1. 少样本学习仍然是一种过拟合, 跨域学习更为重要
原始论文: A Closer Look at Few-Shot Classification1
1.1 概述
少样本学习 (few-shot learning, FSL) 是针对数据缺乏时充分利用先验信息来实现机器学习任务的一类方法. 少样本分类是使用有限的带标签样本训练分类器, 使其可以识别新类别 (unseen classes) 的方法. 目前的方法虽然取得了显著的成效, 但随着网络设计, 元学习算法的复杂化, 以及大量各不相同的实现细节使得已有方法难以公平比较.
本文贡献:
- 当数据集中不同类别的差异不大时 (如 CUB 鸟类数据集), 网络模型越深, 不同算法的差距就越小
- 提出一个基于距离分类器的 baseline 模型, 在 mini-Imagenet 和 CUB 数据集上达到了元学习 (meta-learning) state-of-the-art (SOTA) 的水平
- 提出了跨域 (cross domain) 少样本学习. 并指出当前的 FSL 方法在这样的问题上表现很差, 甚至不如 baseline 方法.
注: 不如 baseline 方法就意味着已有 FSL 方法仍然对测试集有严重的过拟合, 这实际上偏离了元学习方法的初衷 (大部分 FSL 方法都是元学习方法的应用).
目前 FSL 中存在的问题:
- 不同 FSL 算法实现细节的差异导致无法清楚的考察算法实际的提升效果. Baseline 算法的效果没有被充分挖掘, 比如没有使用数据增广
- 尽管现有 FSL 算法可以识别新的类别, 但新的类别和训练的类别来自于同一个数据集. 域漂移 (domain shift) 的缺失导致这样的算法实际上远离实际情况.
1.2 少样本分类算法
本文考察了两种 baseline 模型和四种 FSL 模型.
1.2.1 Baseline
这是一个基于迁移学习 (transfer learning) 的方法. \(\newcommand{\wb}{\mathbf{W}_b} \newcommand{\wn}{\mathbf{W}_n} \newcommand{\x}{\mathbf{x}} \newcommand{\X}{\mathbf{X}} \newcommand{\w}{\mathbf{w}}\)
训练阶段: 从头训练特征提取器 \(f_{\theta}\) 和分类器 \(C(\cdot\vert\wb)\) , 使用交叉熵损失 \(L_{pred}\) 和基类数据 \(\x_i\in\X_b\) . 这里记编码后的特征维度为 \(d\) , 输出类别为 \(c\) . 那么分类器的权重有 \(\wb\in\mathbb{R}^{d\times c}\) , 且 \(C(\cdot\vert\wb)=\sigma(\wb^Tf_{\theta}(\x_i))\)
其中 \(\sigma\) 是 softmax 函数.
微调阶段: 通过微调模型使其可以识别新的类别. 固定与训练参数 \(\theta\) , 使用新类的标注数据 (即支撑集 \(\X_n\)) 训练新的分类器 \(C(\cdot\vert\wn)\) .
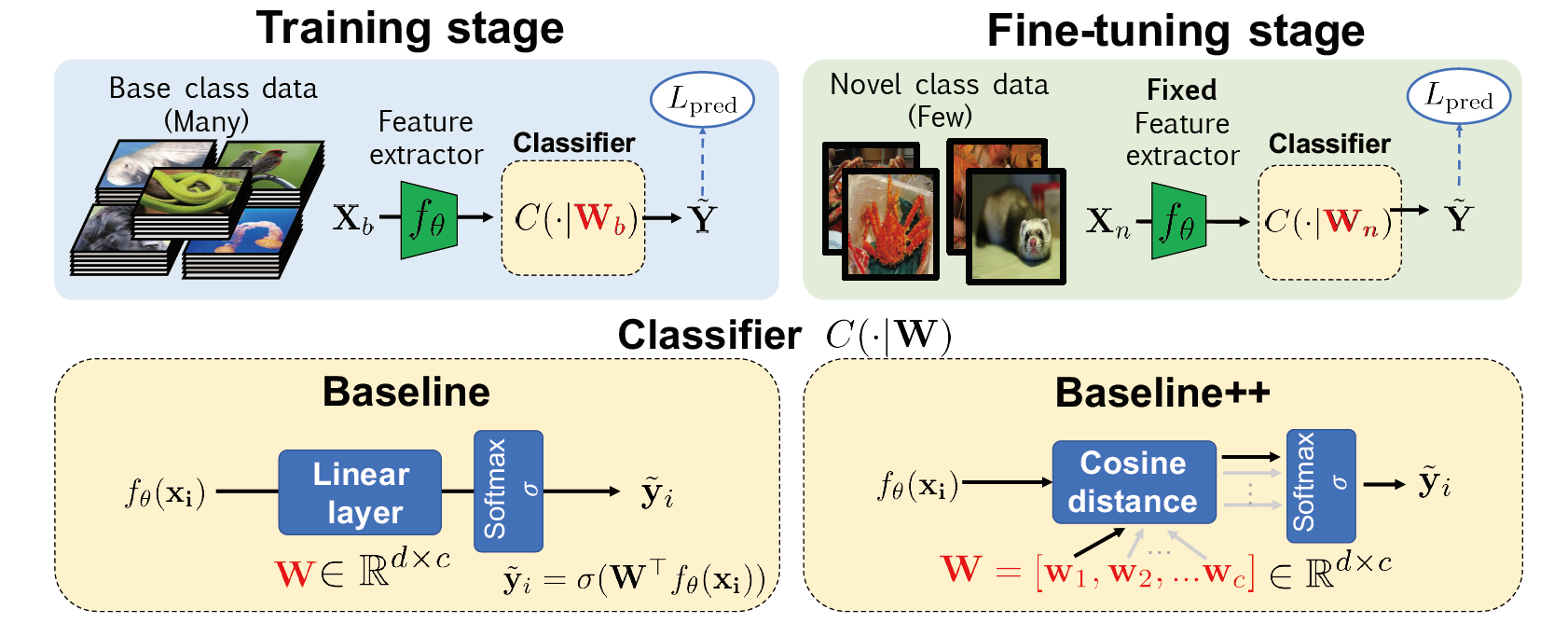
图 1. Baseline 和 Baseline++ 模型
1.2.2 Baseline++
本文提出了一种在训练时减小类内方差 (intra-class variation) 的模型. 和 Baseline 模型整体上是类似的, Baseline++ 在分类器的地方使用了余弦距离: \(s_{i,j}=\frac{f_{\theta}(\x_i)^T\w_j}{\Vert f_{\theta}(\x_i)\Vert\Vert\w_j\Vert}\) 其中 \(\wb=[\w_1,\w_2,\dots,\w_c]\) . 使用基于距离的分类器训练模型明显地可以减小类内方差. 直观地, 学到的权重 \([\w_1,\w_2,\dots,\w_c]\) 可以看作类别的原型 (prototypes) , 而分类是基于判断特征到原型的距离来进行的. Baseline++ 的结构如图 1 所示.
1.2.3 Meta-learning
本文另外评估了四种基于元学习的 FSL 方法:
- MatchingNet
- ProtoNet
- RelationNet
- MAML
元学习的流程如下图所示.
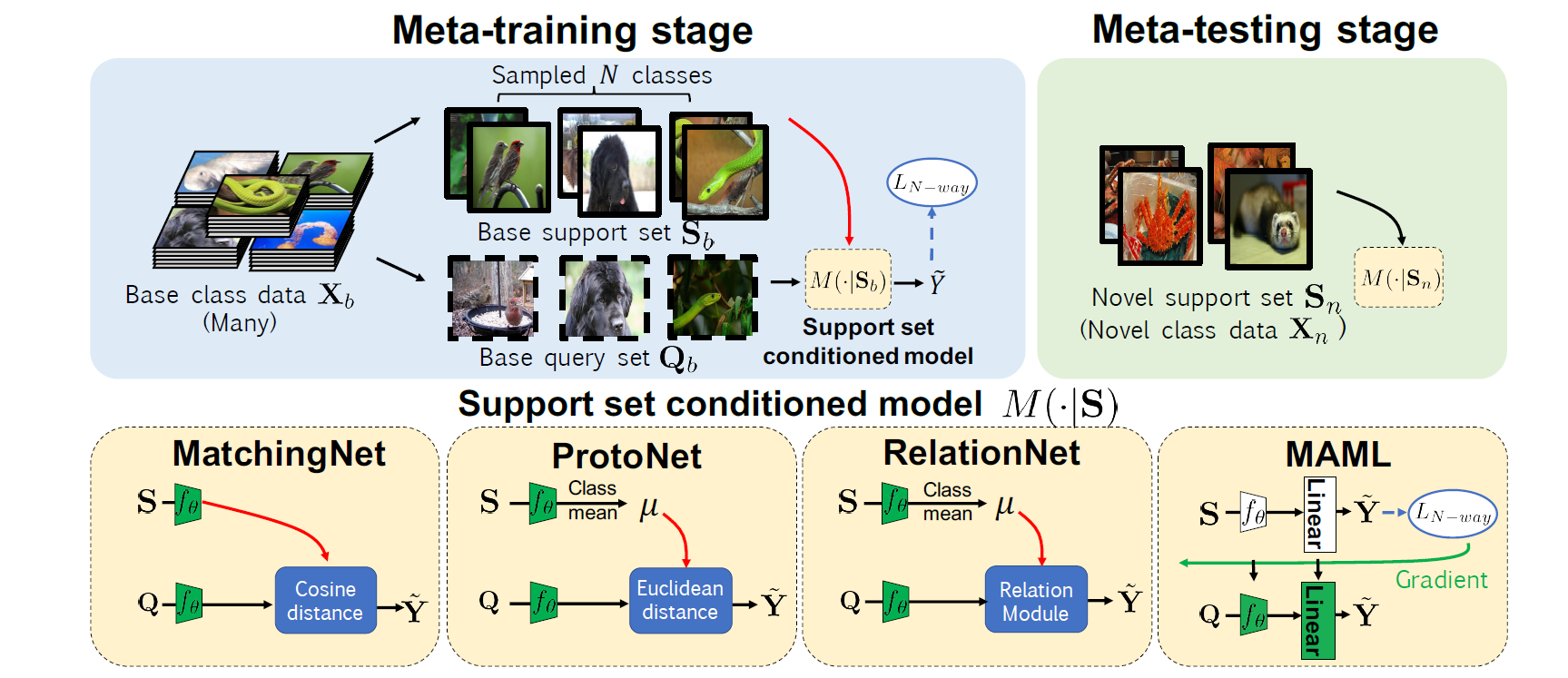
图 2. Meta-learning 模型
1.3 实验
1.3.1 数据集
- mini-ImageNet: (常规分类) 100 个类别, 每个类别 600 个样本. 64 base 类, 16 validation 类, 20 novel 类.
- CUB-200-2011: (细粒度分类) 200 个类别, 共 11788 个样本. 100 base 类, 50 validation 类, 50 novel 类.
- mini-ImageNet –> CUB: (跨域分类)
数据增广方法: random crop, left-right flip, color jitter
优化: Adam, lr=1e-3
1.3.2 标准配置的实验结果
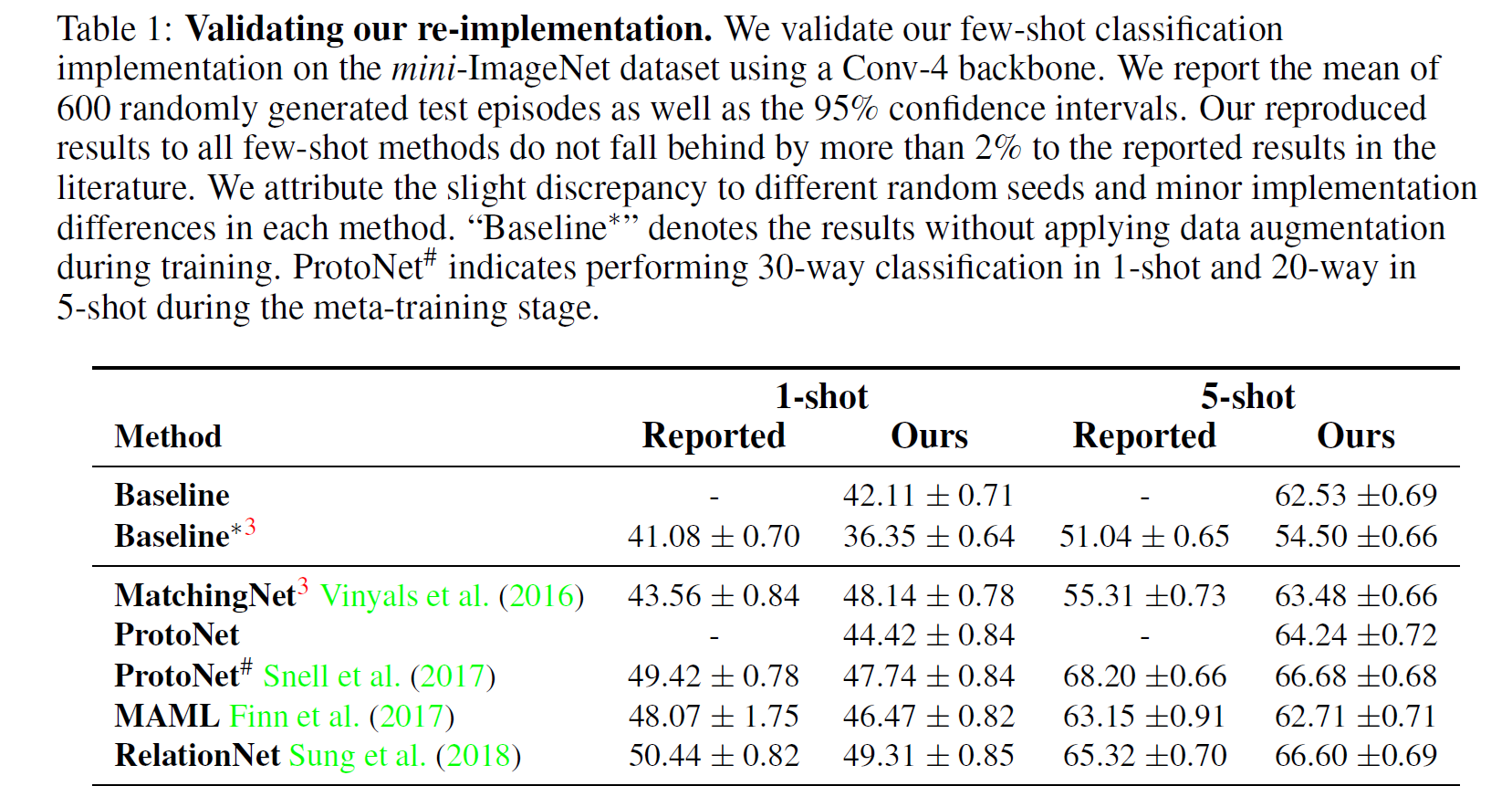
图 3. Baseline 和 FSL 方法在相同配置下的重实现
整体上, 重实现的结果比原始论文报告的结果低两个点不到. 其中,
-
Baseline 的方法增加了数据增广后, 远远高于论文的结果, 这说明
The performance of the Baseline method is severely underestimated
原始论文的结果过于低估
-
MatchingNet 通过调整 softmax 层数据的尺度 (乘一个系数), 精度有一个显著的提升. (这一点的原因本文没有分析, 但 NeurIPS 2018 的一篇论文 TADAM2 中有详细分析.)
-
尽管 ProtoNet# 要差于 ProtoNet, 但论文中提到使用更深的 backbone 可以解决该问题.
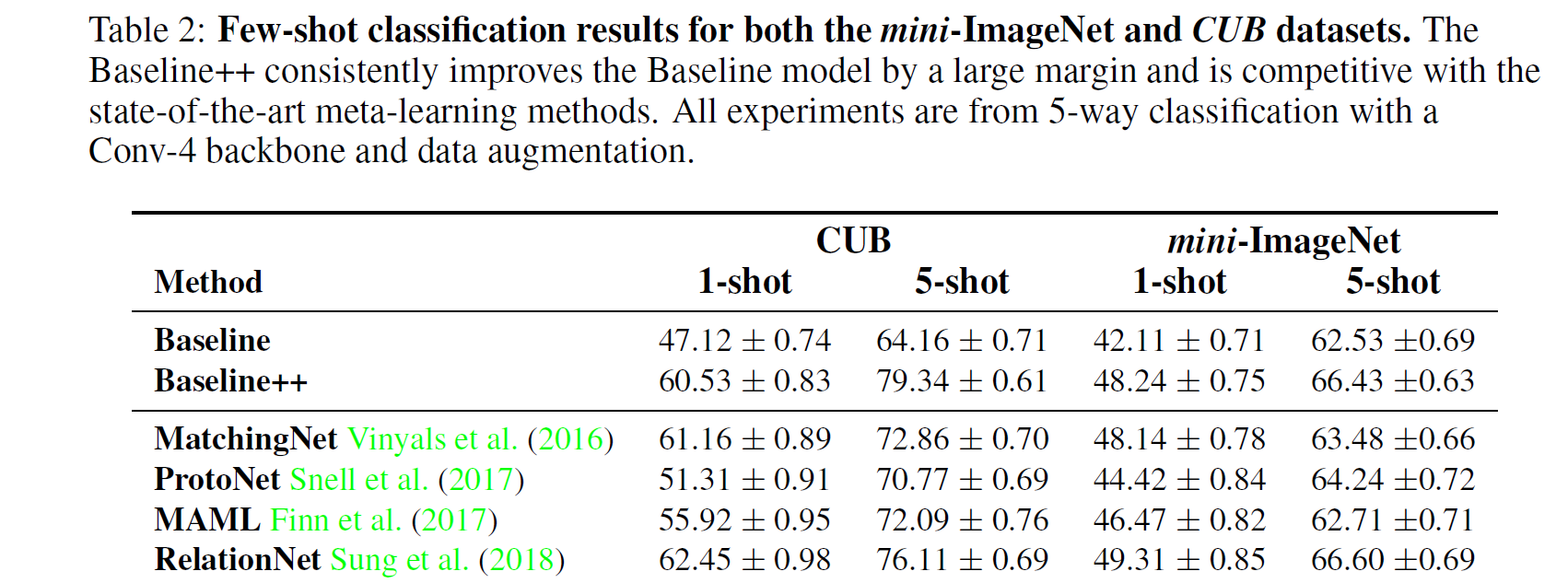
图 4. 同配置下不同方法的比较
这两组实验最显著结果就是:
-
Baseline++ (即微调+余弦距离) 效果特别好, 打平甚至超过一众元学习方法. 这说明
Reducing intra-class variation is an important factor in the current few-shot classification problem setting
减小类内方差是 FSL 的一个关键因素
1.3.3. 增加网络深度的影响
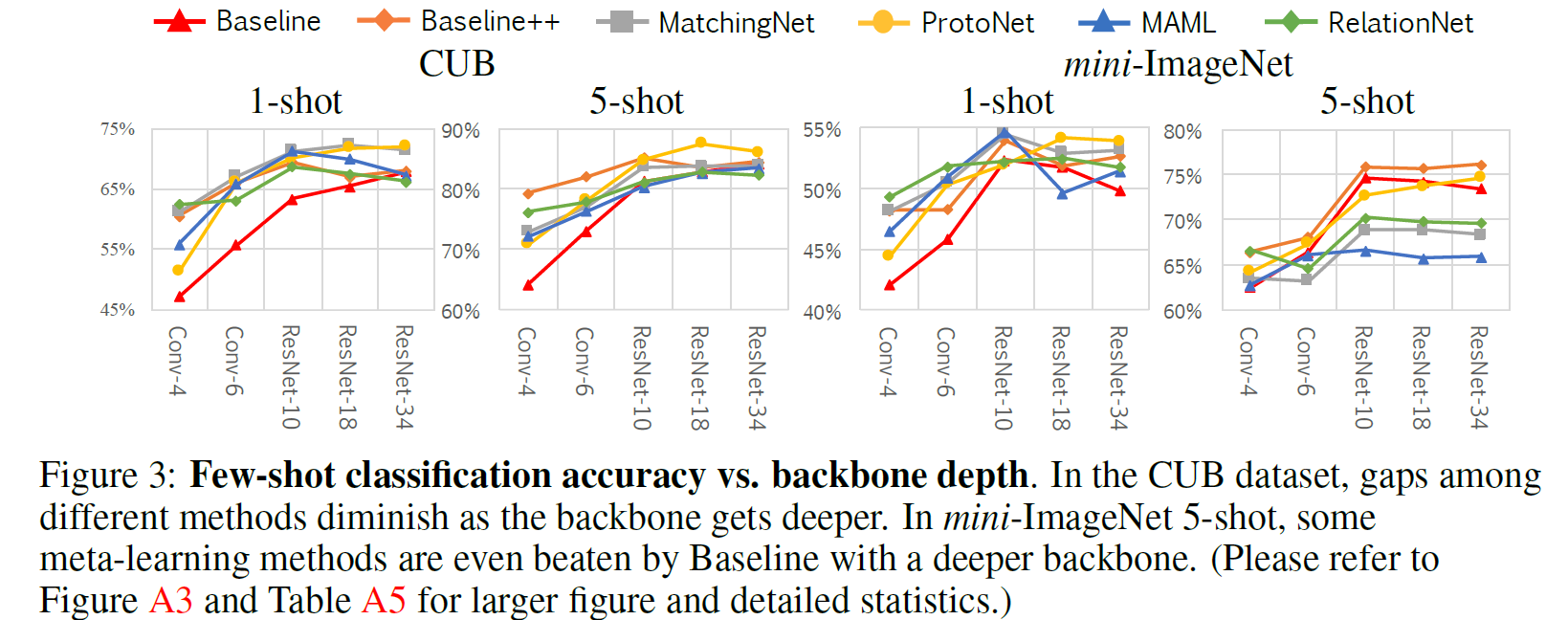
图 5. 增加网络深度的影响
增加网络深度后训练得到的特征拥有更小的类内方差. 这个结论是论文附录 A6 通过实验来说明的, 其中使用到了 Davies-Bouldin 指数3来衡量类内方差. 本文使用了五种深度的网络 Conv-4, Conv-6, ResNet-10, ResNet-18, ResNet-34. 图 5 的结果显示,
-
在 CUB 数据集上, 网络越深, 不同方法的差距越小.
In the CUB dataset, the gap among existing methods would be reduced if their intra-class variation are all reduced by a deeper backbone
在 CUB 数据集上, 如果更深的 backbone 可以减小类内方差, 那么这些方法的差距也会减小.
-
在 mini-ImageNet 数据集上, 上一条结论不成立.
FSL 问题中数据集的选择也很重要.
CUB 和 mini-ImageNet 最大的差别就是前者是细粒度的图像分类, 后者的类间方差更大.
1.3.4 域漂移的影响
本文进行了 cross-domain 的实验: mini-ImageNet –> CUB, 使用 ResNet-18 作为 backbone. 实验结果如下左图.
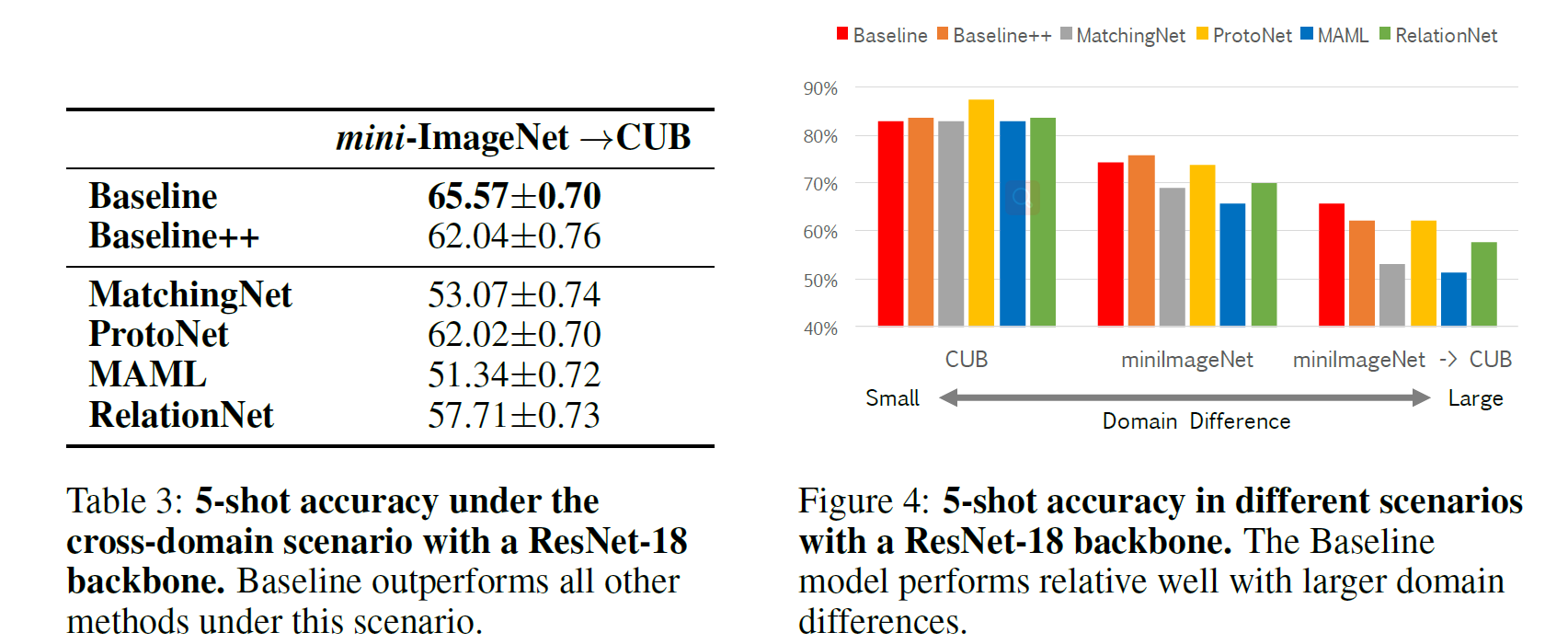
图 6. 跨域 FSL 的结果分析
-
Baseline 方法超过了其他所有的方法. 这说明现有的 FSL 方法对跨域 FSL 效果比微调要差. 而上右图的对比表明,
As the domain difference grows larger, the adaptation based on a few novel class instances becomes more important
随着 base 和 novel 域差距的扩大, 基于支撑集的域适应变得越来越重要
1.3.5 微调元学习方法
为了使元学习方法像 Baseline 方法那样适应, 本文尝试对输入 softmax 层的特征进行微调. MatchingNet 和 ProtoNet 可以直接进行微调; MAML 方法本来就需要在支撑集上训练, 所以把迭代次数提高到与 Baseline 方法一致即可; RelationNet 的特征是二维特征图, 不方便改为 softmax 层, 所以本文随机把支撑集划分为 3 个支撑和 2 个查询数据来微调关系模块. 结果如下图.
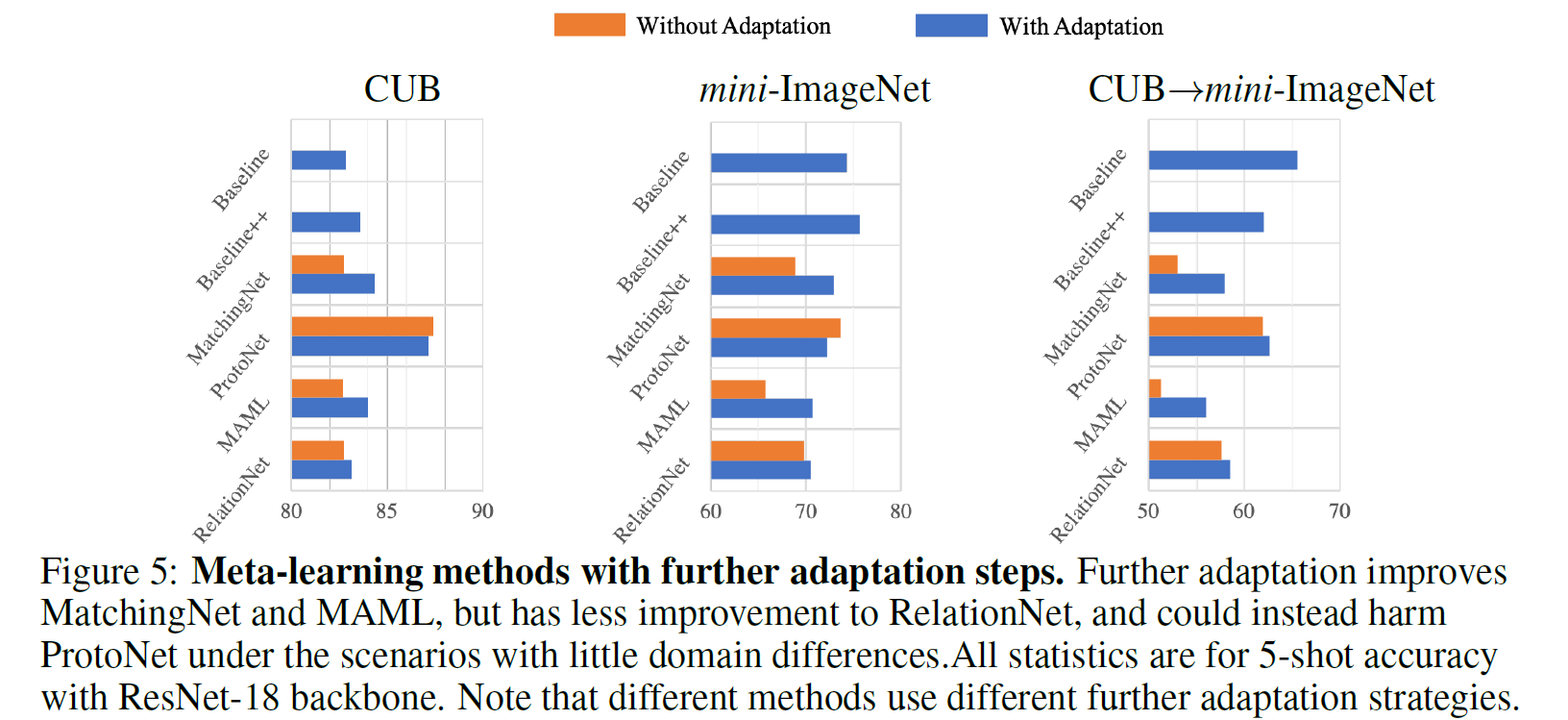
图 7. 元学习方法进一步微调
我们发现
-
MatchingNet 和 MAML 方法在微调后精度显著上升, 其中 mini-ImageNet –> CUB 最为明显. 这说明元学习方法差于 Baseline 方法的一个原因就是没有微调.
-
ProtoNet 在非跨域的情况下微调会损害精度
Learning to learn adaptation in the meta-training stage would be an important direction for future meta-learning research in few-shot classification
在基于元学习的 FSL 研究中, 实现元适应 (learning to learn adaptation, meta adaptation) 是元训练阶段的研究重点.
参考文献
-
A closer look at few-shot classification
Wei-Yu Chen, Yen-Cheng Liu, Zsolt Kira, Yu-Chiang Frank Wang, Jia-Bin Huang
[html], [pdf] ↩ -
TADAM: Task dependent adaptive metric for improved few-shot learning
Boris N. Oreshkin, Pau Rodriguez, Alexandre Lacoste
[html], [PDF]. In NeurIPS 2018. ↩ -
A cluster separation measure
Davies D L, Bouldin D W
html, In IEEE PAMI, 1979 (2): 224-227. ↩