- 1. 循环神经网络 (Recurrent Neural Network, RNN)
- 2. 长短期记忆 (Long Short Term Memory, LSTM)
- 3. 门控循环单元(Gated Recurrent Unit, GRU)
- 4. 编码-解码器 (Encoder-Decoder)
- 5. 注意力机制 (Attention Mechanism)
- 6. tensorflow 官方代码解析
- References
1. 循环神经网络 (Recurrent Neural Network, RNN)
在机器学习中, 数据表示为 \(n\) 维特征向量 \(\mathbf{x}\in\mathbb{R}^n\) 或 \(h\times w\) 维特征矩阵(如图片), 多层感知机 (multilayer perceptron, MLP) 和卷积神经网络 (convolutional neural network, CNN) 可以提取数据中的特征以进行分类回归等任务. 但通常的 MLP 或 CNN 处理的数据通常认为是独立同分布的, 因此当数据之间存在关联关系时, 这类模型则无法很好的编码数据间的依赖关系, 导致模型的表现较差. 一种典型的数据间依赖关系就是时序关系. 比如话说一半时对方可能就知道了你的意思, 一句话中的代词”他”指代的目标需要分析上下文后才能得到. 时序数据如下图所示, 一列向量则表示一个字的编码.
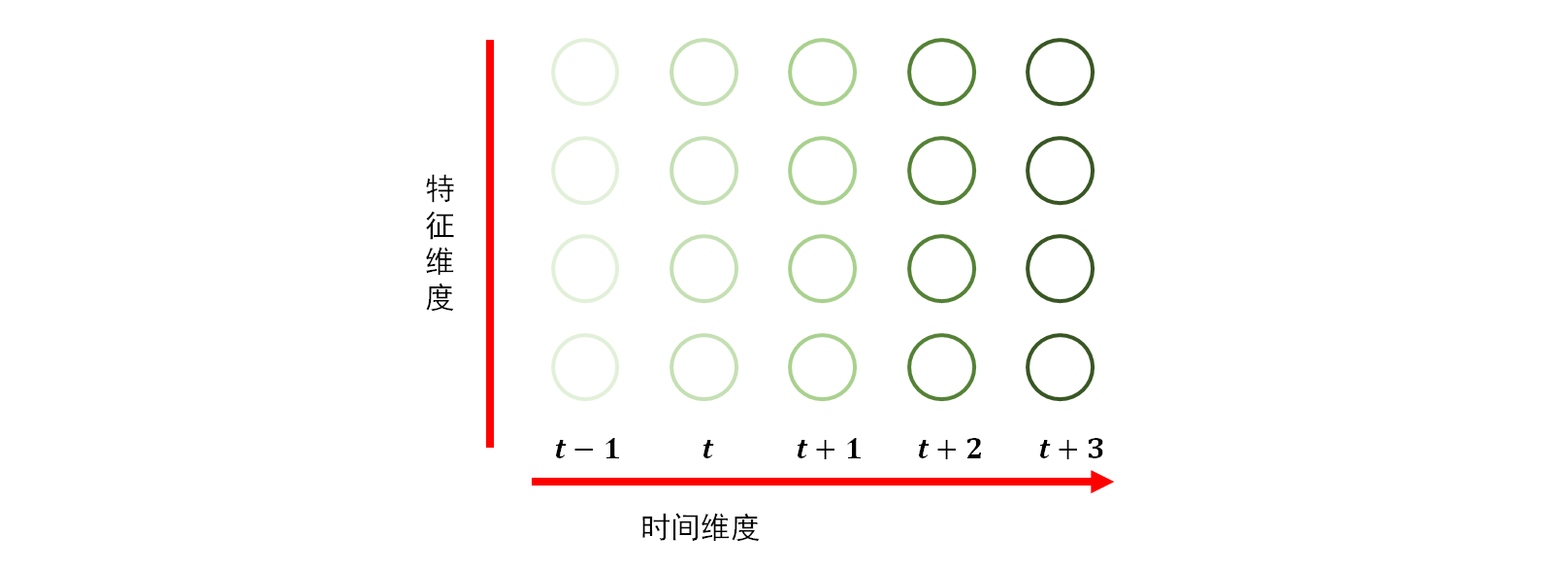
图 1. 时序数据
循环神经网络的提出就是为了解决数据中这种典型的时序依赖关系. RNN 是内部包含循环的神经网络 (普通 CNN 不包含循环), RNN 的一个循环单元如下图所示1.
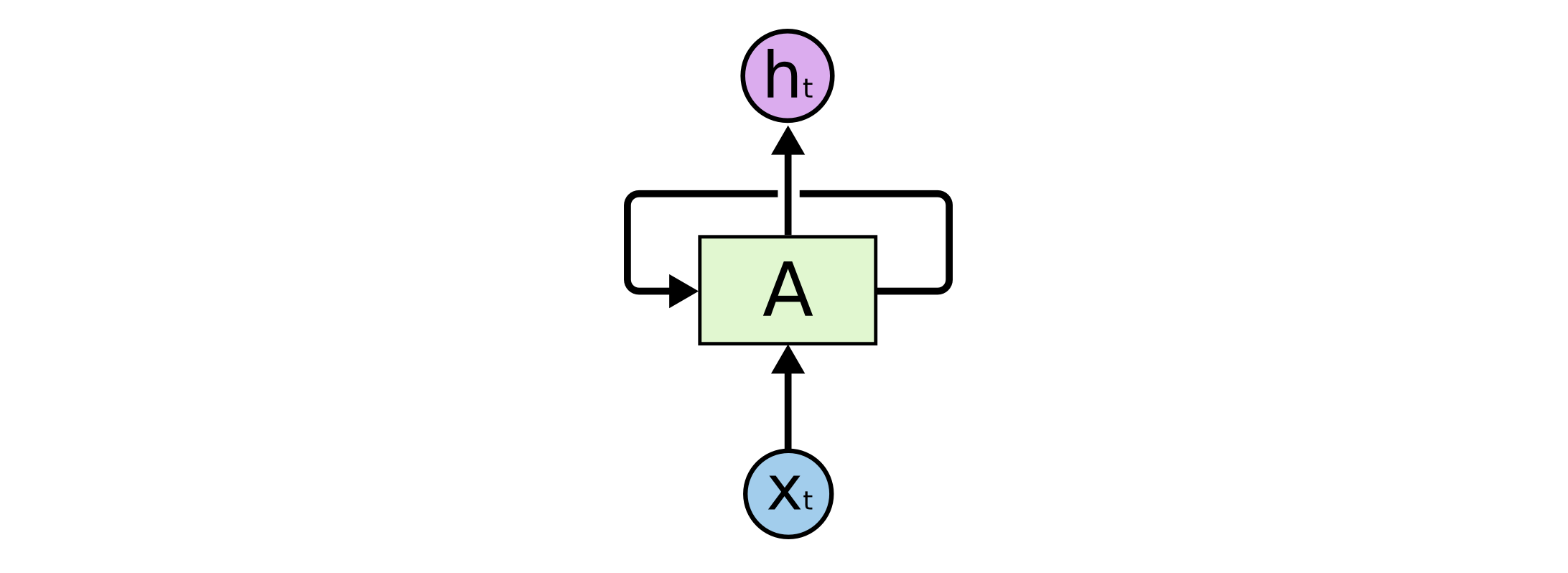
图 2. RNN 的循环单元
其中 \(x_t\) 表示输入序列中时刻 \(t\) 时的值, \(h_t\) 为该层在时刻 \(t\) 的输出. 方块 \(A\) 是一个操作符, 把前一时刻的输出 \(h_{t-1}\) 和当前时刻的输入 \(x_t\) 映射为当前时刻的输出. 注意, \(h_t\) 通常扮演两个角色, 既是循环单元在当前时刻的输出, 又是当前时刻循环单元的状态. 公式表示如下:
\[h_t = \sigma(W_{hx}x_t + W_{hh}h_{t-1}).\]其中 \(W\) 为权重参数, \(\sigma\) 表示激活函数, 常用的是 \(\tanh(\cdot)\) 函数, 可以把输出的值域控制在 \([-1, 1]\) 之间, 避免在循环过程中不收敛. 我们可以沿着时间轴把上面的循环单元展开, 更加直观.
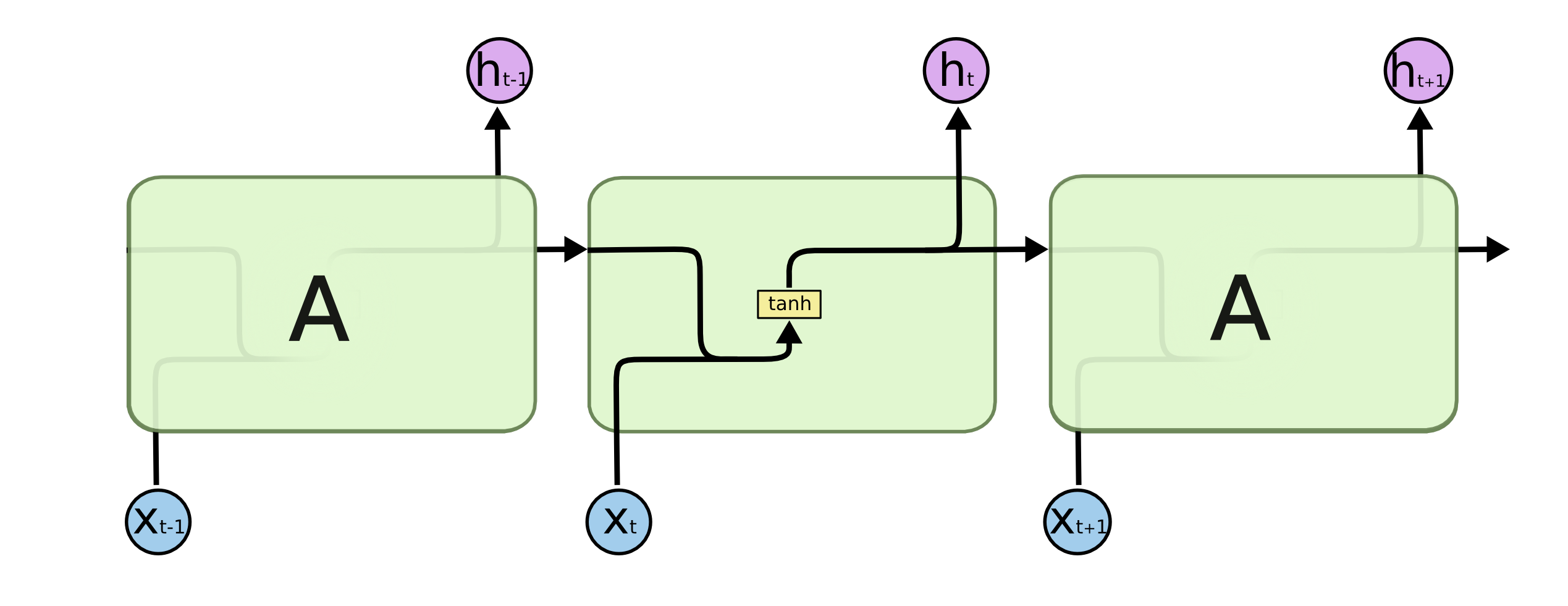
图 3. RNN 循环单元展开示意图
循环神经网络可以由多层循环单元堆叠而成, 前一个循环单元的输出作为下一循环单元的输入, 如下图所示.
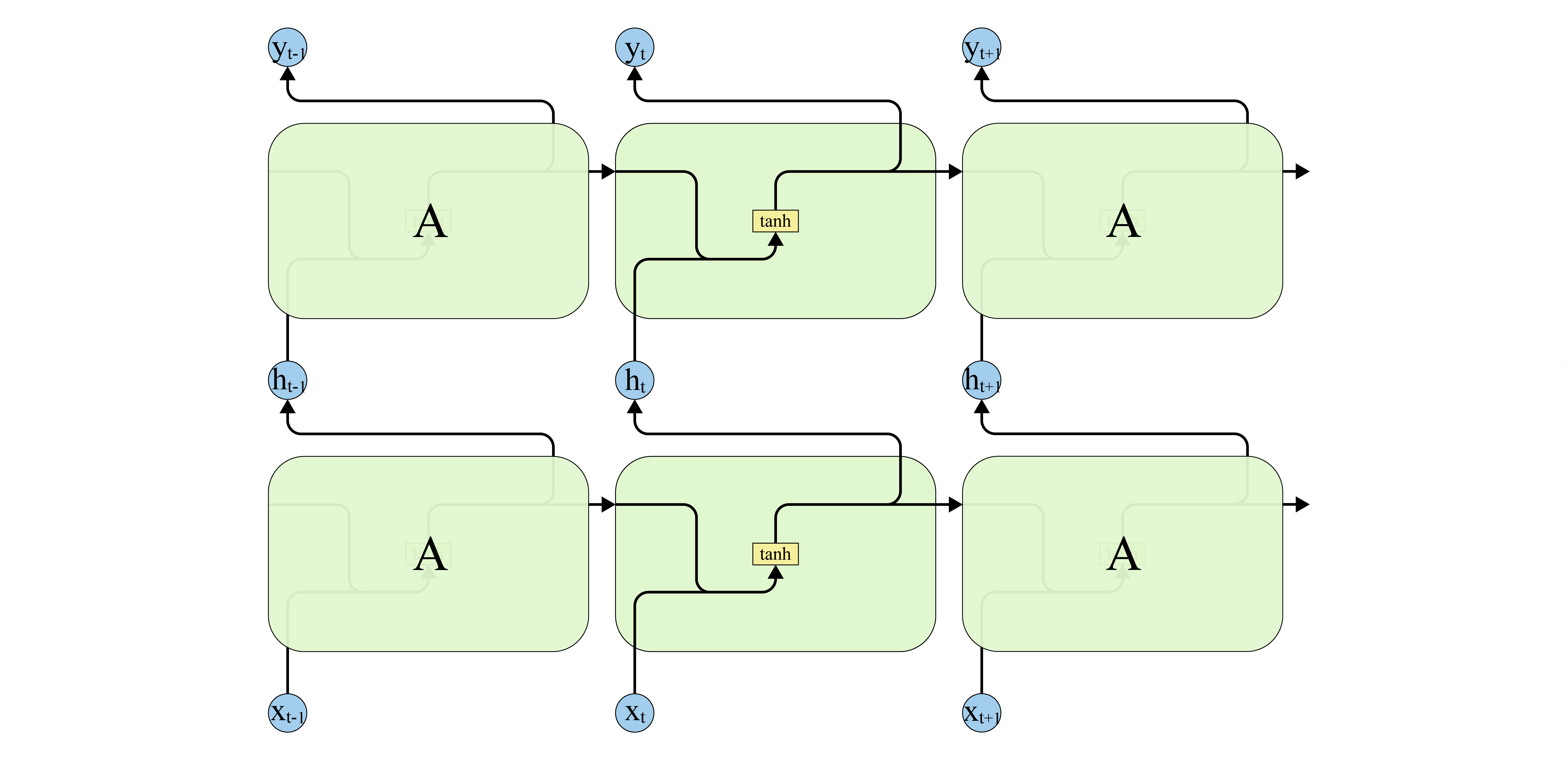
图 4. 多层循环单元堆叠
RNN 的输入通常表示成嵌入 (embedding)的形式, 即构造一个查询表 (lookup table), 把输入序列的每个时刻的特征向量通过查询表转为一个等长的向量. 从而一个序列的形状变为 [num_time_steps, embedding_size].
1.1 RNN 的应用
RNN 可以根据输入序列的长度和输出序列的长度分为三大类.
- 多对一: 常用于情感分析, 文本分类
- 一对多: Image Caption
- 多对多: 机器翻译
- 一对一: 退化为 MLP
1.2 RNN 的局限性
RNN 也存在一些缺陷:
- RNN 可以很好的学习序列中邻近时间步数据点(短期)之间的关系, 但对于长期依赖会变得不稳定.
- RNN 可以把固定长度的输入序列映射到指定长度的输出序列, 但不能动态地根据输入决定输出多长的序列.
而 LSTM 和 Encoder-Decoder 的提出解决了这两个问题.
2. 长短期记忆 (Long Short Term Memory, LSTM)1
前面提到, RNN 对于长期依赖经实验表明是不稳定的. 对于短序列, 如一个句子: “The clouds are in the ()”, 括号中预测一个词, 那么很容易根据该词前面的 clouds 和 in 推断出填 sky. 但是对于长序列, 如 “I grew up in France … I speak fluent ()”, 句子中的省略号包含了大量其他信息, 此时最后括号中的词应当根据开头的 France 推断为 French, 但中间大量的无用语句会稀释前期的信息, 导致 RNN 无法正确预测最后的词. 而 Hochreiter & Schmidhuber 提出的 LSTM 2 正是解决该问题的.
LSTM 和通常的 CNN 一样为一个循环单元的结构, 但是与 RNN 仅有一个 tanh 激活层不同, LSTM 中包含了更复杂的四层网络的结构设计, 并且四层网络相互耦合, 如下图所示.
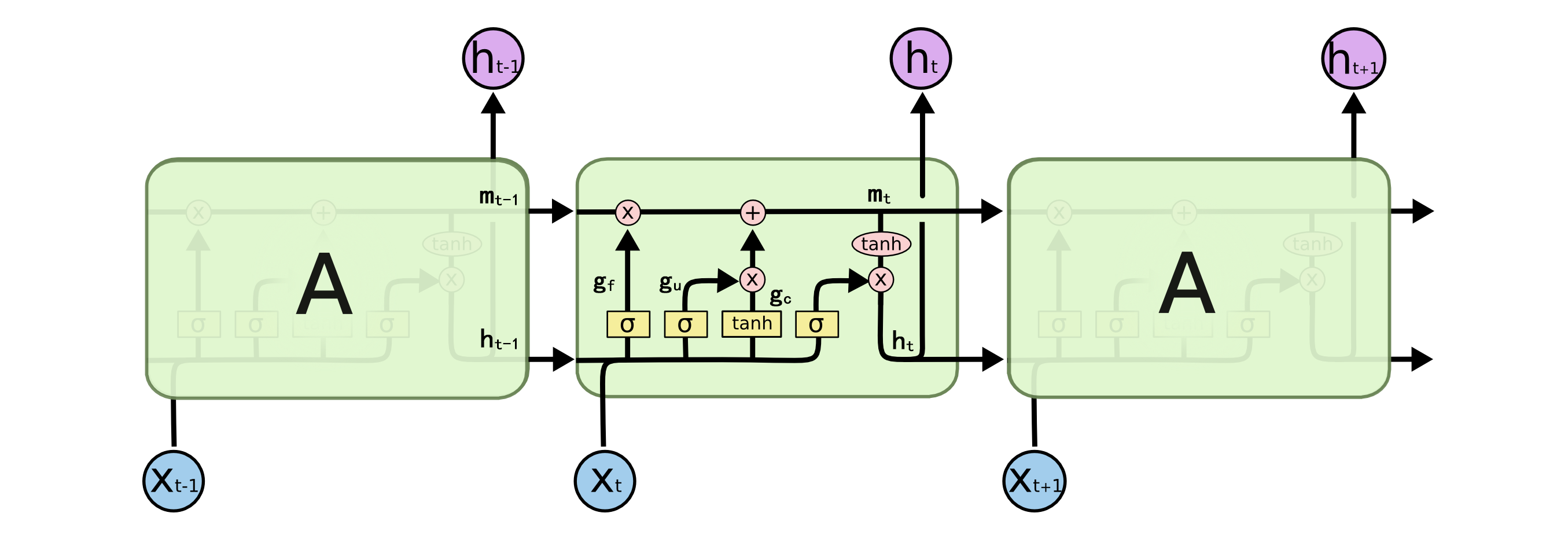
图 5. LSTM 循环单元展开示意图
上图中的圆角矩形框, 操作符, 分支箭头的含义如下图所示.

图 6. 图例
下面详细介绍 LSTM 单元的内部结构.
2.1 LSTM 的核心思想
LSTM 相比于 RNN, 关键在于引入了单元状态(state) \(C\) —— 横穿下图顶部的直线.
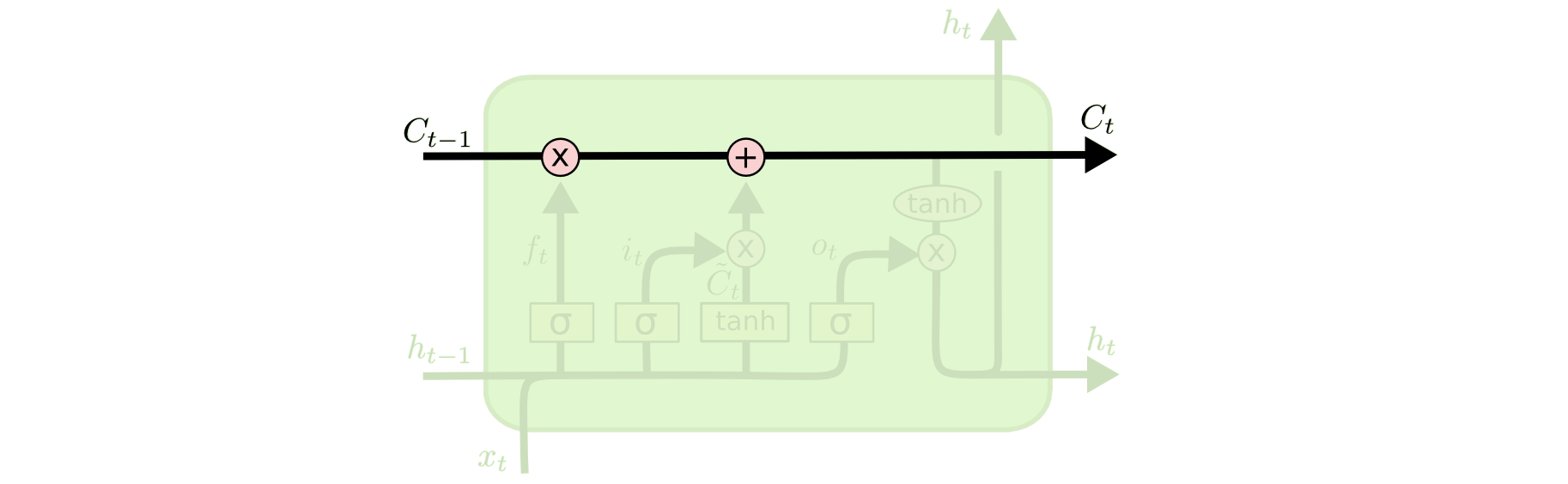
图 7. 单元状态
LSTM 可以通过门(gate)来控制向单元状态中增加信息或减少信息. 门由一个 \(sigmoid\) 函数和一个乘法运算符组成, 如下图所示.
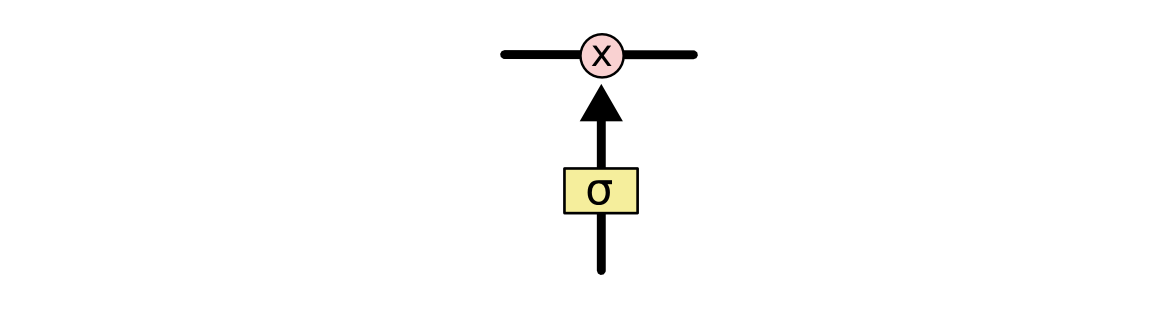
图 8. 门
\(sigmoid\) 层输出的值在 \([0, 1]\) 之间, 控制了信息的通过量. 越接近 0, 则表明不允许信息通过(从而形成遗忘); 越接近 1, 则表明允许信息全部通过(从而形成记忆).
2.2 LSTM 单元解析
LSTM 单元在每个时间步需要注意三个向量:
- 输入的特征向量 \(x_t\)
- 上一步输出的特征向量 \(h_{t-1}\)
- 上一步结束后的单元状态 \(C_{t-1}\)
要注意三个向量是相同的长度.
遗忘门(forget gate). 每循环一步时, 首先根据上一步的输出 \(h_{t-1}\) 和当前步的输入 \(x_t\) 来决定要遗忘掉上一步的什么信息(从单元状态 \(C_{t-1}\) 中遗忘). 因此只需要计算一个遗忘系数 \(f_t\) 乘到单元状态上即可. 如下图所示, 公式中的方括号表示 \(concat\) 操作.
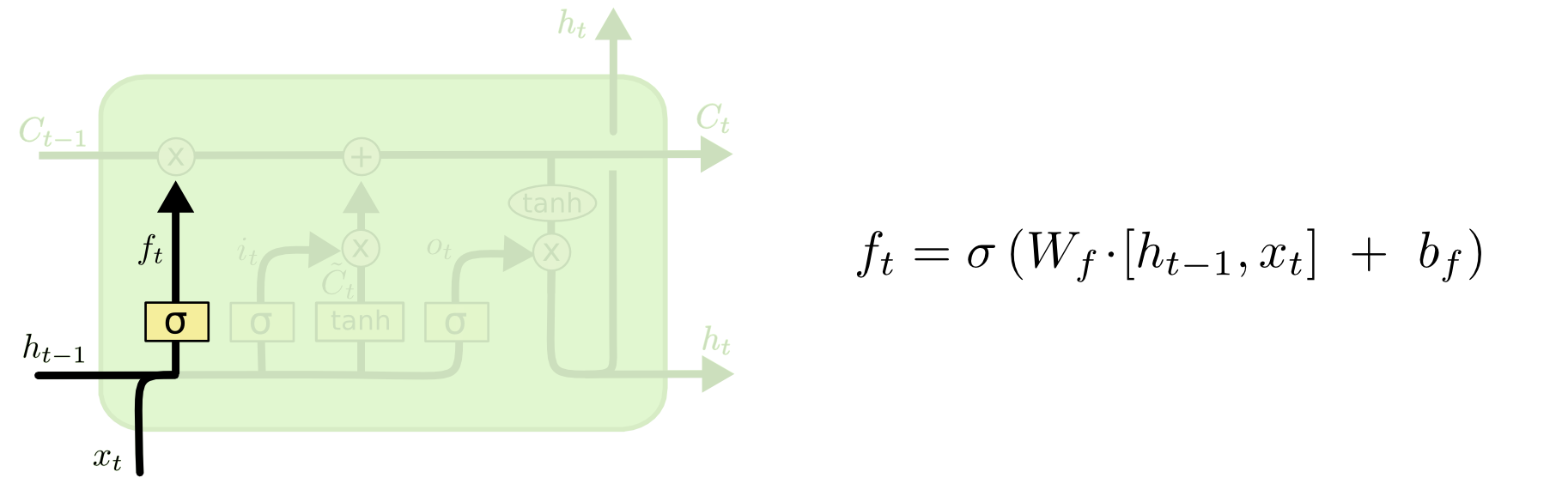
图 9. 遗忘门
输入门(input gate). 这一步来决定当前新的输入 \(x_t\) 我们应该把多少信息储存在单元状态中. 这部分有两步, 首先一个输入门计算要保留哪些信息, 得到过滤系数 \(i_t\), 然后使用一个全连接层来从上一步的输出 \(h_{t-1}\) 和当前步的输入 \(x_t\) 中提取特征 \(\tilde{C}_t\). 如下图所示.
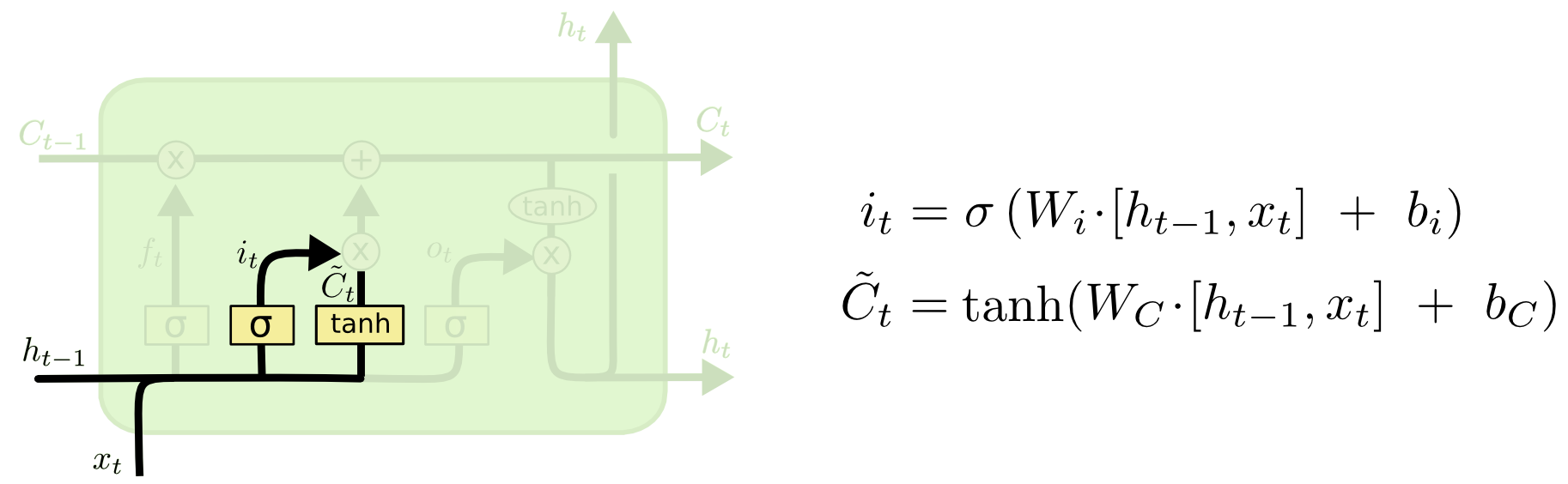
图 10. 输入门
新旧信息合并. 计算好了遗忘系数, 输入系数, 以及新的要记忆的特征, 现在就可以在单元状态 \(C_{t-1}\) 上执行遗忘操作 \(f_t\ast C_{t-1}\) 和记忆操作 \(+i_t\ast\tilde{C}_t\). 如下图所示.
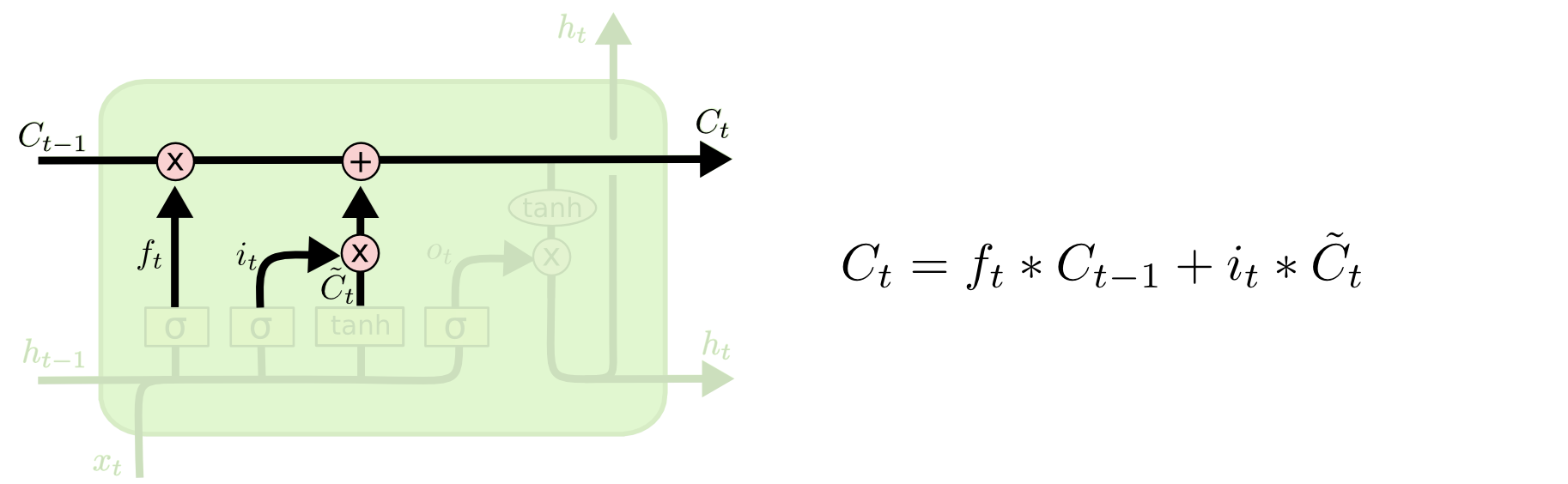
图 11. 新旧信息合并
输出门(output gate). 最后我们要决定输出什么信息了. 这需要从当前的单元状态 \(C_t\) 来获取要输出的信息. 但显然我们并不会在这一个时间步输出所有记忆的信息, 而是只要输出当前需要的信息, 因此我们用一个输出门来过滤输出的信息, 过滤系数为 \(o_t\). 此外我们希望输出的特征的取值能够介于 \([-1, 1]\) 之间, 因此使用一个 \(tanh\) 函数把单元状态 \(C_t\) 映射到相应的范围, 最后乘上过滤系数得到当前步的输出. 如下图所示.
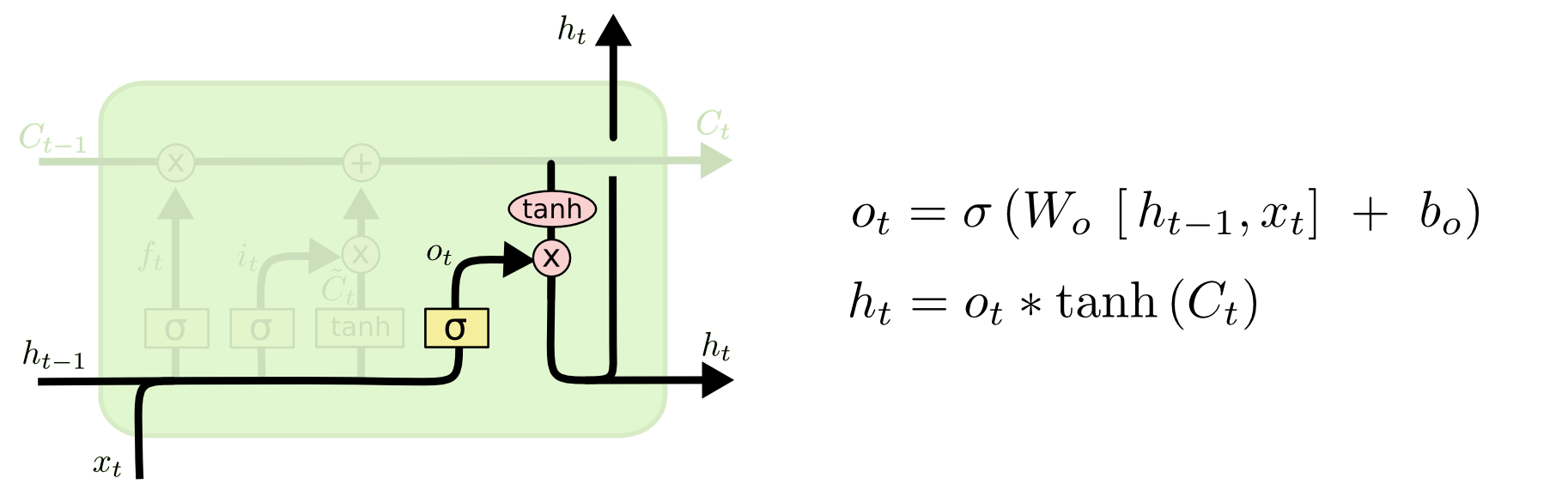
图 12. 输出门
2.3 LSTM 单元变体
变体一. 3让所有的门控单元在输出门控系数的时候都可以”看到”当前的单元状态. 如下图所示.
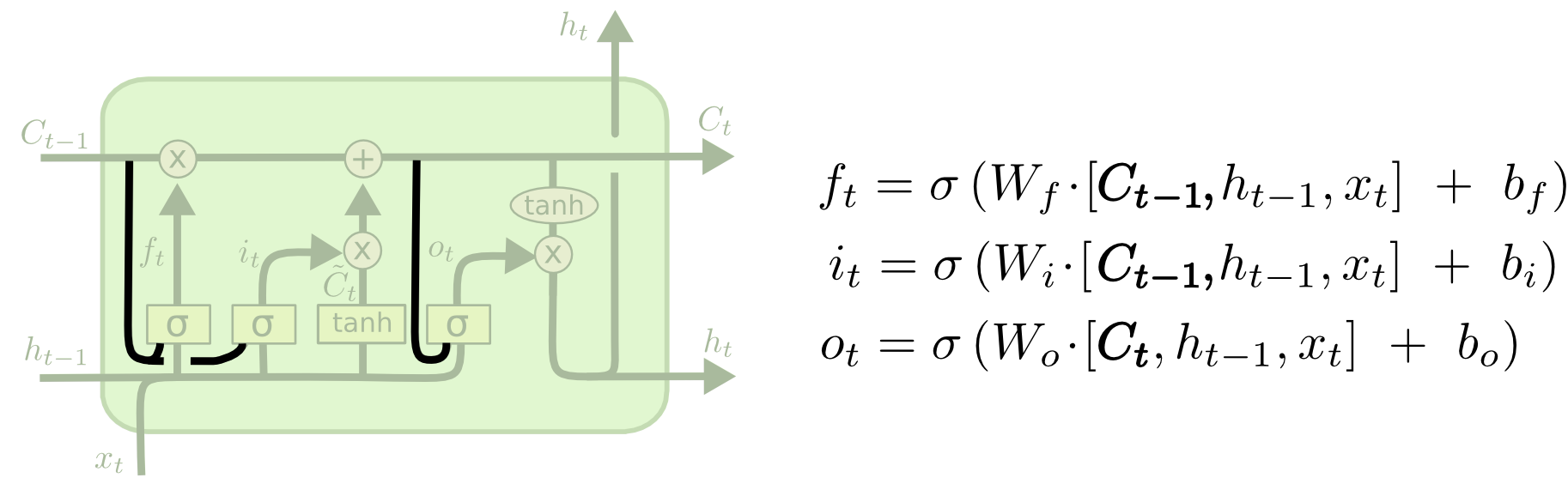
图 13. 让门控单元可以看到单元状态
变体二. 让遗忘门的遗忘系数 \(f_t\) 和输入门的输入系数 \(i_t\) 耦合, 即令 \(i_t = 1-f_t\), 从而同时做出哪些信息遗忘以及哪些信息记忆的决策. 这个变体可以让新的有用的记忆”覆盖”老的无用的记忆. 如下图所示.
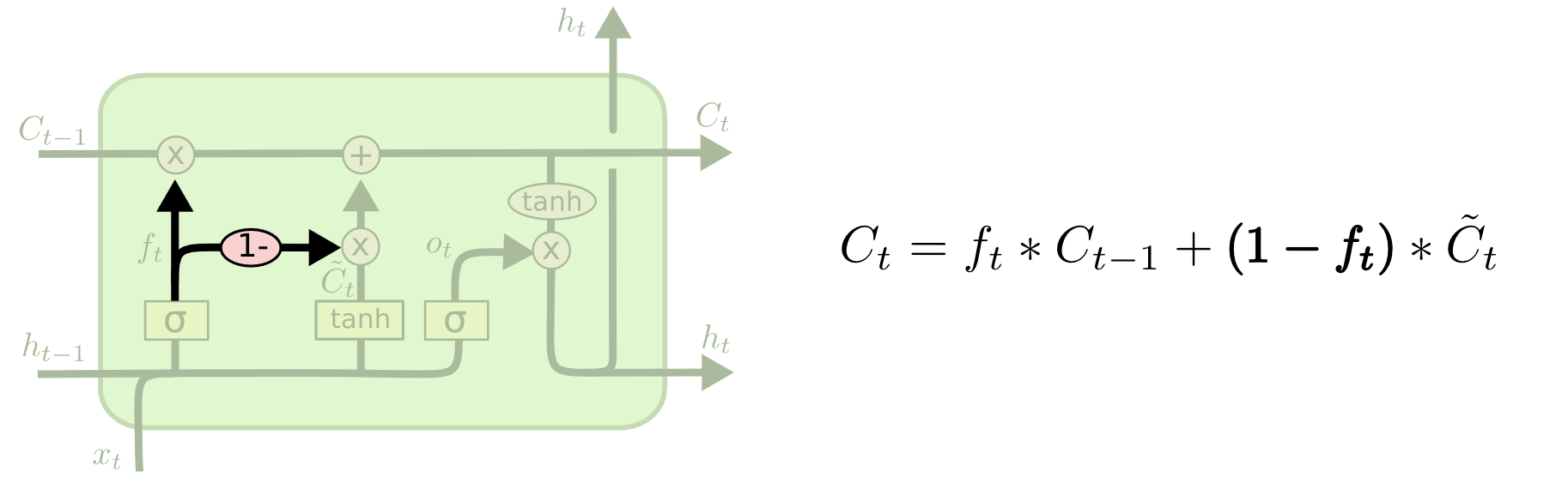
图 14. 遗忘系数和记忆系数耦合
变体三(GRU). 4第三种变体更为有名, 称为门控循环单元(Gated Recurrent Unit, GRU). 下一节介绍.
其他参考: 其他可以参考如下文献:
3. 门控循环单元(Gated Recurrent Unit, GRU)
GRU4 是一种比 LSTM 稍简单一些的循环单元. GRU 把 LSTM 中的隐藏状态 \(h\) 和单元状态 \(C\) 合并为单个的隐藏状态. 如下图所示.

图 15. 门控循环单元(GRU)
更新门(update gate). 更新门系数 \(z_t\) 控制了 \(h_{t-1}\) 中保存的信息(如长期记忆)在当前步保留多少. \(z_t\) 接近 0 时上一步的隐藏状态中的信息 \(h_{t-1}\) 得以保留, 新输入的信息 \(\tilde{h}_t\) 会被忽略; \(z_t\) 接近 1 时则丢弃已有的信息, 并填入新输入的信息.
输入信息的加工. 当前步输入的信息需要加工后才能合并到隐藏状态 \(h_t\) 中. 输入信息加工时需要参考上一步的隐藏状态 \(h_{t-1}\) 来决定哪些信息有用, 哪些没用. 加工后的信息用 \(\tilde{h}_t\) 表示.
重置门(reset gate). 重置门系数 \(r_t\) 控制了在加工输入信息的时候使用上一步的隐藏状态中的哪些信息. \(r_t\) 接近 0 时新输入的信息占主导地位, 说明当前步的输入包含的信息与前面的信息关联性很小; \(r_t\) 接近 1 时新输入的信息和前面的长期信息有较大关联性, 需要综合考虑来产生当前步加工后的信息.
4. 编码-解码器 (Encoder-Decoder)
编码-解码器模型是为了实现 \(n\rightarrow m\) 序列映射的模型框架. 这类模型也称为 Sequence to Sequence(seq2seq). 编码器只负责处理输入序列, 并形成输入序列的特征向量后送入解码器. 为了清楚, 我们用公式来表示这个过程5. 对于输入序列 \(X=\{x_1, x_2, \cdots, x_S\}\) 和期望的输出序列 \(Y=\{y_1, y_2, \cdots, y_T\}\), 我们使用 RNN 模型对其进行建模, 形成一个条件概率 \(P(Y\vert X)\), 使用链式法则解耦如下:
\[P(Y|X) = \prod_{t=1}^TP(y_t\lvert y_1, y_2, \cdots, y_{t-1}, X).\]那么该 RNN 模型就是一个编码器, 在时刻 \(s\) 的状态通过下式计算:
\[h_s = f_{enc}(h_{s-1}, x_s).\]编码器的示意图如下图6所示:
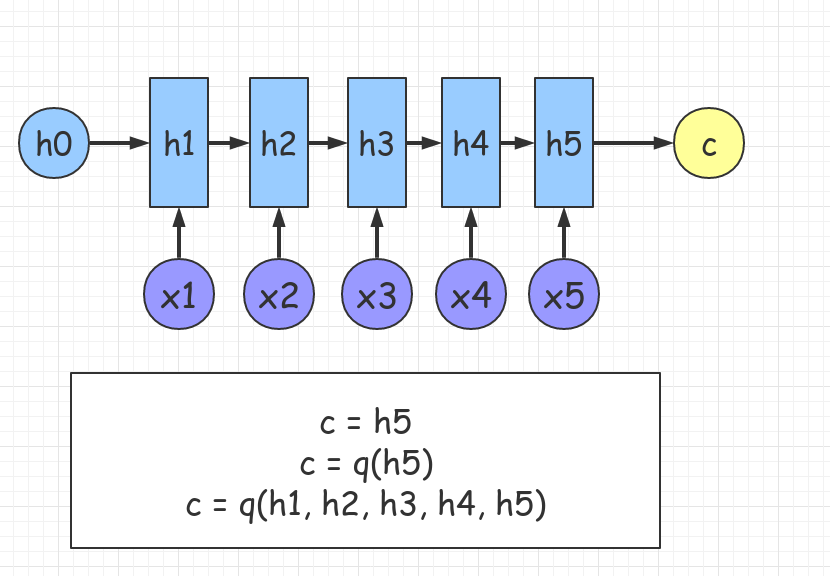
图 16. 编码器. 输出的中间状态(语义向量) $$ c $$ 可以通过不同的计算公式构造, 形成不同的模型结构.
解码器 RNN 每个时间步使用前一步的输出 \(y_{t-1}\) 和当前状态 \(g_t\) 产生一个输出 \(y_t\in Y\):
\[\begin{align} g_1 &= h_s \\ g_t &= f_{dec}(g_{t-1}, y_{t-1}) \end{align}\]每个时间步的输出概率通过一个线性层和一个 softmax 函数得到:
\[P(y_t\lvert y_1, y_2, \cdots, y_{t-1}, X) = Softmax(Linear(g_t)).\]使用解码器对语义向量解码. 如果把语义向量只输入解码器的第一个循环时间步, 则形成了 Cho et al.7 提出的结构.
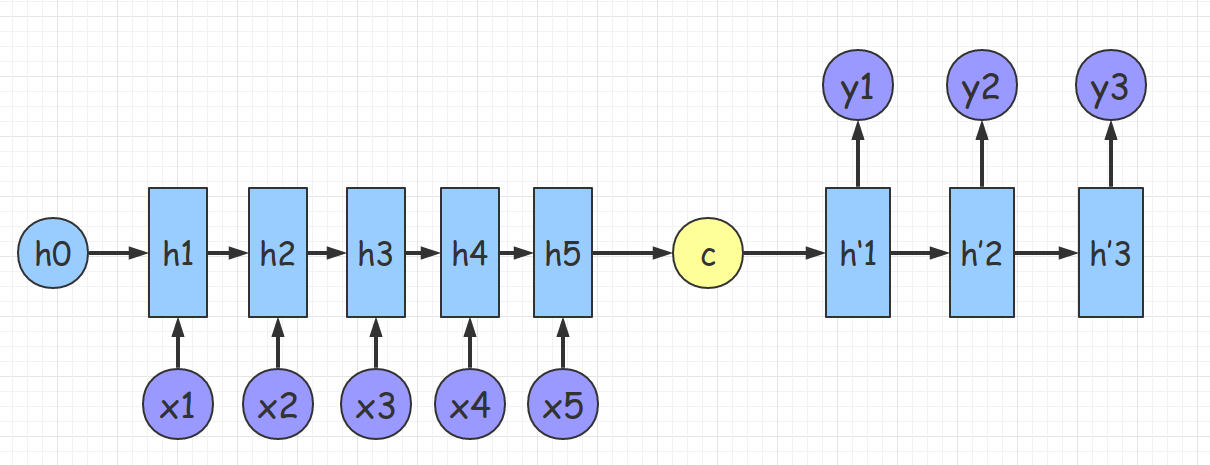
图 17. 解码器-1
如果把语义向量在每一个时间步都输入解码器, 则形成了 Sutskever et al.8 提出的结构.
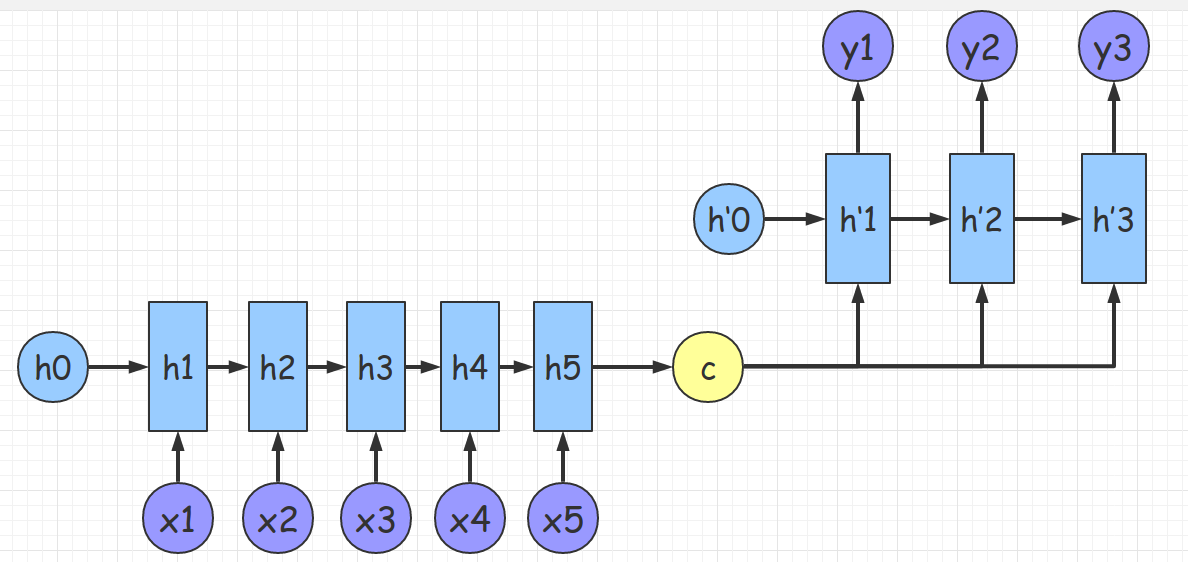
图 18. 解码器-2
4.1 编码-解码器模型的局限性
- 信息的丢失: 整个时间序列只能压缩为一个固定长度的语义向量
- 不合理性: seq2seq 的任务中输入序列 \(\{x_0, x_1, \dots, x_{t−1}, x_𝑡, x_{t+1},\dots \}\) 中的每个元素对所有 \(y_s\) 的贡献度是相同的
例如: The animal didn’t cross the street because it was too tired. 在这句话中, 人是通过综合整句话的信息来判断单词 it 指代的是 the animal, 从而翻译时 the animal 应该对 it 的影响更大.
人们提出了注意力模型来解决普通编码-解码器模型的问题.
5. 注意力机制 (Attention Mechanism)9
5.1 什么是注意力?
心理学中对注意力的解释是:
Attention is the behavioral and cognitive process of selectively concentrating on a discrete aspect of information, whether deemed subjective or objective, while ignoring other perceivable information.
注意力是把有限的资源集中在更重要的目标上. 注意力机制的两个要素:
- 决定输入信息的哪部分是重要的
- 把资源集中分配到重要的信息上
沿用编码-解码器模型的结构, 注意力机制通过引入一组归一化的系数 \(\{\alpha_1, \alpha_2, \dots, \alpha_n \}\) 来对输入的信息进行选择, 来解决编码-解码器的不合理性. 这里输入的信息就是指输入序列在 RNN 中的单元输出 \(\mathbf{h}_s\). 归一化的系数 \(\alpha_s\) 用来决定输入信息的重要性, 是编码器输出时对单元输出加权求和系数. 注意力机制在计算不同时间步的输出时, 实时构造编码器输出的语义向量 \(\mathbf{c}_t\), 从而解决了普通编码-解码器信息丢失的问题. 注意力机制如下图所示.
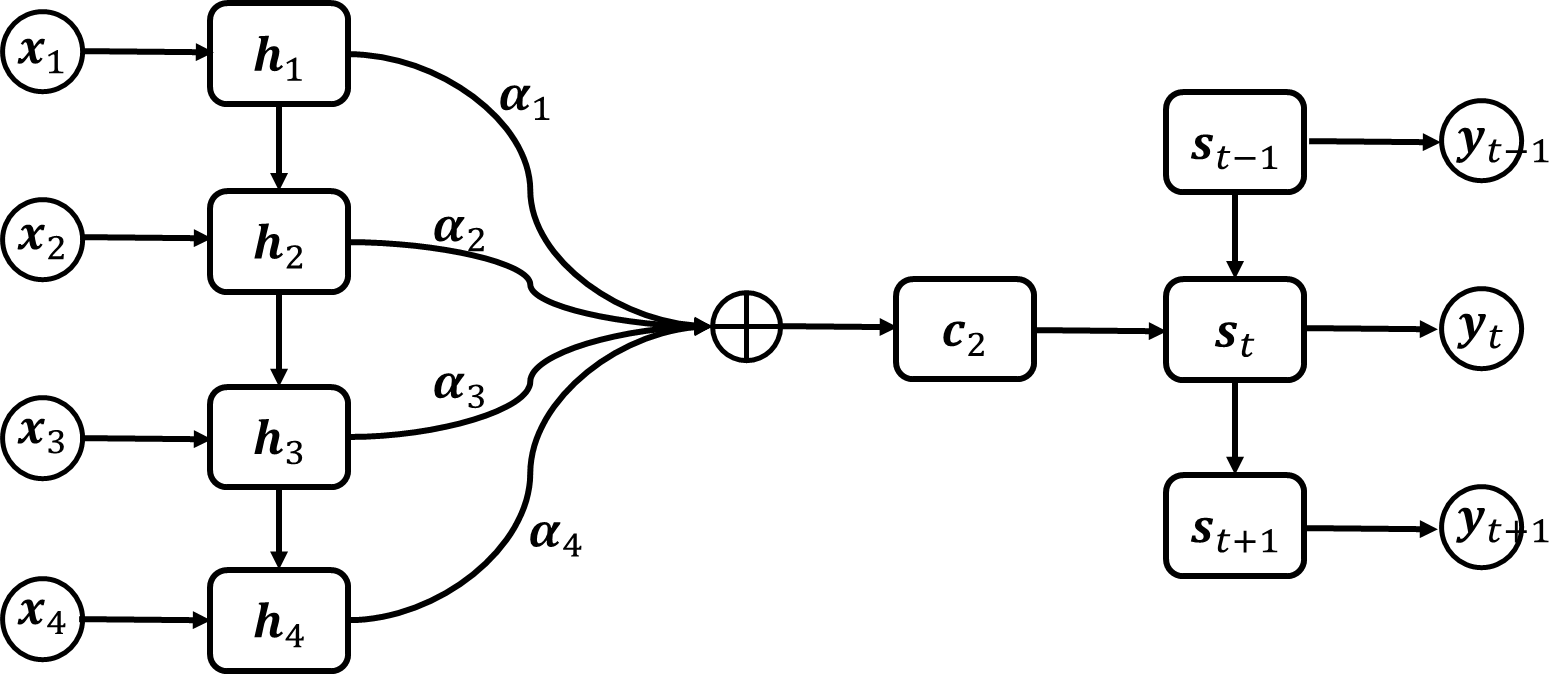
图 19. 注意力机制
下面讨论加权系数是如何计算的. 考虑到加权系数要反映输入信息在当前时间步上的重要性, 因此需要把输入信息和时间信息结合起来计算加权系数. 因此通常使用一个 MLP 接收输入信息 \(\mathbf{h}_1, \mathbf{h}_2, \dots, \mathbf{h}_n\) 和解码器上一时刻的状态 \(\mathbf{s}_{t-1}\) 作为输入, 输出归一化的加权系数 \(\alpha_{t1}, \alpha_{t2}, \dots, \alpha_{tn}\). 如下图所示.
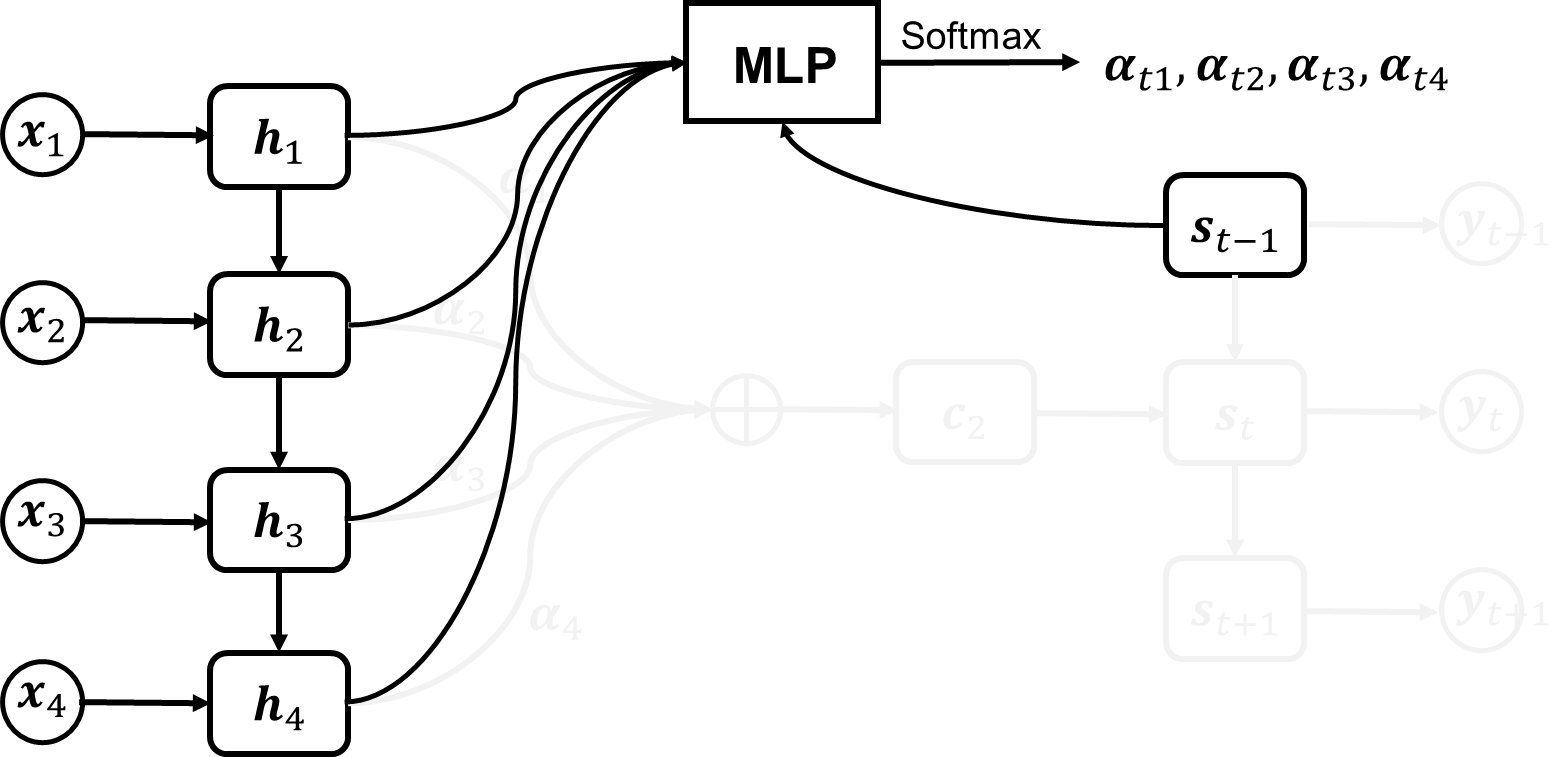
图 20. 注意力机制
注意: 编码-解码器的结构只是注意力机制的一个载体, 注意力机制的核心在于加权系数, 因此可以用于非 RNN 的结构.
5.2 自注意力 (Self-Attention)
自注意力是一个神经网络模块, 它仍然是使用了注意力机制, 与编码-解码器结构不同的是, 自注意力模块只使用输入的信息计算加权系数, 而不需要上一个时间步的信息, 因此可以实现更大规模的并行计算. Google 在 2017 年提出的 Transformer 实现了可并行的自注意力模块10. 其结构如下图所示.
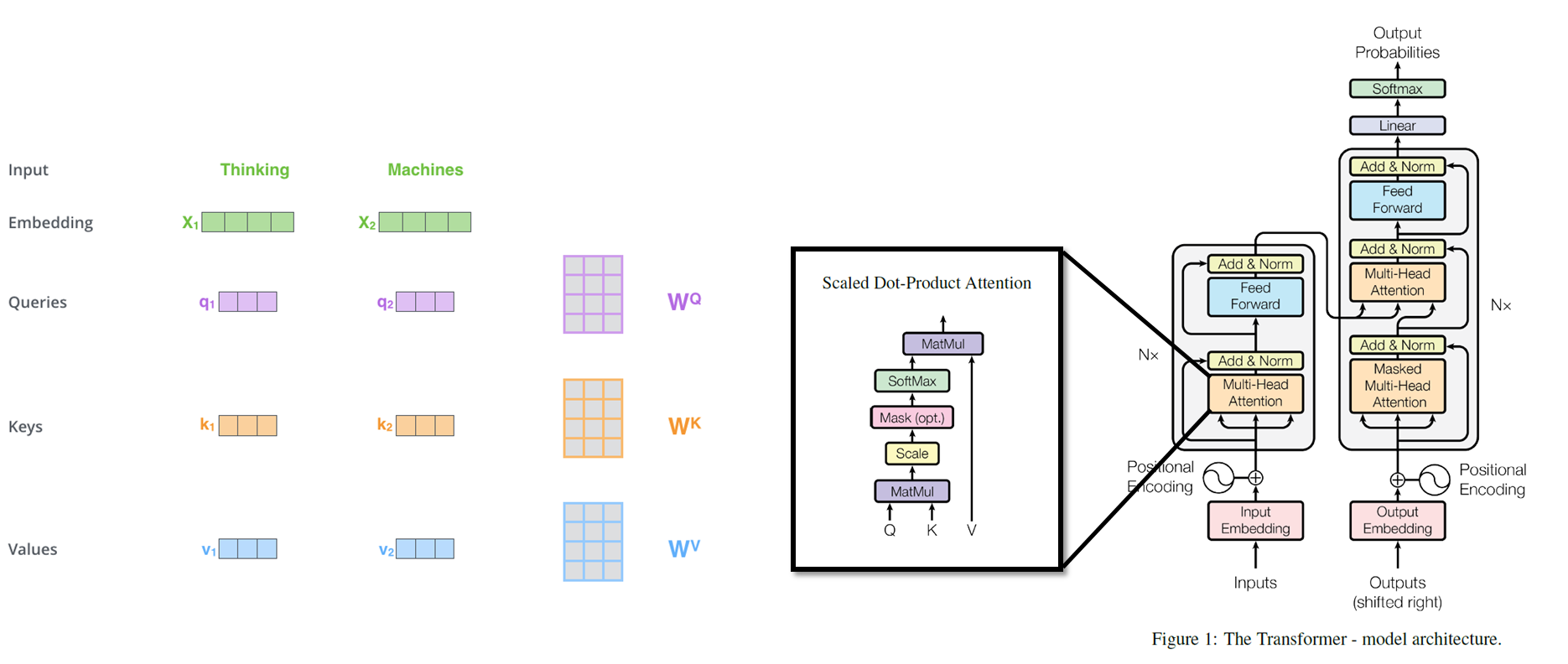
图 21. 语言翻译任务中的自注意力
自注意力模块工作方式如下11:
- 输入的序列首先转化为相同长度的 embedding
- 创建三个矩阵: 查询矩阵 (Query), 键矩阵 (Key), 值矩阵 (Value)
- 使用这三个矩阵把每个单词的 embedding 映射为三个稍短的特征向量, 分别代表了当前单词的查询向量, 键向量和值向量.
- 比如我们要计算单词 Thinking 关于句子中其他单词的注意力时, 使用 Thinking 的查询向量依次与句子中所有单词 (包括 Thinking) 的键向量做点积来计算相似度, 并对相似度进行归一化得到加权系数 (这是 attention 的核心部分).
- 加权系数乘到所有单词的值向量上来得到单词 Thinking 经过自注意力模块后输出的特征向量, 这个特征向量中可以看作包含了翻译任务重对准确翻译 Thinking 所需要的信息, 而不包含其他信息 (其他信息在翻译其他词时可能有用, 但在翻译 Thinking 时无用).
6. tensorflow 官方代码解析
修改为 tensorflow r1.4 版本
分段讲解
总的来看,这份代码主要由三步分组成。 第一部分,是PTBModel,也是最核心的部分,负责tf中模型的构建和各种操作(op)的定义。 第二部分,是run_epoch函数,负责将所有文本内容分批喂给模型(PTBModel)训练。 第三部分,就是main函数了,负责将第二部分的run_epoch运行多遍,也就是说,文本中的每个内容都会被重复多次的输入到模型中进行训练。随着训练的进行,会适当的进行一些参数的调整。 下面就按照这几部分来分开讲一下。我在后面提供了完整的代码,所以可以将完整代码和分段讲解对照着看。
参数设置
在构建模型和训练之前,我们首先需要设置一些参数。tf中可以使用 tf.flags 来进行全局的参数设置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
flags = tf.flags
logging = tf.logging
flags.DEFINE_string( # 定义变量 model的值为small, 后面的是注释
"model", "small",
"A type of model. Possible options are: small, medium, large.")
flags.DEFINE_string("data_path", #定义下载好的数据的存放位置
'/home/multiangle/download/simple-examples/data/',
"data_path")
flags.DEFINE_bool("use_fp16", False, # 是否使用 float16格式?
"Train using 16-bit floats instead of 32bit floats")
FLAGS = flags.FLAGS # 可以使用FLAGS.model来调用变量 model的值。
def data_type():
return tf.float16 if FLAGS.use_fp16 else tf.float321234567891011121314151617
细心的人可能会注意到上面有行代码定义了 model 的值为 small.这个是什么意思呢?其实在后面的完整代码部分可以看到,作者在其中定义了几个参数类,分别有 small,medium,large 和 test 这 4 种参数。如果 model 的值为small,则会调用 SmallConfig,其他同样。在 SmallConfig 中,有如下几个参数:
1
2
3
4
5
6
7
8
9
10
11
12
init_scale = 0.1 # 相关参数的初始值为随机均匀分布,范围是[-init_scale,+init_scale]
learning_rate = 1.0 # 学习速率,在文本循环次数超过max_epoch以后会逐渐降低
max_grad_norm = 5 # 用于控制梯度膨胀,如果梯度向量的L2模超过max_grad_norm,则等比例缩小
num_layers = 2 # lstm层数
num_steps = 20 # 单个数据中,序列的长度。
hidden_size = 200 # 隐藏层中单元数目
max_epoch = 4 # epoch<max_epoch时,lr_decay值=1,epoch>max_epoch时,lr_decay逐渐减小
max_max_epoch = 13 # 指的是整个文本循环次数。
keep_prob = 1.0 # 用于dropout.每批数据输入时神经网络中的每个单元会以1-keep_prob的概率不工作,可以防止过拟合
lr_decay = 0.5 # 学习速率衰减
batch_size = 20 # 每批数据的规模,每批有20个。
vocab_size = 10000 # 词典规模,总共10K个词123456789101112
其他的几个参数类中,参数类型都是一样的,只是参数的值各有所不同。
PTBModel
这个可以说是核心部分了。而具体来说,又可以分成几个小部分:
- 多层LSTM结构的构建
- 输入预处理
- LSTM的循环
- 损失函数计算
- 梯度计算
- 修剪
1.1 LSTM结构
1
2
3
4
5
6
7
8
9
class PTBInput(object):
"""The input data."""
def __init__(self, config, data, name=None):
self.batch_size = batch_size = config.batch_size
self.num_steps = num_steps = config.num_steps
self.epoch_size = ((len(data) // batch_size) - 1) // num_steps
self.input_data, self.targets = reader.ptb_producer(
data, batch_size, num_steps, name=name) # 该类主要作用是这句, 从文件中读取数据
self.input_data 和 self.targets 都是 index 的序列, 尺寸为 [batch_size, num_steps]. 注意此时不论是input还是target都是用词典id来表示单词的。
PTBModel.__init__() 函数:
1
2
3
4
5
6
self._input = input_ # [batch_size, num_steps]
batch_size = input_.batch_size
num_steps = input_.num_steps
size = config.hidden_size # 隐藏层规模
vocab_size = config.vocab_size # 词典规模
引进参数.
1
2
3
4
5
6
7
8
9
10
def lstm_cell():
if 'reuse' in inspect.getargspec(tf.contrib.rnn.BasicLSTMCell.__init__).args:
return tf.contrib.rnn.BasicLSTMCell(size,
forget_bias=0.0,
state_is_tuple=True,
reuse=tf.get_variable_scope().reuse)
else:
return tf.contrib.rnn.BasicLSTMCell(size,
forget_bias=0.0,
state_is_tuple=True)
首先使用 tf.contrib.rnn.BasicLSTMCell 定义单个基本的 LSTM 单元。这里的 size 其实就是隐藏层规模。
从源码中可以看到,在 LSTM 单元中,有 2 个状态值,分别是 c 和 h,分别对应于下图中的 c 和 h。其中 h 在作为当前时间段的输出的同时,也是下一时间段的输入的一部分。

图 22. LSTM 单元
那么当 state_is_tuple=True 的时候,state 是元组形式,state=(c,h)。如果是 False,那么 state 是一个由c和h拼接起来的张量,state=tf.concat(1, [c,h])。在运行时,则返回2值,一个是h,还有一个state。
1.2 DropoutWrapper
1
2
3
4
attn_cell = lstm_cell
if is_training and config.keep_prob < 1: # 在外面包裹 dropout
def attn_cell():
return tf.contrib.rnn.DropoutWrapper(lstm_cell(), output_keep_prob=config.keep_prob)
我们在这里使用了 dropout 方法。所谓 dropout, 就是指网络中每个单元在每次有数据流入时以一定的概率(keep prob)正常工作,否则输出0值。这是是一种有效的正则化方法,可以有效防止过拟合。在 rnn 中使用 dropout 的方法和 cnn 不同,推荐大家去把 recurrent neural network regularization 看一遍。 在 rnn 中进行 dropout 时,对于 rnn 的部分不进行 dropout,也就是说从 t-1 时候的状态传递到t时刻进行计算时,这个中间不进行 memory 的 dropout;仅在同一个t时刻中,多层 cell 之间传递信息的时候进行 dropout,如下图所示

图 23. 循环神经元展开示意图
上图中,\(t-2\) 时刻的输入 \(x_{t−2}\) 首先传入第一层 cell,这个过程有 dropout,但是从 \(t−2\) 时刻的第一层 cell 传到 \(t−1, t, t+1\) 的第一层 cell 这个中间都不进行 dropout。再从 \(t+1\) 时候的第一层 cell 向同一时刻内后续的 cell 传递时,这之间又有 dropout 了。
在使用 tf.contrib.rnn.DropoutWrapper 时,同样有一些参数,例如 input_keep_prob, output_keep_prob 等,分别控制输入和输出的dropout概率,很好理解。
1.3 多层LSTM结构和状态初始化
1
2
3
4
cell = tf.contrib.rnn.MultiRNNCell([attn_cell() for _ in range(config.num_layers)],
state_is_tuple=True)
# 参数初始化,rnn_cell.RNNCell.zero_stat
self._initial_state = cell.zero_state(batch_size, data_type())
在这个示例中,我们使用了 2 层的 LSTM 网络。也就是说,前一层的 LSTM 的输出作为后一层的输入。使用tf.contrib.rnn.MultiRNNCell 可以实现这个功能。这个基本没什么好说的,state_is_tuple 用法也跟之前的类似。构造完多层 LSTM 以后,使用 zero_state 即可对各种状态进行初始化。
2. 输入预处理
1
2
3
4
5
6
7
8
9
10
11
12
13
with tf.device("/cpu:0"):
# 把描述单词的指标 idx ([1, 1]) 变为 embedding ([1, hidden_size]) 描述
# 使用 embedding 描述可以让网络从描述中学习单词之间的关联, 否则单个的指标之间是独立的, 无法学习关联 ???
embedding = tf.get_variable("embedding", [vocab_size, size], dtype=data_type())
# 将输入的每个 sequence ([batch_size, num_steps]) 用 embedding 表示
# shape = [batch_size, num_steps, hidden_size]
# 所以每个 x_t 都是一个 batch_size x 1 x hidden_size 的向量
# 在程序里 1 自动省去, 所以每个 x_t 实际上是 [batch_size, hidden_size] 的向量
inputs = tf.nn.embedding_lookup(embedding, input_.input_data)
if is_training and config.keep_prob < 1:
inputs = tf.nn.dropout(inputs, config.keep_prob)
之前有提到过,输入模型的 input 和 target 都是用词典 id 表示的。例如一个句子,“我/是/学生”,这三个词在词典中的序号分别是 0,5,3,那么上面的句子就是 [0,5,3]。这样就和隐藏层需要的输入维度不匹配 (输入需要长度为 hidden_size 的向量),我们要把词典 id 转化成向量,也就是 embedding 形式。可能有些人已经听到过这种描述了。实现的方法很简单。
第一步,构建一个矩阵,就叫 embedding 好了,尺寸为 [vocab_size, embedding_size],分别表示词典中单词数目,以及要转化成的向量的维度。一般来说,向量维度越高,能够表现的信息也就越丰富。注意这里的 embedding 变量是使用均匀分布随机初始化的, 初始化器定义在 main 函数中. 并且 embedding 是变量矩阵, 在训练过程中是进行优化的, 期望是让有关联的词语对应的 embedding 向量形成某种关系.
第二步,使用 tf.nn.embedding_lookup(embedding,input_ids) 假设 input_ids 的长度为 len,那么返回的张量尺寸就为 [len,embedding_size]。
举个栗子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 示例代码
import tensorflow as tf
import numpy as np
sess = tf.InteractiveSession()
embedding = tf.Variable(np.identity(5,dtype=np.int32))
input_ids = tf.placeholder(dtype=tf.int32,shape=[None])
input_embedding = tf.nn.embedding_lookup(embedding,input_ids)
sess.run(tf.initialize_all_variables())
print(sess.run(embedding))
#[[1 0 0 0 0]
# [0 1 0 0 0]
# [0 0 1 0 0]
# [0 0 0 1 0]
# [0 0 0 0 1]]
print(sess.run(input_embedding,feed_dict={input_ids:[1,2,3,0,3,2,1]}))
#[[0 1 0 0 0]
# [0 0 1 0 0]
# [0 0 0 1 0]
# [1 0 0 0 0]
# [0 0 0 1 0]
# [0 0 1 0 0]
# [0 1 0 0 0]]
第三步,如果 keep_prob<1, 那么还需要对输入进行 dropout。不过这边跟 rnn 的 dropout 又有所不同,这边使用 tf.nn.dropout。
3. LSTM循环
现在,多层 lstm 单元已经定义完毕,输入也已经经过预处理了。那么现在要做的就是将数据输入lstm进行训练了。其实很简单,只要按照文本顺序依次向cell输入数据就好了。lstm上一时间段的状态会自动参与到当前时间段的输出和状态的计算当中。
1
2
3
4
5
6
7
8
9
10
11
12
13
outputs = []
state = self._initial_state # state 表示 各个batch中的状态
with tf.variable_scope("RNN"):
for time_step in range(num_steps):
if time_step > 0: tf.get_variable_scope().reuse_variables()
# 输入: [batch_size, hidden_size]
# 按照顺序向cell输入文本数据, cell_out: [batch_size, hidden_size]
(cell_output, state) = cell(inputs[:, time_step, :], state)
outputs.append(cell_output) # output: [num_steps][batch_size, hidden_size]
# 把之前的list展开,成 [batch, num_steps, hidden_size]
# 然后 reshape 成 [batch*numsteps, hidden_size], 这是为了后面 softmax 层计算方便
output = tf.reshape(tf.stack(axis=1, values=outputs), [-1, size])
这边要注意,tf.get_variable_scope().reuse_variables() 这行代码不可少,因为在 num_steps 的循环中实际上是在相同的权重上更新的
4. 损失函数计算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# softmax_w , shape=[hidden_size, vocab_size], 用于将distributed表示的单词转化为one-hot表示
softmax_w = tf.get_variable("softmax_w", [size, vocab_size], dtype=data_type())
softmax_b = tf.get_variable("softmax_b", [vocab_size], dtype=data_type())
# [batch*numsteps, vocab_size] 从隐藏语义转化成完全表示
logits = tf.matmul(output, softmax_w) + softmax_b
# loss , shape=[batch*num_steps], 带权重的交叉熵计算
loss = tf.contrib.seq2seq.sequence_loss(
logits, # [batch*numsteps, vocab_size]
input_.targets, # [batch_size, num_steps]
tf.ones([batch_size, num_steps], dtype=data_type()), # weight
average_across_timesteps=False,
average_across_batch=True # loss = loss / batch_size
)
self._cost = cost = tf.reduce_sum(loss)
self._final_state = state
上面代码的上半部分主要用来将多层lstm单元的输出转化成one-hot表示的向量。关于one-hot presentation和distributed presentation的区别,可以参考 这里
代码的下半部分,正式开始计算损失函数。这里使用了 tf 提供的现成的交叉熵计算函数, tf.contrib.seq2seq.sequence_loss。不知道交叉熵是什么?见这里. 各个变量的具体shape我都在注释中标明了。注意其中的 self._targets 是词典 id 表示的。这个函数的具体实现方式不明。我曾经想自己手写一个交叉熵,不过好像 tf 不支持对张量中单个元素的操作。
5. 梯度计算
之前已经计算得到了每批数据的平均误差。那么下一步,就是根据误差来进行参数修正了。当然,首先必须要求梯度
1
2
self._lr = tf.Variable(0.0, trainable=False) # lr 指的是 learning_rate
tvars = tf.trainable_variables()
通过 tf.trainable_variables 可以得到整个模型中所有 trainable = True 的 Variable。实际得到的 tvars 是一个列表,里面存有所有可以进行训练的变量。
1
2
grads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars),
config.max_grad_norm)
这一行代码其实使用了两个函数,tf.gradients 和 tf.clip_by_global_norm。 我们一个一个来。
tf.gradients 用来计算导数。该函数的定义如下所示
1
2
3
4
5
6
7
def gradients(ys,
xs,
grad_ys=None,
name="gradients",
colocate_gradients_with_ops=False,
gate_gradients=False,
aggregation_method=None):
虽然可选参数很多,但是最常使用的还是ys和xs。根据说明得知,ys和xs都可以是一个tensor或者tensor列表。而计算完成以后,该函数会返回一个长为len(xs)的tensor列表,列表中的每个tensor是ys中每个值对xs[i]求导之和。如果用数学公式表示的话,那么 g = tf.gradients(y,x)可以表示成
6. 梯度修剪
tf.clip_by_global_norm 修正梯度值,用于控制梯度爆炸的问题。梯度爆炸和梯度弥散的原因一样,都是因为链式法则求导的关系,导致梯度的指数级衰减。为了避免梯度爆炸,需要对梯度进行修剪。 先来看这个函数的定义:
1
def clip_by_global_norm(t_list, clip_norm, use_norm=None, name=None):
输入参数中:t_list 为待修剪的张量, clip_norm 表示修剪比例 (clipping ratio).
函数返回2个参数: list_clipped,修剪后的张量,以及global_norm,一个中间计算量。当然如果你之前已经计算出了 global_norm 值,你可以在 use_norm 选项直接指定 global_norm 的值。
那么具体如何计算呢?根据源码中的说明,可以得到
list_clipped[i] = t_list[i] * clip_norm / max(global_norm, clip_norm),其中
global_norm = sqrt(sum([l2norm(t)**2 for t in t_list]))
如果你更熟悉数学公式,则可以写作
\(L_c^i = \frac{L_t^i N_c}{\max(N_c, N_g)},\quad N_g = \sqrt{\sum_i(L_t^i)^2}\)
其中, \(L_t^i\) 和 \(L_c^i\) 代表 t_list[i] 和 list_clipped[i], \(N_c\) 和 \(N_g\) 代表 clip_norm 和 global_norm 的值。
7. 优化参数
之前的代码已经求得了合适的梯度,现在需要使用这些梯度来更新参数的值了。
1
2
3
4
5
6
7
# 梯度下降优化,指定学习速率
optimizer = tf.train.GradientDescentOptimizer(self._lr)
# optimizer = tf.train.AdamOptimizer()
# optimizer = tf.train.GradientDescentOptimizer(0.5)
self._train_op = optimizer.apply_gradients(
zip(grads, tvars),
global_step=tf.contrib.framework.get_or_create_global_step()) # 将梯度应用于变量
这一部分就比较自由了,tf 提供了很多种优化器,例如最常用的梯度下降优化(GradientDescentOptimizer)也可以使用 AdamOptimizer。这里使用的是梯度优化。值得注意的是,这里使用了optimizer.apply_gradients来将求得的梯度用于参数修正,而不是之前简单的optimizer.minimize(cost)
还有一点,要留心一下 self._train_op,只有该操作被模型执行,才能对参数进行优化。如果没有执行该操作,则参数就不会被优化。
8. Main 函数
1
2
3
4
5
6
7
8
initializer = tf.random_uniform_initializer(-config.init_scale, config.init_scale)
with tf.name_scope("Train"):
train_input = PTBInput(config=config, data=train_data, name="TrainInput")
with tf.variable_scope("Model", reuse=None, initializer=initializer):
m = PTBModel(is_training=True, config=config, input_=train_input)
tf.summary.scalar("Training Loss", m.cost)
tf.summary.scalar("Learning Rate", m.lr)
以均匀分布 [-init_scale, init_scale] 作为所有变量的初始化器, train_input 是一个类, 包含了所有的训练数据.
References
-
Understanding LSTM Networks – Colah’s blogs
[link] OnLine. ↩ ↩2 -
Long short-term memory
Hochreiter S, Schmidhuber J.
[link] In Neural computation, 1997, 9(8): 1735-1780. ↩ -
Recurrent nets that time and count
Gers F A, Schmidhuber J.
[link] In Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks. 2000. ↩ -
Learning phrase representations using RNN encoder-decoder for statistical machine translation
Cho K, Van Merriënboer B, Gulcehre C, et al.
[link] In arXiv preprint arXiv:1406.1078, 2014. ↩ ↩2 -
Order Matters: Sequence to Sequence for Sets
Vinyals, Oriol, Samy Bengio, and Manjunath Kudlur.
[link] In ArXiv:1511.06391, November. 2015. ↩ -
详解从 Seq2Seq模型、RNN结构、Encoder-Decoder模型 到 Attention模型
[link] OnLine. ↩ -
Learning phrase representations using RNN encoder-decoder for statistical machine translation
Cho K, Van Merriënboer B, Gulcehre C, et al.
[link] In arXiv preprint arXiv:1406.1078, 2014. ↩ -
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V.Le.
[link] In Advances in neural information processing systems. 2014: 3104-3112. ↩ -
Neural machine translation by jointly learning to align and translate
Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio
[link] arXiv preprint arXiv:1409.0473, 2014. ↩ -
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
[link] Advances in neural information processing systems. 2017: 5998-6008. ↩