- CVPR 2017: One-Shot Video Object Segmentation
- CVPR 2018: Efficient Video Object Segmentation via Network Modulation
- CVPR 2015: Hypercolumns for Object Segmentation and Fine-grained Localization
视频中对象的跟踪往往需要对某一个物体连续的分割, 鉴于神经网络方法的通用性和良好的泛化性, 最近有很多基于神经网络的半监督算法对视频中的单个和多个目标进行分割, 仅需要输入视频第一帧中目标分割的mask即可.
CVPR 2017: One-Shot Video Object Segmentation
作者: S. Caelles, K.-K. Maninis, J. Pont-Tuset, L. Leal-Taixé, D. Cremers, L. Van Gool
贡献:
- 仅提供单张分割图像, 即可使用CNN从视频中分割特定的对象
- 独立处理视频中的每幅图像, 不过度依赖时序信息(比如利用光流的方法就需要连续两帧之间的差别不能太大)
- 速度和精度的平衡可以自由掌控(由用户来选择)
流程如下图所示:
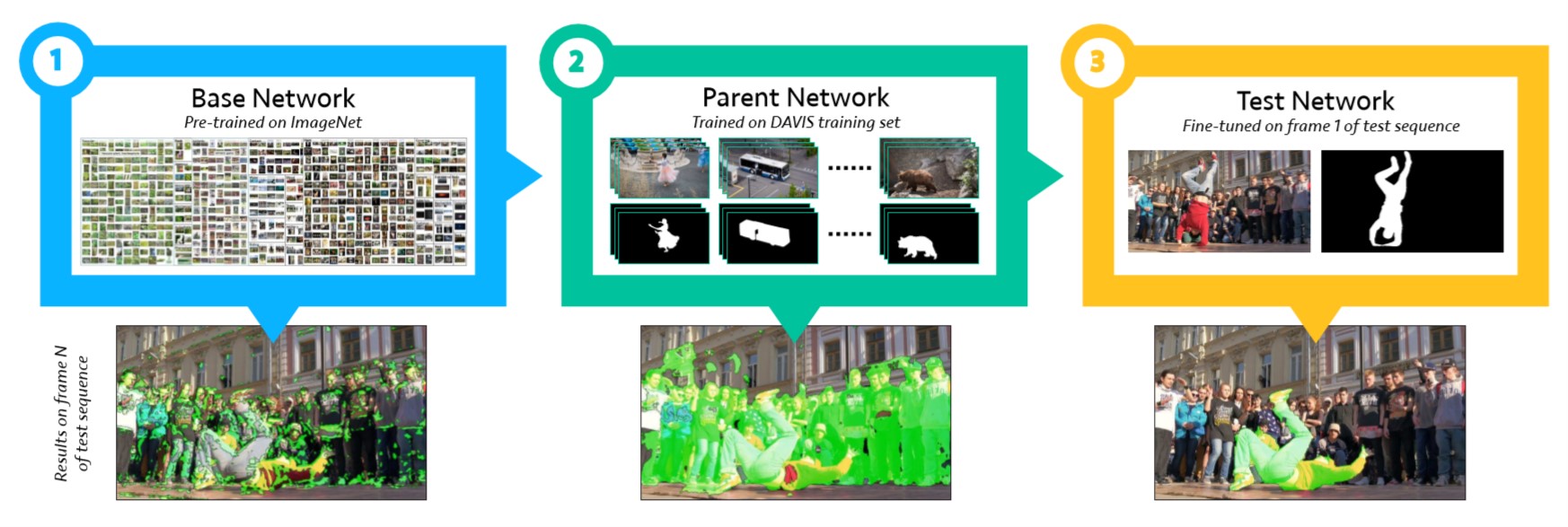
Overview of OSVOS
整个流程是个由粗到精的过程, 总共分为三步:
- 使用FCN作为backbone,在ImageNet数据集上预训练学习通用的语义信息
- 在DAVIS 2016的训练集上fine-tune,学习前景的语义分割
- 在测试视频的第一帧上fine-tune,学习到在后面帧中要进行分割的某特定目标的外形等信息,然后对后续帧进行分割
其中前两步是离线训练, 可以提前训练好备用. 第3步是在线训练, 接收到新的视频后使用第一帧提供的分割信息在第2步参数的基础上进行微调, 最终剩余帧中目标的分割.
此外本文为了强化边界信息, 增加了一个额外的模型提取整幅图像中的边界信息作为额外的监督, 模型结构如下图所示.
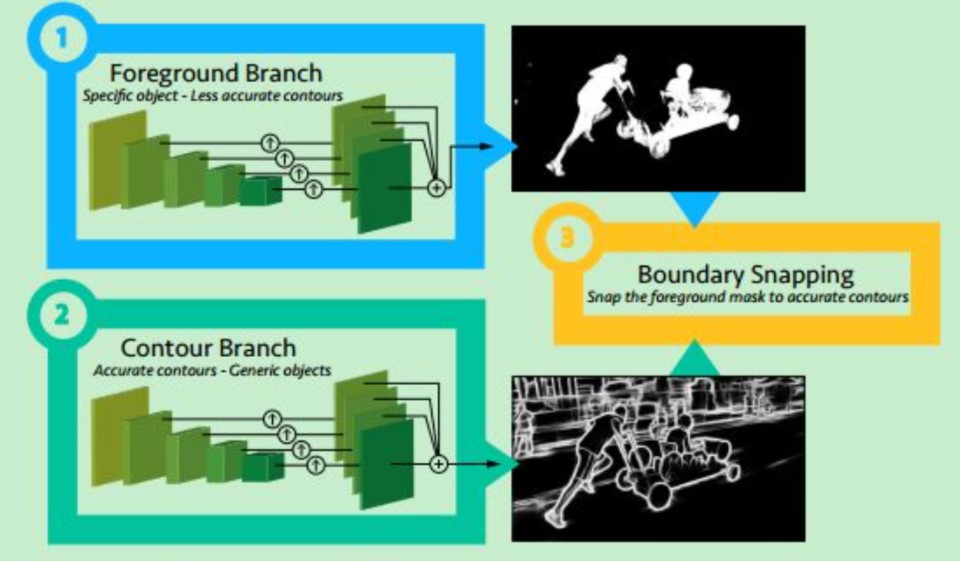
Two-stream FCN architecture
CVPR 2018: Efficient Video Object Segmentation via Network Modulation
作者: Linjie Yang, Yanran Wang, Xuehan Xiong, Jianchao Yang, Aggelos K. Katsaggelos
本文考虑到上一篇文章对于每个新的视频都需要fine-tune整个网络, 因此本文设计了几种 Network Modulators 来避免这种问题.
网络模块
1. Conditional batch normalization, CBN
使用额外的网络产生放缩参数 \(\gamma_c\) 和偏置参数 \(\beta_c\), 从而 CBN 层可以公式化表达为
\[\mathbf{y}_c = \gamma_c\mathbf{x}_c + \beta_c,\]这里为了简洁忽略均值和方差.
2. Visual and spatial modulation
CBN 层仍然是 scale-and-shift 操作的一种特殊形式, 而本文定义了一种新的调整层, 参数由 visual 和 spatial 调整器(modulator)产生. 其中 visual 调整器产生 channel-wise 的参数来调整不同通道的权重, spatial 调整器产生 element-wise 的参数在调整后的特征中注入空间先验信息, 从而新的调整层可以公式化为
\[\mathbf{y}_c = \gamma_c\mathbf{x}_c + \mathbf{\beta}_c,\]其中 \(\gamma_c\) 和 \(\mathbf{\beta}_c\) 是两个调整层的参数. 下图是网络结构.
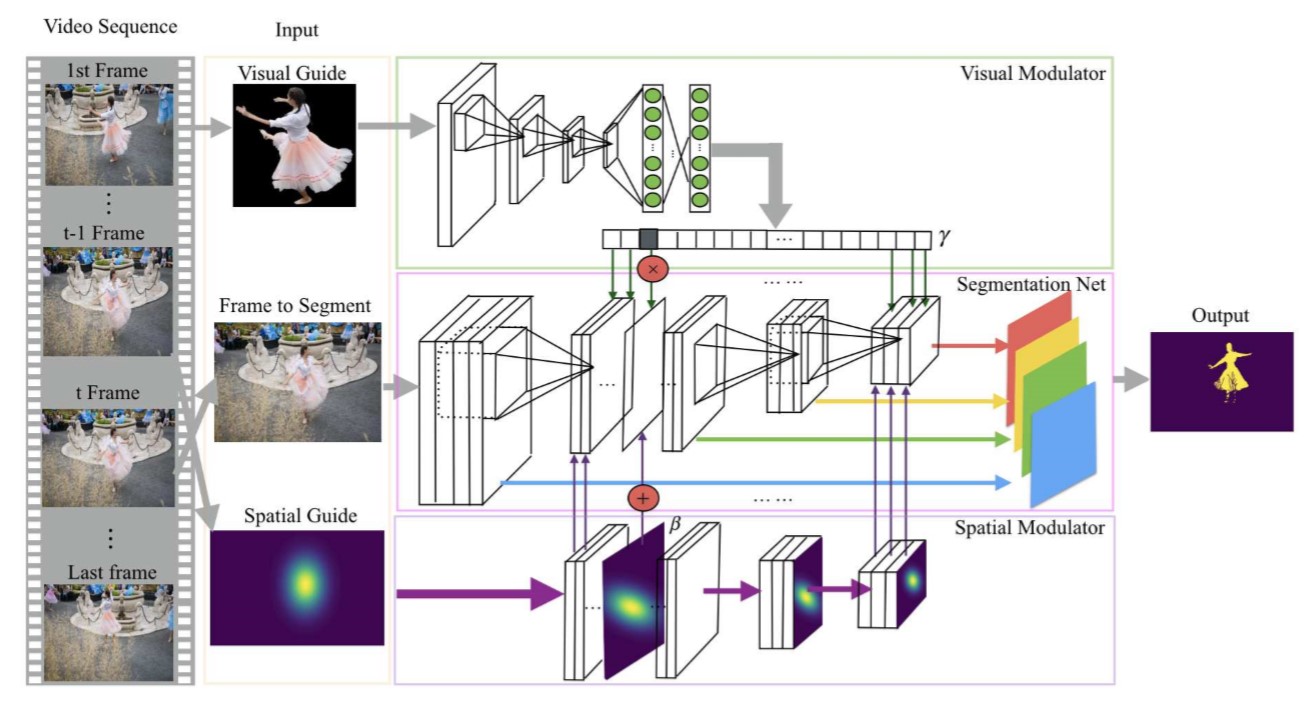
Network Modulation
2.1 Visual 调整器
视频目标分割需要网络能够追踪特定的目标, visual 调整器通过从 visual guide 中提取语义信息(如类别, 颜色, 形状, 纹理等), 产生 channel-wise 的权重, 使网络学习的焦点重定位到目标物体上. 实际上 visual 调整器学习的是不同物体的 embedding, 并且本文也通过实验证明了网络的确学到了这种 embedding 的关系(即相似的目标对应相似的参数, 不同的目标对应不同的参数).
2.2 Spatial 调整器
前面提到 spatial 调整器用于产生空间先验信息. 由于目标在视频中基本是连续变化的, 所以下一帧的空间先验信息可以由上一帧产生. 具体的, 本文并没有直接使用 mask 作为位置先验, 而是编码为一个二维的高斯分布作为 spatial guide. 这样做的原因主要是避免过度依赖于上一层的 mask 信息而导致误差的累计传播, 并且大致的分布信息足以让网络容易地推测当前帧的 mask. spatial 调整器会将 spatial guide 下采样以适配网络的不同尺寸的层. spatial 调整器的偏置参数由高斯分布应用 scale-and-shift 得到, 公式化为
\[\mathbf{\beta}_c = \tilde{\gamma}_c\mathbf{m} + \tilde{\beta}_c,\]其中 \(\mathbf{m}\) 是高斯分布的热力图, \(\tilde{\gamma}_c\) 和 \(\tilde{\beta}_c\) 是第 \(c\) 个通道的 scale-and-shift 参数.
CVPR 2015: Hypercolumns for Object Segmentation and Fine-grained Localization
Bharath Hariharan, Pablo Arbeláez, Ross Grishick, Jitendra Malik
传统CNN仅使用输出层作为特征表示, 但高层特征丢失了空间精度从而不利于精确定位, 相反底层特征可以精确定位但缺乏语义信息. 因此本文假设感兴趣的信息分布在CNN的各个层, 并且应当被充分地利用.
本文考虑了涉及到精确定位的三个研究课题:
为了解决上面提到了信息利用不充分的问题, 作者提出了像素的 hypercolumn, 它是 CNN 中所有神经元在该像素”上”的激活值组成的向量.
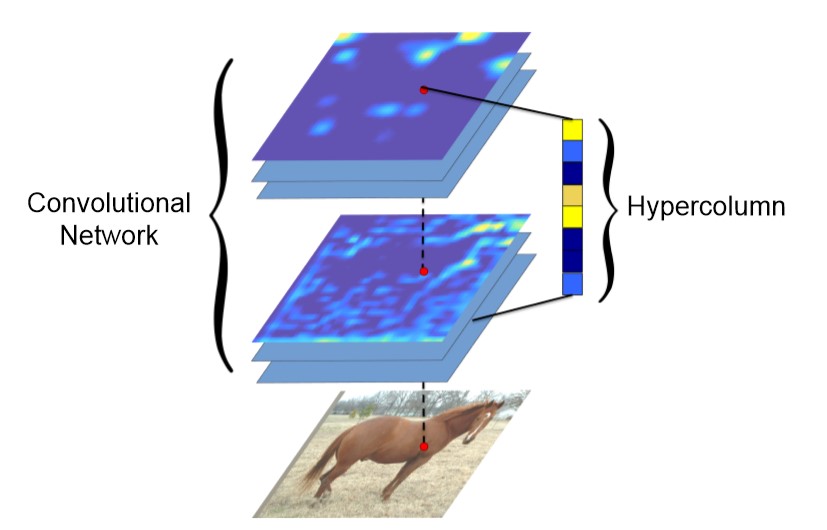
Hypercolumn Extraction
提取 hypercolumn 的第一步是把图像送入 CNN 并提取特征图. 当特征图小于输入图像大小时(如池化后), 需要通过插值上采样为输入图像大小. 对于全连接(FC)层, 则认为所有位置的像素共享相同的信息. 然后所有的激活值都拼接起来作为每个像素的 hypercolumn.
最后训练分类器分类, 我们希望分类器能关注到像素的位置信息(比如检测框偏上位置鼻子嘴巴出现的概率更大, 偏下位置鞋出现的概率更大), 而在所有位置上共享分类器则会导致分类器无法关注到位置信息, 但是不同位置训练不同的分类器又太过于耗时耗力. 因此本文采取折中的方法, 训练\(K\times K\)个分类器, 最后特定位置的分类概率由\(K^2\)分类器预测的结果插值得到.