论文题目: Focal Loss for Dense Object Detection
作者: Tsung-Yi Lin Priya Goyal Ross Girshick Kaiming He Piotr Dollar
研究机构: Facebook AI Research
时间: 2017.08.07
1. Introduction
目前基于深度学习的物体检测器主要分类两大类:
- 一阶段检测器
- YOLO 系列
- SSD 系列
- 两阶段检测器
- R-CNN 系列
- FPN
而物体检测速度和精度的现状是一阶段检测器速度快精度低, 两阶段检测器速度慢精度高. 本文在原始常用的基于交叉熵损失函数的基础上增加了一个因子 \((1-p_t)^{\gamma}\) 来让网络更专注于分类效果不好的样本, 这样可以有效地避免类别不平衡导致的训练倾斜问题, 从而不仅提高了网络的收敛速度, 同时也提高了最终的验证精度.
在一阶段检测器中通常每张图片会产生大约 100k 的候选目标, 而通常仍然使用 bootstraping、hard example mining (HEM) 来选择训练样本, 这样就会导致训练过程很大程度上被负样本主宰.
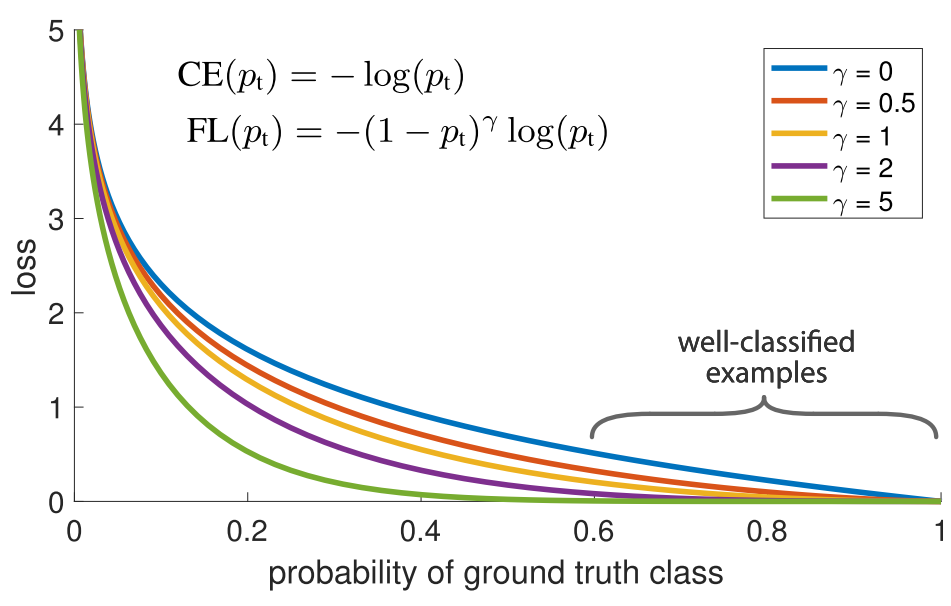
图 1: Cross Entropy 和 Focal Loss
图 1 中展示了 Focal Loss 对于不同概率样本的损失因子, 其中最上面蓝色 \(\gamma=0\) 的曲线为普通的交叉熵 (cross entropy, CE), 可以看出虽然在 \(p>0.5\) 的区域损失不是很大, 但是当有大量的被分类正确的简单样本出现时这些损失之和也会变得非常大, 并且很容易超过分类错误造成的损失. 下面的四条曲线为不同的缩放因子 \(\gamma=0.5, 1, 2, 5\) 对应的 Focal Loss (FL) 损失函数的图像, 容易看出使用 Focal Loss 可以让分类正确的样本对损失贡献减少, 而分类错误的样本对损失有很大的贡献.
2. Focal Loss
首先考虑二分类任务的交叉熵损失函数:
\[CE(p, y) = \left\{\begin{array}{ll}-\log(p) & \text{if}~y=1, \\ -\log(1-p) & \text{otherwise}. \end{array}\right.\]其中 \(y\in\{\pm1\}\) 指 ground truth 类别, \(p\in[0, 1]\) 是模型预测类别 \(y=1\) 的概率. 为了表示简单, 定义记号
\[p_t = \left\{\begin{array}{ll}p & \text{if}~y=1, \\ 1-p & \text{otherwise}.\end{array}\right.\]这样可以把式 (1) 重写为 \(CE(p, y) = CE(p_t) = -\log(p_t)\) .
2.1 加权交叉熵
用于类别不平衡通用的方法是使用加权交叉熵, 即对类别 \(y=1\) 引入权重因子 \(\alpha\in[0, 1]\) , 对类别 \(y=-1\) 引入权重因子 \(1-\alpha\) . 在实际中 \(\alpha\) 一般被设置为类别比例的倒数或者直接置为超参数 (即人为指定的参数), 列式如下:
\[CE(p_t) = -\alpha_t\log(p_t)\]2.2 Focal Loss 的定义
我们引入一个比例因子 \((1-p_t)^{\gamma}\) , 其中 \(\gamma\) 为超参数, 定义 Focal Loss 如下:
\[FL(p_t) = -(1-p_t)^{\gamma}\log(p_t).\]我们对该函数做如下解释:
- 当一个样本被分类错误时 \(p_t\) 会很小, 这样比例因子会很接近 \(1\) , 从而损失基本上与交叉熵一致; 而当 \(p_t\rightarrow1\) 时比例因子很接近 \(0\) , 从而分类正确的样本的权重遭到削减.
- 聚焦因子 \(\gamma\) 用于调整简单样本权重被削减的程度. 当 \(\gamma=0\) 时, 权重始终不被削减, 当其增加时比例因子的影响力也在增加.
在实践中我们把上面提到的两种方法结合起来可以进一步获得效果的提升:
\[FL(p_t) = -\alpha_t(1-p_t)^{\gamma}\log(p_t).\]2.3 两阶段检测器中的类别不平衡
再来回顾 R-CNN 中类别不平衡的来源. 两阶段检测器中第一阶段 (Selective Search, EdgeBoxes, DeepMask, RPN) 削减了大量无关的背景样本, 最终得到少量的候选物体 (1-2k/image); 在第二阶段从这些候选目标中通过启发式 (heuristic) 的方法选择训练样本, 经典的方法是采样前景背景的比例为 1:3 或者使用 HEM 方法. 给定采样比例其实可以看作隐式的加权交叉熵.
3. RetinaNet 检测器
本文设计了一个简单的网络用来检验 Focal Loss 的效果, 网络结构如图 2 所示.
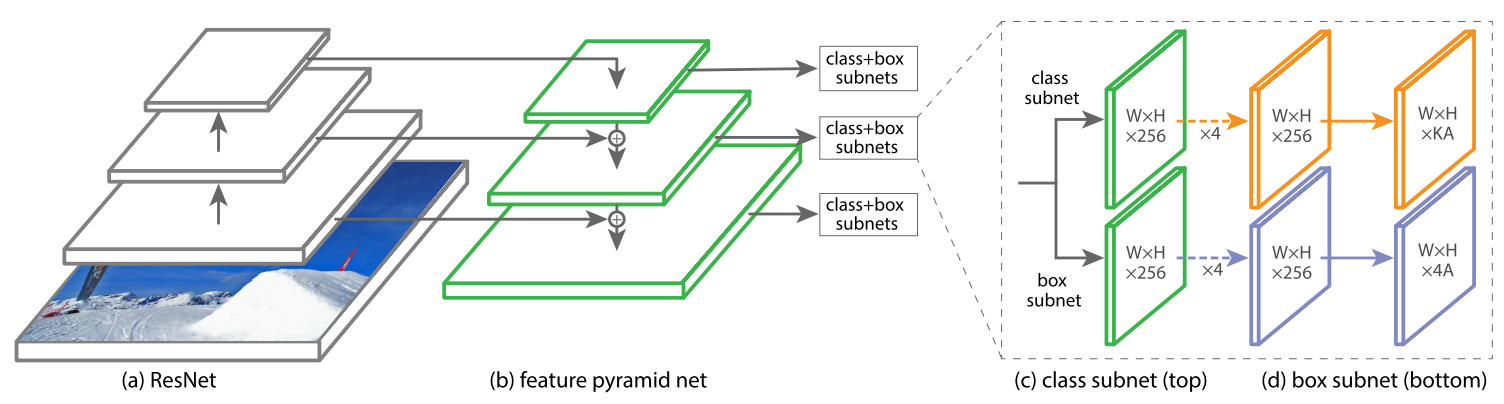
图 2: RetinaNet 网络结构
特征金字塔主干网络
特征金字塔的思想是从多个尺度的特征图中提取 proposals, 本文的特征金字塔是基于 ResNet 的. RetinaNet 使用了特征层 \(P_3\) 到 \(P_7\) , 由于每经过一层特征图的大小会缩小一倍, 所以形成了一个金字塔形. 其中 \(P_3\) 到 \(P_5\) 层均直接来自于 ResNet 的残差块 \(C_3\) 到 \(C_5\) , 剩余的两层均通过步长为 2 的卷积得到. 注意到图 2 (b) 中每一个特征层会把来自上层经过上采样得到的特征图和横向连接得到的特征图加起来作为该层的特征图, 这样的连接方式与 FCN 其实是一样的, 与 FCN 不同的是我们在上采样路径中提取了每一层的输出转入分类和回归子网络:
\[RetinaNet = \underbrace{ResNet+FCN}_{FPN} + \left\{\begin{array}{l}Classification \\ Regression\end{array}\right.\]此处应有插图
Anchors
我们从五个特征层获取 anchors, 这些 anchors 的基准大小依次为 \(base^2 = 32^2, 64^2, 128^2, 256^2, 512^2\) (依次从 \(P_3\) 到 \(P_7\)), 而每种面积 anchor 的形状比例仍然是 \(1:2, 1:1, 2:1\) . 然后解释上面基准的意思, 为了在每一个特征层上也能够获取多尺度的信息, 所以还是在每一层使用了三种面积的 anchor, 面积分别为 \(base\times\{2^0, 2^{1/3}, 2^{2/3}\}\) . 所以每一层可以获得 9 种 anchor, 可以覆盖到 32 ~ 813 大小的区域 (\(813 \approx 512\times2^{2/3}\)). 每一个 anchor 都会被分配一个长度为 K 的 one-hot 的向量 (用于分类) 和一个长度为 4 的向量 (用于 Bbox 回归). 这里使用类似于 RPN 但不全相同的分配规则:
- 当 IoU 超过 0.5 时 anchor 被分配为前景, 在 [0, 0.4) 范围内分配为背景, 其他的忽略.
- 当 anchor 被分为前景时, 把 K 维向量中对应的类别设置为 1, 其他为 0.
分类子网络
分类子网络参看图 2 (c), 本质上是一个小型的 FCN 连接到 FPN 的每一层上, 该子网络的参数在所有的金字塔层上都是共享的, 输出为具有 KA 个通道的特征图, 最后使用 sigmoid 函数完成二分类任务 (前景和背景). 细节之后补充.
回归子网络
回归子网络参看图 2(d), 同样使用一个小型的 FCN 连接到 FPN 的每一层上, 与分类子网络唯一的不同是输出通道数.
4. 其他形式的 Focal Loss
待补充.