作者: Kaiming He, Georgia Gkioxari, Piotr Dollar, Ross Girshick
研究机构: Facebook AI Research
1. Introduction
语义分割 (semantic segmentation) 指的是把一张图像的每一个像素进行分类, 比如把图像中所有的人分为一类. 而实例分割 (instance segmentation) 是指按照对象 (object) 进行分类, 那么不同的人就要分为不同的类别.
本文在 Faster RCNN [3]的基础上, 增加了一个在感兴趣区域 (region of interest, RoI) 上预测分割的 mask 的分支, 如图 1 所示:
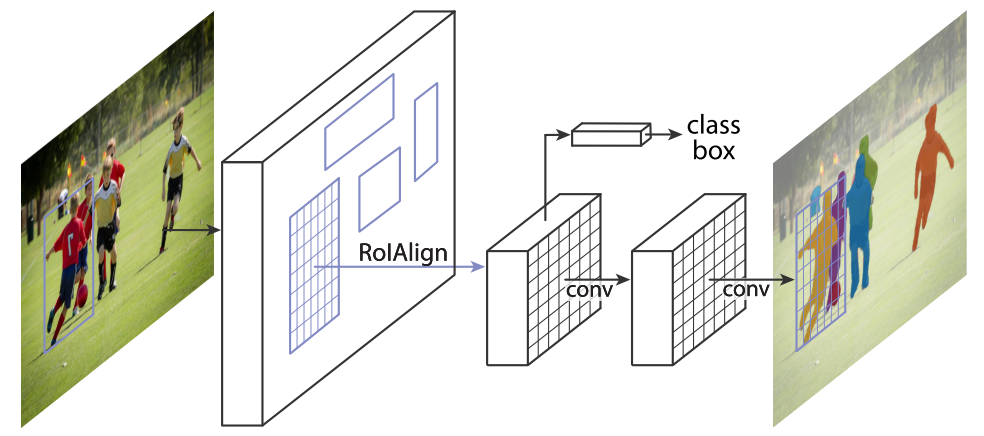
图1. 用于实例分割的 Mask R-CNN 框架.
该分支与原来的分类和 Bounding box (Bbox) 回归任务并行, 称为 Mask RCNN. mask 分支本质上就是把一个小型的 FCN 应用到每一个 RoI 上, 预测一个像素级的分割图. 此外, 实际上 Faster RCNN 在设计时由于使用了 RoIPool, 在特征提取时只能获得比较粗糙的空间信息. 为了充分的保留空间位置信息(也是为了获得更准确的分割图), 作者提出了 RoIAlign 层, 该层有以下几个好处:
- RoIAlign 可以大幅度(10% ~ 50%)提升 mask 的精度
- 作者发现解耦合 (decouple) mask 和类别预测是十分必要的. 解耦合的意思是对于每一个类别单独预测一个二值的 mask (即前景和背景), 这样类别之间不会形成竞争关系, 能够更专心的与背景竞争.
Mask RCNN 好不吹嘘的超过了当前所有实例分割的 state-of-the-art, 然后作者十分谦虚的说作为副产品顺便超过了 COCO [5]物体检测的 state-of-the-art. 最后对 Mask RCNN 做了微调后应用在了 2016 COCO 的人体姿势检测任务上, 结果同样超过了比赛冠军.
2. Mask RCNN
Faster RCNN
Faster RCNN 是一个两阶段的检测器: 第一阶段使用区域建议网络 (region proposal network, RPN) 产生候选的物体边界框, 第二阶段使用 Fast RCNN [4], 通过 RoIPool 提取特征, 最后通过两个全连接层来完成分类和 Bbox 回归任务. 同时 RPN 和 Fast RCNN 通过共享权值来加快训练.
Mask RCNN
Mask RCNN 仍然使用两阶段方法, 在第二阶段添加了 mask 分支, 损失函数为:
\($L = L_{cls} + L_{box} + L_{mask}\)$
其中 \(L_{cls}\) 和 \(L_{box}\) 损失与 Faster RCNN 中的相同; 对 mask 分支的输出应用像素级的 sigmoid 函数 (后面的实验说明这里使用 softmax 函数会使得 AP 掉 5.5 个点, 使用 softmax 就以为只多类别间的 mask 是相互竞争的), 然后使用二值交叉熵函数作为 \(L_{mask}\) 损失. 对于 ground truth 是第 k 类的 RoI, mask 损失只定义在第 k 个 mask 输出上, 其他的 mask 输出不贡献损失. 这样保证了多个类别的 mask 之家不会竞争,
RoIAlign
由于我们要实现像素级的 mask 图像, 所以如果仍然使用 Fast RCNN 中的 RoIPool 的话, 会出现一些误差:
- RPN 输出的 Bbox 的坐标是原始图像上的坐标, 所以我们在第二阶段最后提取的特征图上做 RoIPool 时必须把预选框 (proposals) 在原始图像的坐标转化为特征图上的坐标, 由于 max pool 操作可能存在 padding, 所以直接使用 [x/16] (x 是预选框的坐标, 由于是回归来的, 所以一般是浮点数. VGG16 中 执行了 maxpool 4 次, 所以坐标对应了 16 倍) 这样的方式进行坐标转化存在取整的操作.
- 类似地把特征图上的 RoI 池化为固定大小 (比如 7×7) 的盒子 (bins) 时也可能存在取整操作.
这些取整会使得 RoI 与提取的特征之间存在偏差, 这样小的偏差对分类基本没什么影像, 但是对像素级的分割必然会产生较大的负面影响 (为什么很大呢? 注意到特征图上的 1 个像素的误差会引起原始图像 16 个像素的误差, 如果池化了五次则会导致 32 个像素的误差).
为了解决该问题, 论文提出了 RoIAlign 的方法, 主要包含三点:
- 预选框的大小保持浮点数状态不做取整
- RoI 分割为 7×7 的单元时每个单元的边界不做取整
- 使用双线性内插法 [1] 在每个单元中采样四个固定位置的值进行池化
我们结合图 2 来给出第三点的细节:
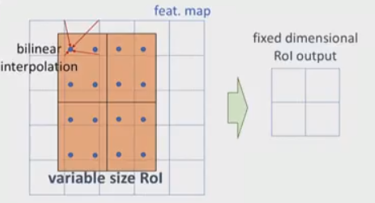
图2. RoIAlign 实现细节.
上面提到每个 RoI 都池化为 7×7 个单元, 在每个单元中选择四个采样点(每个单元分成 2×2 的小矩形, 采样点为小矩形的中心点, 如果采样点数为 1, 那么直接获取中心点的值即可), 通过双线性插值获得这四个点上的值, 然后对这四个值采取池化得到输出. 此外我们需要对 RoIPool 的反向传播公式做一定的修改:
网络结构
本文尝试的网络主干 (backbone) 结构有:
- ResNet-50-C4
- ResNet-101-C4
- ResNeXt-101
- ResNet-50-FPN
- ResNet-101-FPN
注: Faster RCNN 使用 ResNets 的原始实现中从第四阶段的最后一次卷积之后提取特征, 我们称之为 C4. FPN 是指 Feature Pyramid Network [2].
用于分类回归和分割的网络头部 (head) 结构:
- 分类和回归部分保持 Faster RCNN 中的结构不变, ResNet-C4 主干结构中额外添加 ResNet 的第五阶段
- 分割部分使用全卷积作为 mask 预测分支
具体结构参考图 3:
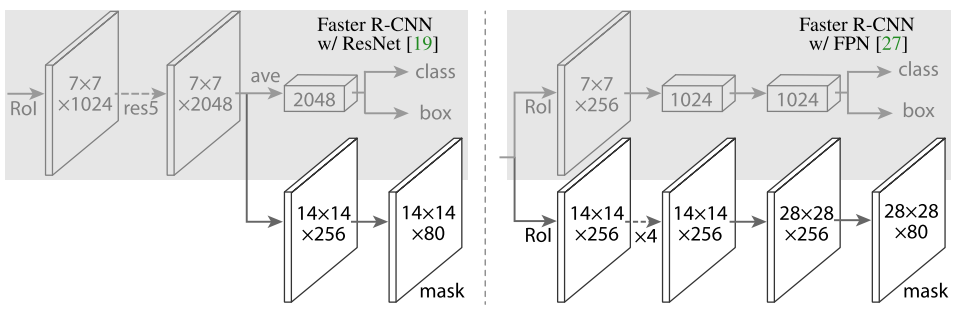
图 3. 头部结构: 数字表示分辨率或通道数, 箭头表示卷积、反卷积、全连接层. 所有的卷积都是 3×3 的, 输出层的卷积除外 (是 1×1 的), 反卷积是 2×2 的, 步长为 2, 使用 ReLU 激活. 左边: 'res5' 表示 ResNet 的第五个阶段, 右边: '×4' 表示 4 个连续的卷积.
实现细节
训练
- 与 ground truth box 的 IoU 重合度超过 0.5 的 RoI 视为正例, 否则为反例.
- Mask 损失只定义在正例上. Mask 分支每个 RoI 可以预测 K (总类别数) 个 masks, 但我们只使用第 k 个, 这里的 k 是分类分支预测出的类别.
- 图像 resize 到短边为 800 像素.
- 每个 mini-batch 每个 GPU 使用两张图, 每张图有 N 个采样的 RoIs, 正负样本数比例为 1:3. C4 主干的 N=64, FPN 主干的 N=512.
- 在 8 块 GPU 上训练 160k 步, 在第 120k 步的时候学习率从 0.02 下降到 0.002. 使用 0.0001 的权重衰减和 0.9 的动量.
- RPN 的 anchor 使用了 5 种尺寸和 3 种比例, 与 FPN 中一致.
测试
- C4 的 proposals 的数量为 300, FPN 为 1000.
- 在所有的 proposals 上都进行 Bbox 回归, 最后应用 NMS.
- Mask 分支使用得分最高的 100 个检测框
- m×m 的浮点数的 mask 输出 resize 到 RoI 的大小, 然后应用 0.5 的阈值进行二值化.
指标 (metrics)
- \(AP\) (averagd over IoU thresholds), \(AP_{50},~AP_{75}\)
- \(AP_S,~AP_M,~AP_L\) (AP at different scales)
参考文献
[1] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu. Spatial transformer networks. In NIPS, 2015
[2] T.-Y. Lin, P. Doll´ ar, R. Girshick, K. He, B. Hariharan, and
S. Belongie. Feature pyramid networks for object detection. In CVPR, 2017
[3] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: To- wards real-time object detection with region proposal net- works. In NIPS, 2015
[4] R. Girshick. Fast R-CNN. In ICCV, 2015
[5] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ra- manan, P. Dollar, and C. L. Zitnick. Microsoft COCO: Com- mon objects in context. In ECCV, 2014