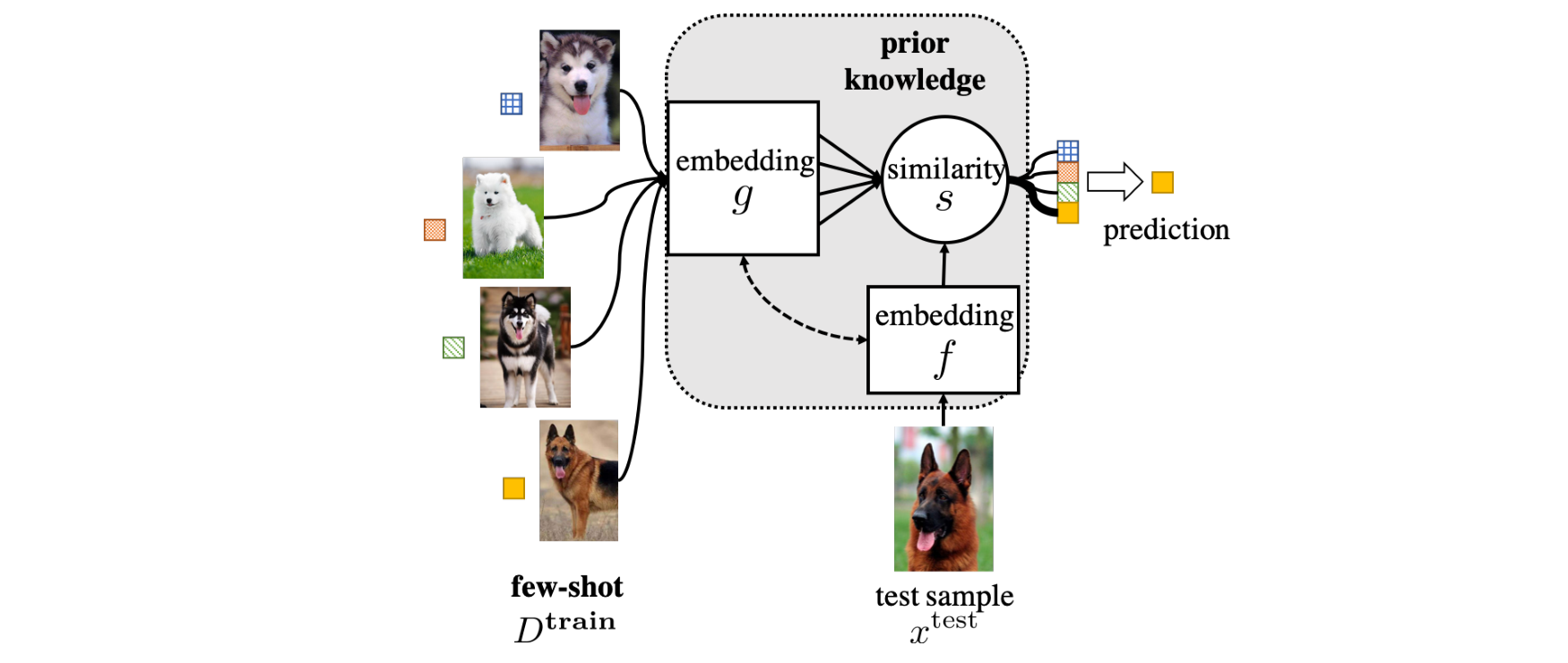
图 3. FSL 问题的嵌入学习图示
最简单的一种思路就是在训练集上训练模型, 在测试集上测试. 但在小样本的前提下这样训练模型势必导致严重的过拟合. 因此在 FSL 中通常训练任务无关 (task-invariant) 的模型, 再泛化到测试集的类别上, 即元学习 (meta-learning) 的思路. 因此在这种思路下嵌入函数从其他任务中学习先验知识, 而嵌入函数的参数中不明显包含任务有关的信息, 即我们一般不会在少样本的训练集上训练模型的参数(尤其是在 \(D^{train}\) 特别小的时候, 如每类仅有一个有标签样本). 下文为了清晰, 我们把测试集上带标签的少样本数据集称为支撑集 (support sets), 表示为 \(x_i\in D^{sup}\), 把用于训练任务无关模型的大规模数据集称为训练集, 该大规模训练集中包含标签, 但不包含测试集中的类别.
-
Matching Network 通过计算 \(f(x^{test})\) 和一系列 \(g(x_i), x_i\in D^{sup}\) 的相似度来对 \(x^{test}\) 进行分类, 其中 \(f(\cdot)\) 依赖于 \(D^{train}\) 而 \(g(\cdot)\) 使用双向 LSTM (biLSTM) 聚合了 \(D^{sup}\) 中所有样本的信息. 在 Matching Nets 中两个嵌入函数为不同的模型, 度量使用了余弦相似度 (cosine similarity).
-
Prototypical Network 对支撑集中每一类的样本计算一个原型 (prototype, \(c\)) 用来代表该类别的嵌入. 原型用该类别中有标签样本的嵌入的平均值表示, 即
\[c_n = \frac1K\sum_{k=1}^K g(x_k^{(n)}),\]其中 \(n\) 表示第 \(n\) 个类别. 在 Prototypical Nets 中, 两个嵌入函数使用了相同的模型, 度量使用了 \(L_2\) 距离.
-
Relative Representations 进一步使用模型来学习度量. 如 Relation Network 使用 CNN 首先把数据映射到嵌入空间, 然后把测试数据和支撑数据的嵌入并起来, 通过另一个神经网路预测相似度值.
-
Relation Graph 把支撑集和测试集的样本点作为图节点, 边权则通过学习得到. 测试集的分类任务利用邻近节点的信息进行预测.
4.3 外部记忆学习 (Learning with External Memory)
- 记忆检索相关的信息
- 计算相似度
- 记忆可以被更新
如下图所示.
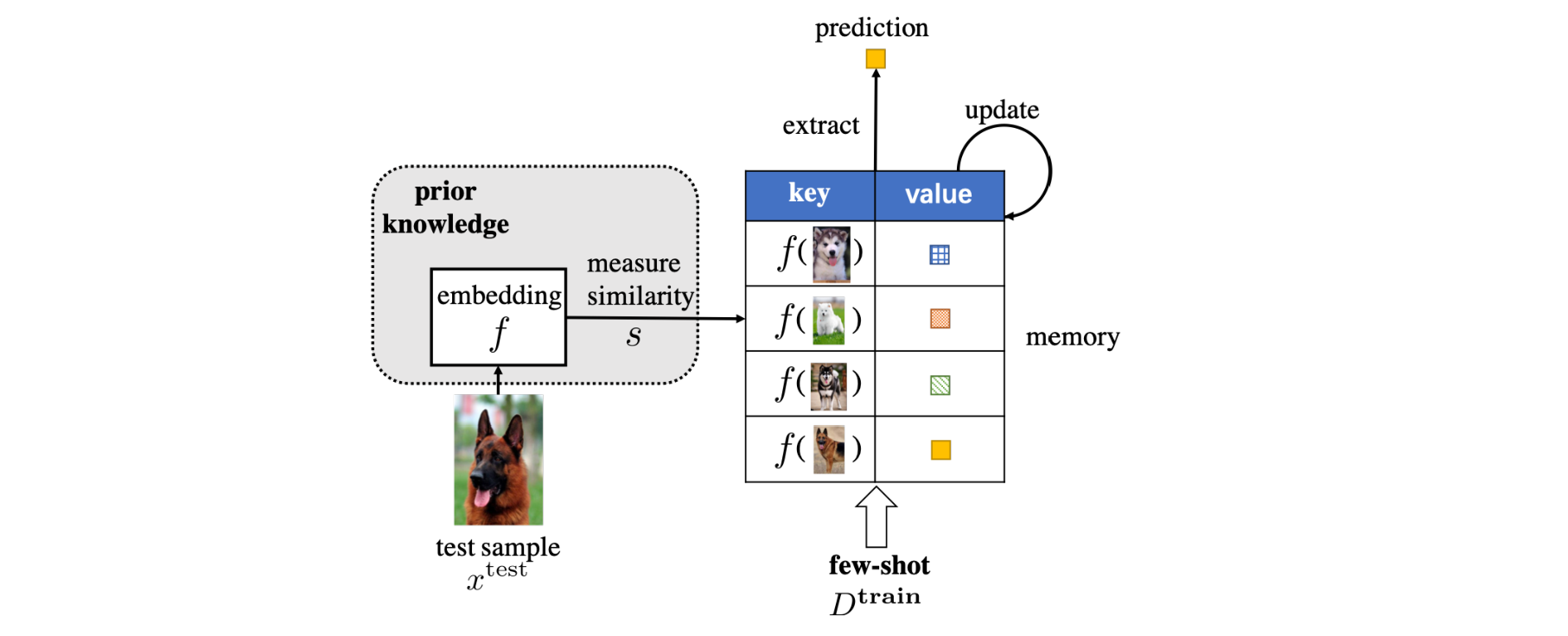
图 4. FSL 问题的嵌入学习图示
4.4 生成式建模 (Generative Modeling)
5. 算法 (Algorithm)
略
参考文献
-
One-Shot Learning of Object Categories
Li Fei-Fei, R. Fergus, and P. Perona.
[link]. In IEEE Transactions on Pattern Analysis and Machine Intelligence 28 (4): 594–611. 2006. ↩ -
Deep Residual Learning for Image Recognition
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
[link]. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–78. 2016. ↩ -
Generalizing from a Few Examples: A Survey on Few-Shot Learning
Wang, Yaqing, Quanming Yao, James Kwok, and Lionel M. Ni.
[link] In ArXiv:1904.05046 [Cs], April. 2019. ↩ -
Fine-grained visual categorization using meta-learning optimization with sample selection of auxiliary data
Yabin Zhang, Hui Tang, Kui Jia
[link] In ECCV. 2018: 233-248. ↩ -
One-shot Adversirial Domain Adaptation
Saeid Motiian, Quinn Jones, Seyed Mehdi Iranmanesh,Gianfranco Doretto
[link] In NIPS 2017: 6670-6680. ↩ -
One-shot unsupervised cross domain translation
Sagie Benaim, Lior Wolf
[link] In NIPS 2018: 2104-2114. ↩