Combining Fully Convolutional and Recurrent Neural Networks for 3D Biomedical Image Segmentation
本文发表于 NIPS 2016
目的: 结合 FCN 和 RNN 解决 3D 医学图像分割时的各向异性(z轴的像素间距远大于xy轴的)问题
1. Introduction
目前的 3D 医学图像分割方法存在的问题:
- 直接把 2D 分割合并为 3D 会丢失空间信息
- 3D 卷积更耗费计算资源, 并且显著延长了训练时间
- 在三个正交平面上训练 2D 网络会由于 z 轴的低分辨率导致一些问题
本文的亮点在于通过系统性的 2D 操作, 权衡了 3D 图像的各向异性, 构造了一个高效的从 3D 上下文中提取信息的结构.
2. Methodology
本文提出的分割框架核心是两个组件: FCN(称为 kU-Net) 和 RNN(称为 BDC-LSTM) , 分别用于学习 intra-slice 和 inter-slice 的信息.
2.1 kU-Net
3D 分割任务如果单纯地拆解成 2D 分割, 那么通常会出现不同的 2D 切片中目标形状大小变化很大的情况. 那么 kU-Net 正式针对这个问题, 模拟人类的做法先从宏观上找到目标, 再从细节上判别边界. 它包括两个机制:
- 采用一系列子模块 FCNs 提取不同尺度上的图像信息
- 那些从粗糙尺度上提取了特征的 FCN 会把信息传递给后来的 FCN 以辅助提取细节特征.
文中给出了四种特征图传递的方式:
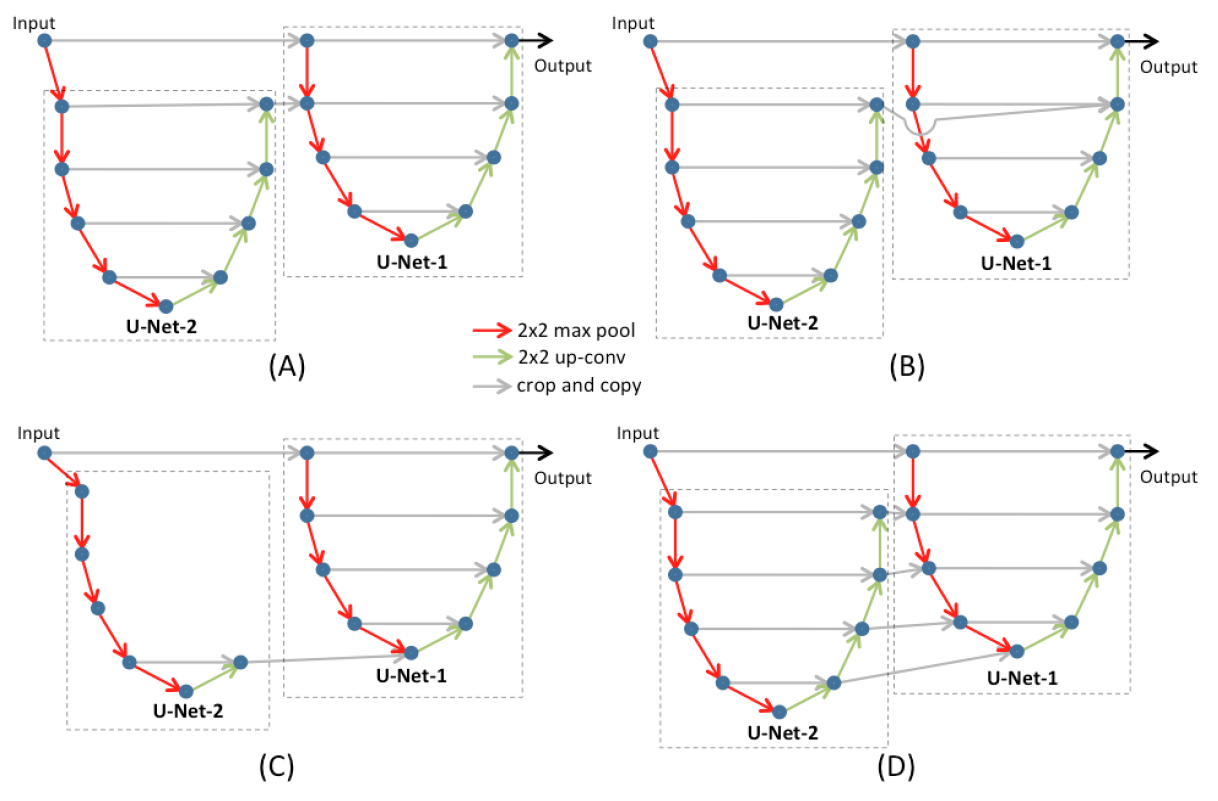
图 1. 四种特征图的传递方式
(A) U-Net-2 把原始图像做一次下采用送入 U-Net, 用于得到粗糙尺度上的信息, U-Net-1 从原始图像中直接裁剪, 在 U-Net 初期与粗糙尺度上的信息融合
(B) 在 U-Net-1 的后期与粗糙尺度上的信息融合
(C) U-Net-(t-1) 仅使用 U-Net-t 中最抽象的信息
(D) U-Net-(t-1) 使用 U-Net-t 中每一层的信息
在实验中结构 (A) 和 (D) 表现最好, 而结构 (A) 的参数更少, 所以选择 (A) 作为后续实验的 kU-Net 结构.
2.2 BDC-LSTM
RNN(比如 LSTM) 是一种维持了自我状态(称为记忆)的神经网络结构. 而 CLSTM 的输入是图像, 把 LSTM 门中的向量乘法替换为卷积操作, 这种结构在图像序列中尤为有效.
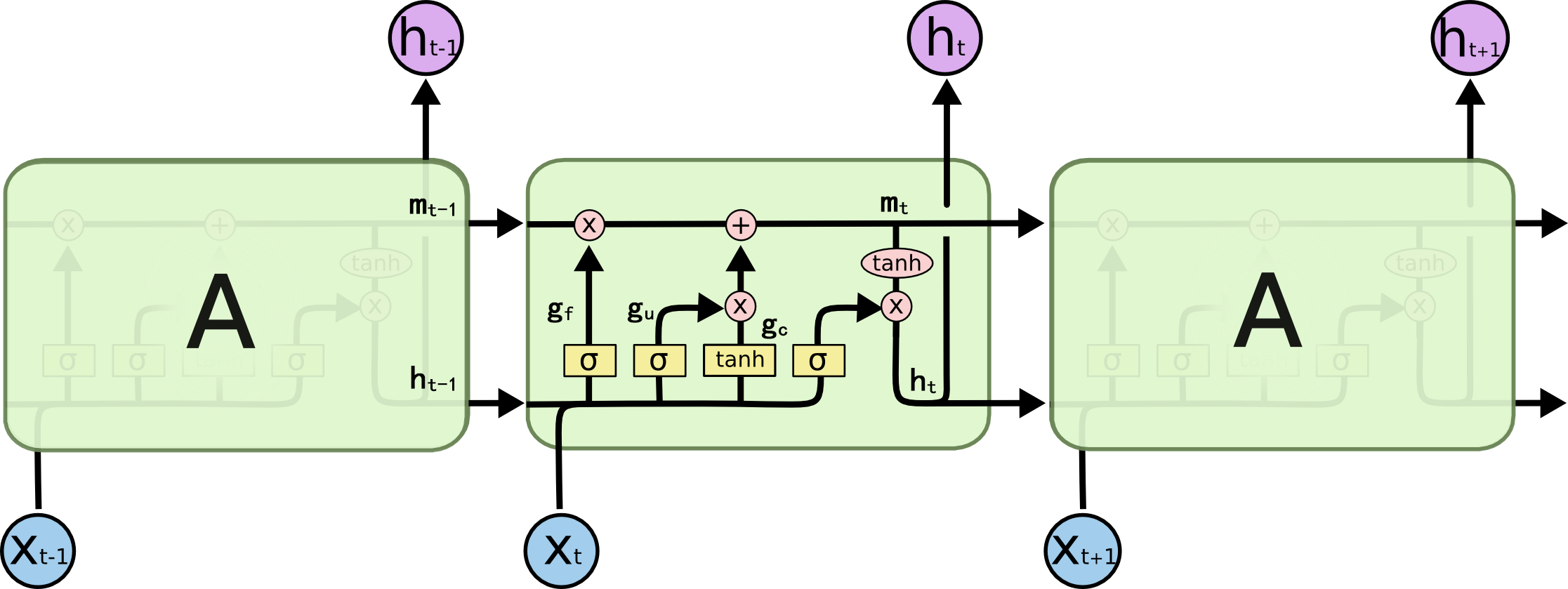
图 2. LSTM 的基本结构
上图是 LSTM 的基本结构, 其中 \([x_0, x_1, ..., x_n]\) 表示输入的 3D 图像, \(x_t\) 为一个切片, \([h_0, h_1, ..., h_m]\) 表示一层 LSTM 的输出. 图中的三个 \(\sigma\) 从左到右依次表示遗忘门, 输入门和输出门, \(\tanh\) 表示状态门. \(m\) 为单元的激活状态, \(\times\) 表示 element-wise 的乘法, \(+\) 表示 element-wise 的加法, \(*\) 表示二维卷积. 每个单元的计算公式如下:
\[\begin{align} g_u &= \sigma(x_t*W_{xi} + h_{t-1}*W_{hi} + b_i) \\ g_f &= \sigma(x_t*W_{xf} + h_{t-1}*W_{hf} + b_f) \\ g_c &= \tanh(x_t*W_{xc} + h_{t-1}*W_{hc} + b_c) \\ g_o &= \sigma(x_t*W_{xo} + h_{t-1}*W_{ho} + b_o) \\ m_t &= m_{t-1}\times g_f + g_c\times g_u \\ h_t &= g_o \times \tanh(m_t) \end{align}\]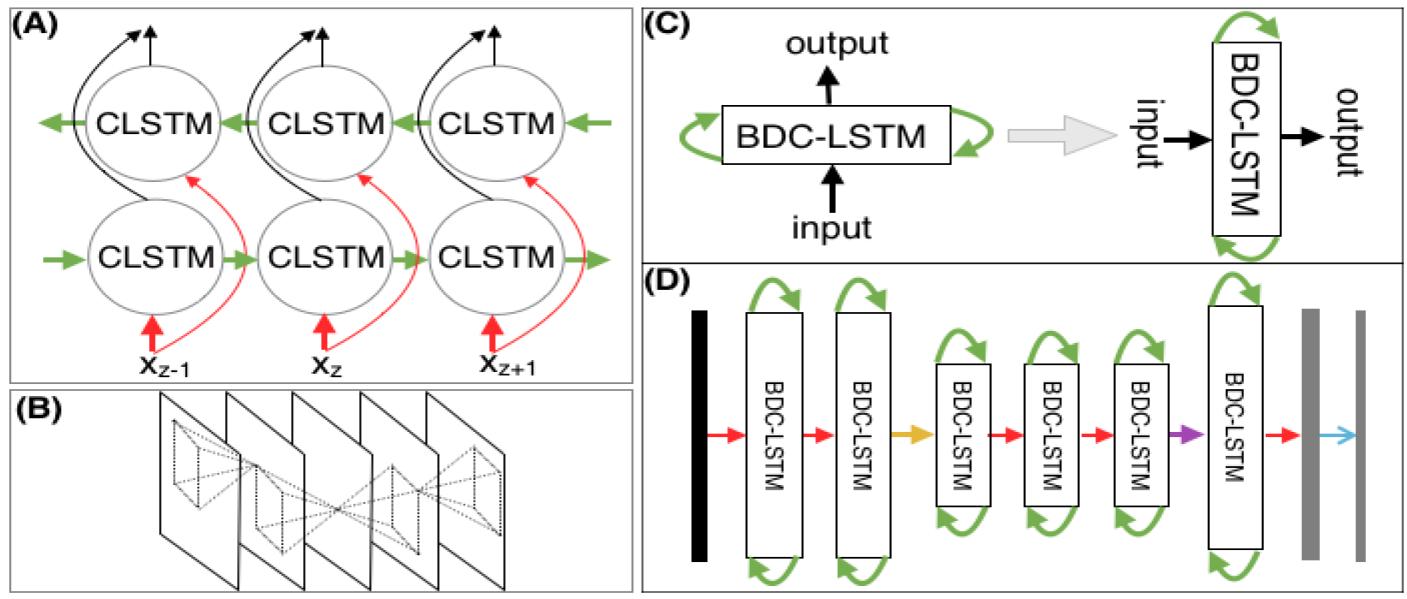
图 3. 各个部分网络的结构
上图 (A) 是双向 LSTM (BDC-LSTM)的网络结构, (D) 是本文使用的 RNN 部分的网络结构. 上图 (D) 中层的标注有一些问题, 具体每一层结构的含义参考论文.
2.3 Combining
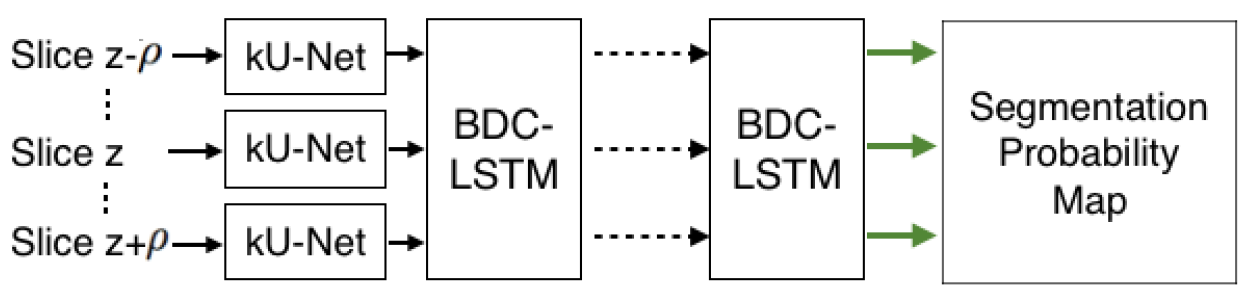
图 4. 两个网络的结合
按照上图的方式把两个网络组合起来.
2.4 训练策略
FCNs 和 BDC-LSTM 分开训练. 其他训练细节见论文.
3. 实验
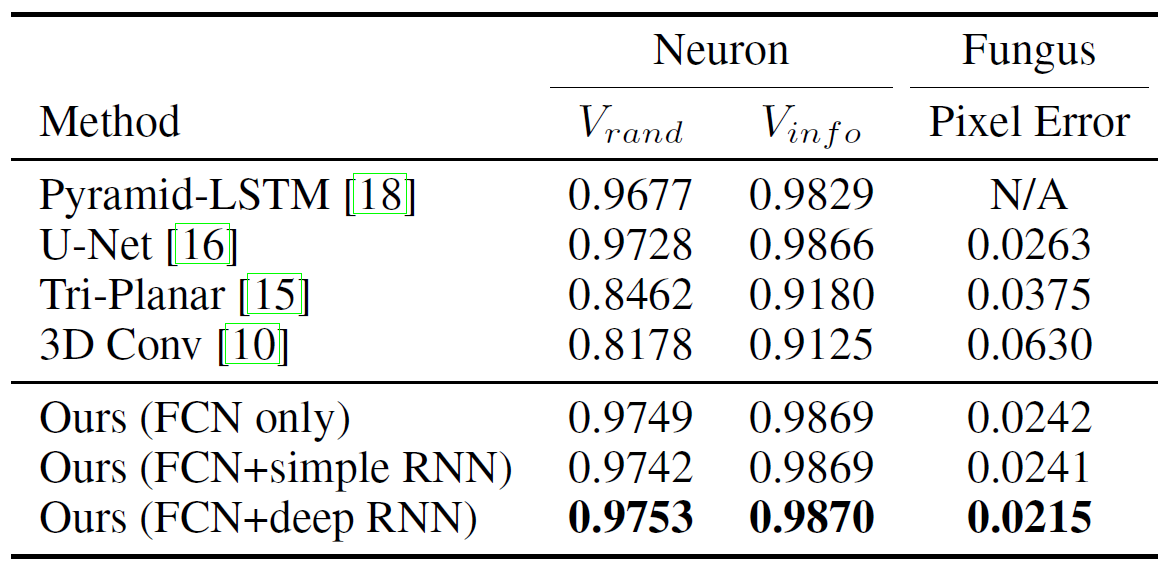
图 5. 实验结果
从实验结果来看, FCN+BDC-LSTM 的策略是有一定的效果的, 但是提升的效果并不是很显著, 有两个可能:
- 说明当 baseline 足够高时 3D 信息的贡献无法凸显
- 该数据集对 3D 信息依赖性不强