架构这个事情其实我是不懂的, 不过为了这个入门 Wiki 的完整性, 还是强行写点, 主要还是为了后续编程时不至于乱调参数(尽管大部分时间还是得调).
引言
为什么要大规模”并行”计算?
- CPU主频再难以提高(目前貌似最高达到了5GHz? 还是睿频出来的)
- 不能大批量的增加CPU的核心数(太贵)
- 可以继续增加晶体管的密度(摩尔定律)
摩尔定律 Picture Source
再看Inter CPU和NVIDIA GPU在计算能力上的比较:
- CPU: 100GFLOPs vs GPU TFLOPs
- GPU的数据传输带宽大约是CPU的10倍
数据计算无法再单纯的使用多核CPU实现, 无论有8线程的CPU还是16线程的CPU或者更多, 总会有更多的数据需要计算. 因此百万上千万的线程并行才是WD.
CPU和GPU比较
首先看一下当前常用的 CPU 硬件结构, 有两种:
- Multicore Chip: 每个处理器仅支持一个硬件线程
- Manycore Chip: 每个处理器支持多个硬件线程
- 两种芯片上均带有存储空间(cache, RAM)
- 均需要外部存储(外部 RAM, 如常说的”内存”)
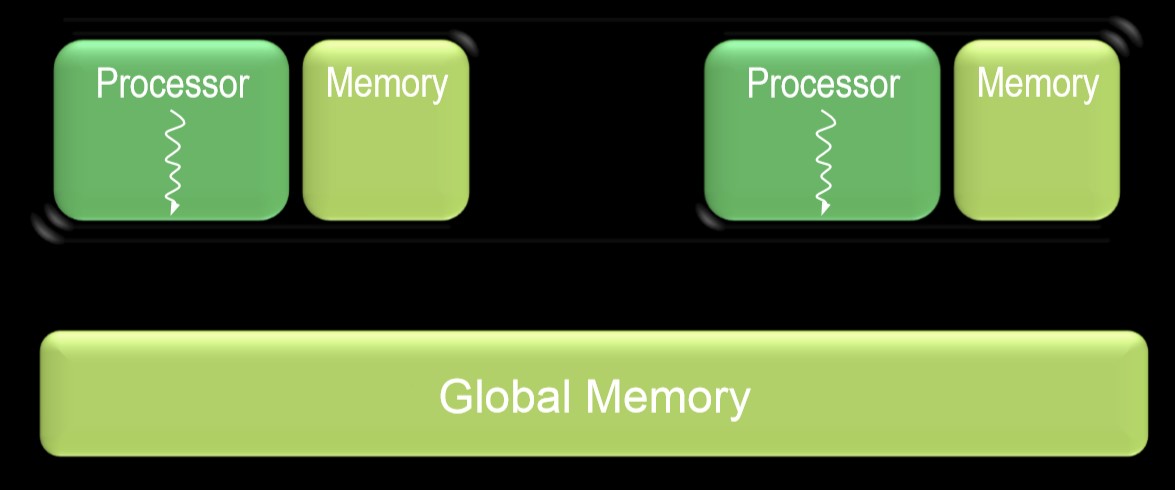
Multicore Chip
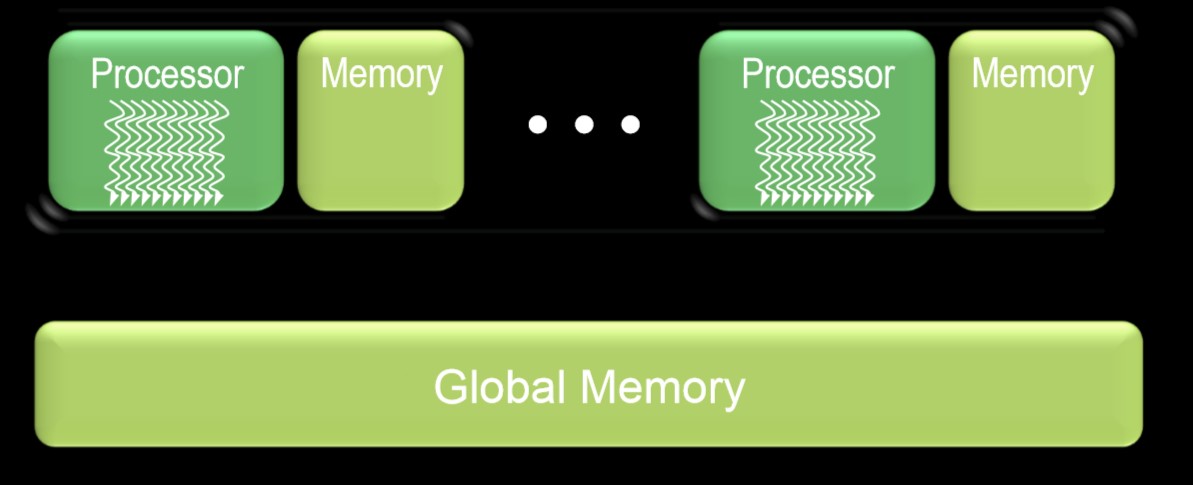
Manycore Chip
GPU的特点:
- 极高的吞吐量
- GPU假设了它的工作是高度并行化的, 因此能快速创建, 运行和销毁大量线程
- 使用多线程来隐藏延迟
NVIDIA GPU的硬件架构
| Fermi | Kepler | Maxwell | Pascal | Volta | Turing |
| 2010 | 2012 | 2014 | 2016 | 2017 | 2018 |
下面以 Fermi 架构为例解释:

GPU 的 Fermi 微架构
NVIDIA GPU 计算的核心: 流式多处理器(Stream Multiprocessor, SM)
- 每个SM包含32个CUDA核心(core)
- 直接读写内存, 数百GB/s
- 64K芯片上的内存, 在CUDA核心之间共享, 利于线程交流
架构的核心思想:
- 单指令多线程(SIMT)执行
- 32 个线程为一组运行, 成为 warp
- 一个 warp 中的线程共享指令单元, 即同时调度
- 自动控制分支语句
- 硬件多线程
- 资源分配 & 线程调度
- 依赖于多线程隐藏延迟
- 线程包含了它运行所需的资源
- 不处于等待中的warp可以直接运行
- 自由的上下文切换
CUDA: 可扩展的并行编程语言
- 使用最小的抽象扩展C/C++语言
- CUDA 的代码可以直接映射到GPU设备
- 使用成百上千的核心 & 上百万的并行线程计算
CUDA 中的并行抽象:
- 并行线程的多级分层
- 并行核心由大量线程组成
- 线程按照线程块(block)分组, 组内线程可以协作, 组件线程互不影响, 不能协作
- 线程/线程块都有唯一的标识ID
- 轻量级的同步语句
- 用于线程协作的共享内存(shared memory)
Hello World!
C for CUDA
由于 CUDA 仅是C/C++语言的拓展, 所以主程序除了仍然保持C/C++语言的语法外, 引入了一些仅CUDA编译器 nvcc 才能识别的语法特性, 列举如下:
- 函数修饰符
1
2
__global__ void my_kernel() { }
__device__ float my_device_func() { }
- 变量修饰符
1
2
__constant__ float my_constant_array[32];
__shared__ float my_shared_array[32];
- 核函数(并行的函数)配置: 指定线程数, 线程块数, 共享内存, 流等
1
2
3
dim3 grid_dim(100, 50); // 5000 thread blocks
dim3 block_dim(4, 8, 8); // 256 threads per block
my_kernel <<< grid_dim, block_dim >>> (...); // Launch kernel
- 设备代码(divice code)中预定义的变量(定义在编译器中的变量, CUDA 的编译器是 nvcc)
1
2
3
4
5
dim3 gridDim; // Grid dimension
dim3 blockDim; // Block dimension
dim3 blockIdx; // Block index
dim3 threadIdx; // Thread index
void __syncthreads(); // Thread synchronization
例子: 向量加法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
#include "../common/book.h"
#define N 10
// compute vector sum c = a + b
__global__ void add(int *a, int *b, int *c)
{
int tid = blockIdx.x; // handle the data at this index
if (tid < N)
c[tid] = a[tid] + b[tid];
}
int main()
{
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
// allocate the memory on the GPU
HANDLE_ERROR(cudaMalloc((void**)&dev_a, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_b, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_c, N * sizeof(int)));
// fill the arrays 'a' and 'b' on the CPU
for (int i = 0; i < N; i++)
{
a[i] = -i;
b[i] = i * i;
}
// copy the arrays 'a' and 'b' to the GPU
HANDLE_ERROR(cudaMemcpy(dev_a, a, N * sizeof(int), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, b, N * sizeof(int), cudaMemcpyHostToDevice));
add<<< N, 1 >>>(dev_a, dev_b, dev_c);
// copy the array 'c' back from the GPU to the CPU
HANDLE_ERROR(cudaMemcpy(c, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost));
// display the results
for (int i=0; i<N; i++)
{
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
// free the memory allocated on the GPU
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}