Self-Attention 和 Transformer 自从问世就成为了自然语言处理领域的新星. 得益于全局的注意力机制和并行化的训练, 基于 Transformer 的自然语言模型能够方便的编码长距离依赖关系, 同时在大规模自然语言数据集上并行训练成为可能. 但由于自然语言任务种类繁多, 且任务之间的差别不太大, 所以为每个任务单独微调一份大模型很不划算. 在 CV 中, 不同的图像识别任务往往也需要微调整个大模型, 也显得不够经济. Prompt Learning 的提出给这个问题提供了一个很好的方向.
本文关于 NLP 的部分主要参考综述1.
1. NLP 模型的发展
过去许多机器学习方法是基于全监督学习 (fully supervised learning) 的.
由于监督学习需要大量的数据学习性能优异的模型, 而在 NLP 中大规模训练数据(指为特定任务而标注好的数据)是不足的, 因此在深度学习出现之前研究者通常聚焦于特征工程 (feature engineering), 即利用领域知识从数据中提取好的特征;
在深度学习出现之后, 由于特征可以从数据中习得, 因此研究者转向了结构工程 (architecture engineering), 即通过通过设计一个合适的网络结构来把归纳偏置 (inductive bias) 引入模型中, 从而有利于学习好的特征.
在 2017-2019 年, NLP 模型开始转向一个新的模式 (BERT), 即预训练 + 微调 (pre-train and fine-tune). 在这个模式中, 先用一个固定的结构预训练一个语言模型 (language model, LM), 预训练的方式就是让模型补全上下文 (比如完形填空).
由于预训练不需要专家知识, 因此可以在网络上搜集的大规模文本上直接进行训练. 然后这个 LM 通过引入额外的参数或微调来适应到下游任务上. 此时研究者转向了 目标工程 (objective engineering), 即为预训练任务和微调任务设计更好的目标函数.
2. Prompt Learning
2.1 什么是 Prompt ?
在做 objective engineering 的过程中, 研究者发现让下游任务的目标与预训练的目标对齐是有好的. 因此下游任务通过引入文本提示符 (textual prompt), 把原来的任务目标重构为与预训练模型一致的填空题.
比如一个输入 “I missed the bus today.” 的重构:
- 情感预测任务. 输入: “I missed the bus today. I felt so ___.” 其中 “I felt so” 就是提示词 (prompt), 然后使用 LM 用一个表示情感的词填空.
- 翻译任务. 输入: “English: I missed the bus today. French: ___.” 其中 “English:” 和 “French:” 就是提示词, 然后使用 LM 应该再空位填入相应的法语句子.
我们发现用不同的 prompt 加到相同的输入上, 就能实现不同的任务, 从而使得下游任务可以很好的对齐到预训练任务上, 实现更好的预测效果.
后来研究者发现, 在同一个任务上使用不同的 prompt, 预测效果也会有显著差异, 因此现在有许多研究开始聚焦于 prompt engineering.
2.2 有哪些预训练模型?
- Left-to-Right LM: GPT, GPT-2, GPT-3
- Masked LM: BERT, RoBERTa
- Prefix LM: UniLM1, UniLM2
- Encoder-Decoder: T5, MASS, BART
2.3 有哪些 Prompt Learning 的方法?
- 按照 prompt 的形状划分: 完形填空式, 前缀式.
- 按照人的参与与否: 人工设计的, 自动的(离散的, 连续的)
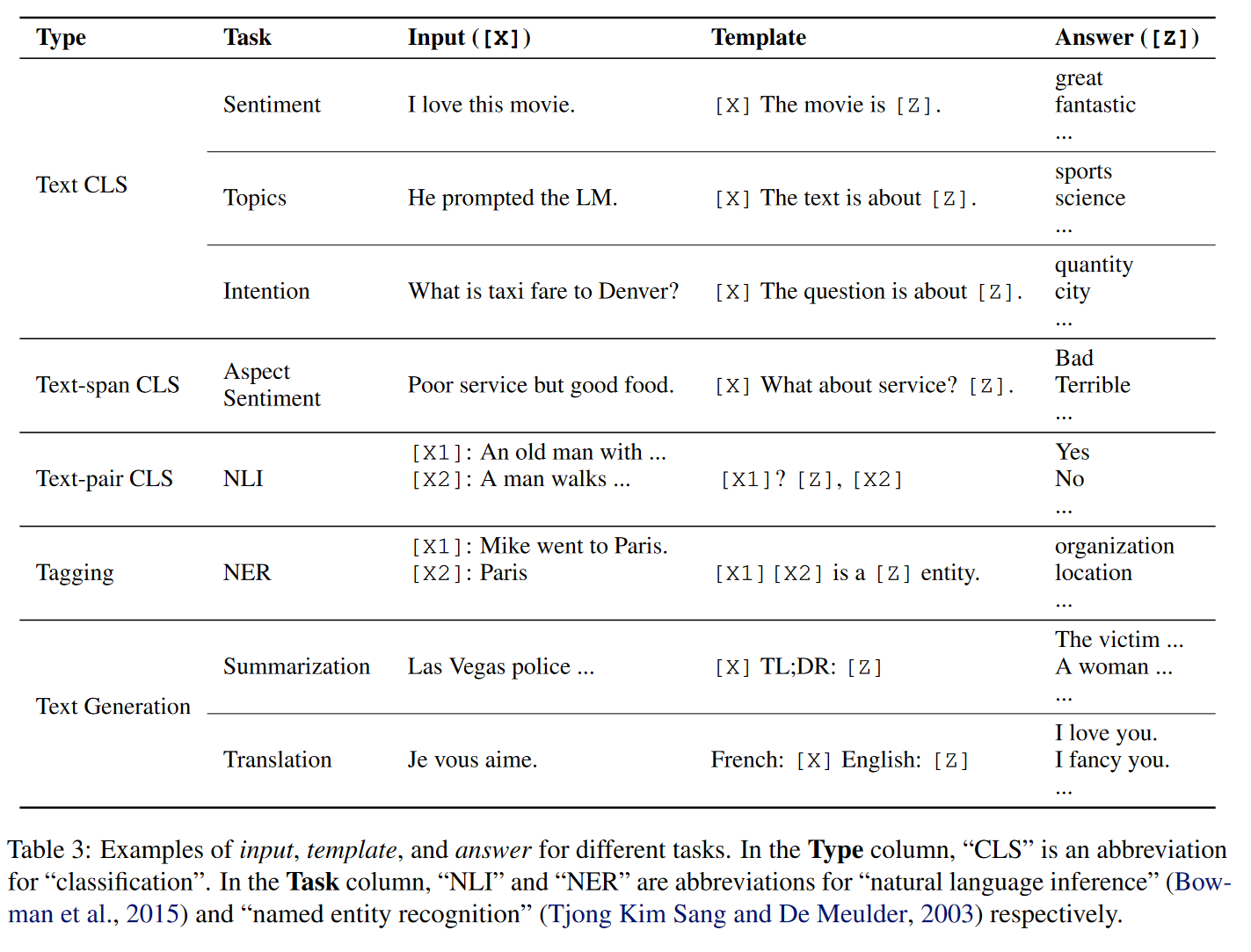
图 1. 人工设计的 Prompt
3. Prompt Tuning
3.1 Fine-tune 的策略
在下游任务上微调大规模预训练模型已经成为大量 NLP 和 CV 任务常用的训练模式. 然而, 随着模型尺寸和任务数量越来越多, 微调整个模型的方法会储存每个微调任务的模型副本, 消耗大量的储存空间. 尤其是在边缘设备上存储空间和网络速度有限的情况下, 共享参数就变得尤为重要.
一个比较直接的共享参数的方法是只微调部分参数, 或者向预训练模型中加入少量额外的参数. 比如, 对于分类任务:
- Linear: 只微调分类器 (一个线性层), 冻结整个骨干网络.
- Partial-k: 只微调骨干网络最后的 k 层, 冻结其他层2 3.
- MLP-k: 增加一个 k 层的 MLP 作为分类器.
- Side-tuning4: 训练一个 “side” 网络, 然后融合预训练特征和 “site” 网络的特征后输入分类器.
- Bias: 只微调预训练网络的 bias 参数5 6.
- Adapter7: 通过残差结构, 把额外的 MLP 模块插入 Transformer.
近年来, Transformer 模型在 NLP 和 CV 上大放异彩. 基于 Transformer 的模型在大量 CV 任务上已经比肩甚至超过基于卷积的模型.
3.2 NLP 中 基于 Prompt 的 fine-tune
- Prefix-Tuning
- Prompt-Tuning
- P-Tuning
- P-Tuning-v2
3.3 CV 中 基于 Prompt 的 fine-tuning
3.3.1 分类
Visual Prompt Tuning8
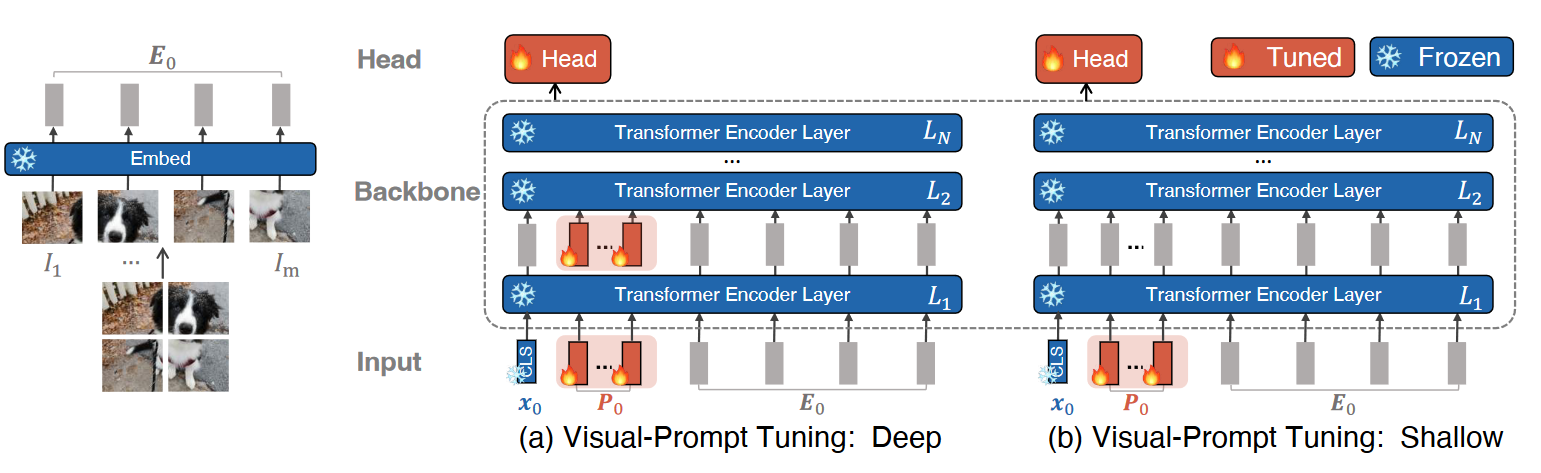
图 2. Visual Prompt Tuning
- VPT-Shallow
- VPT-Deep
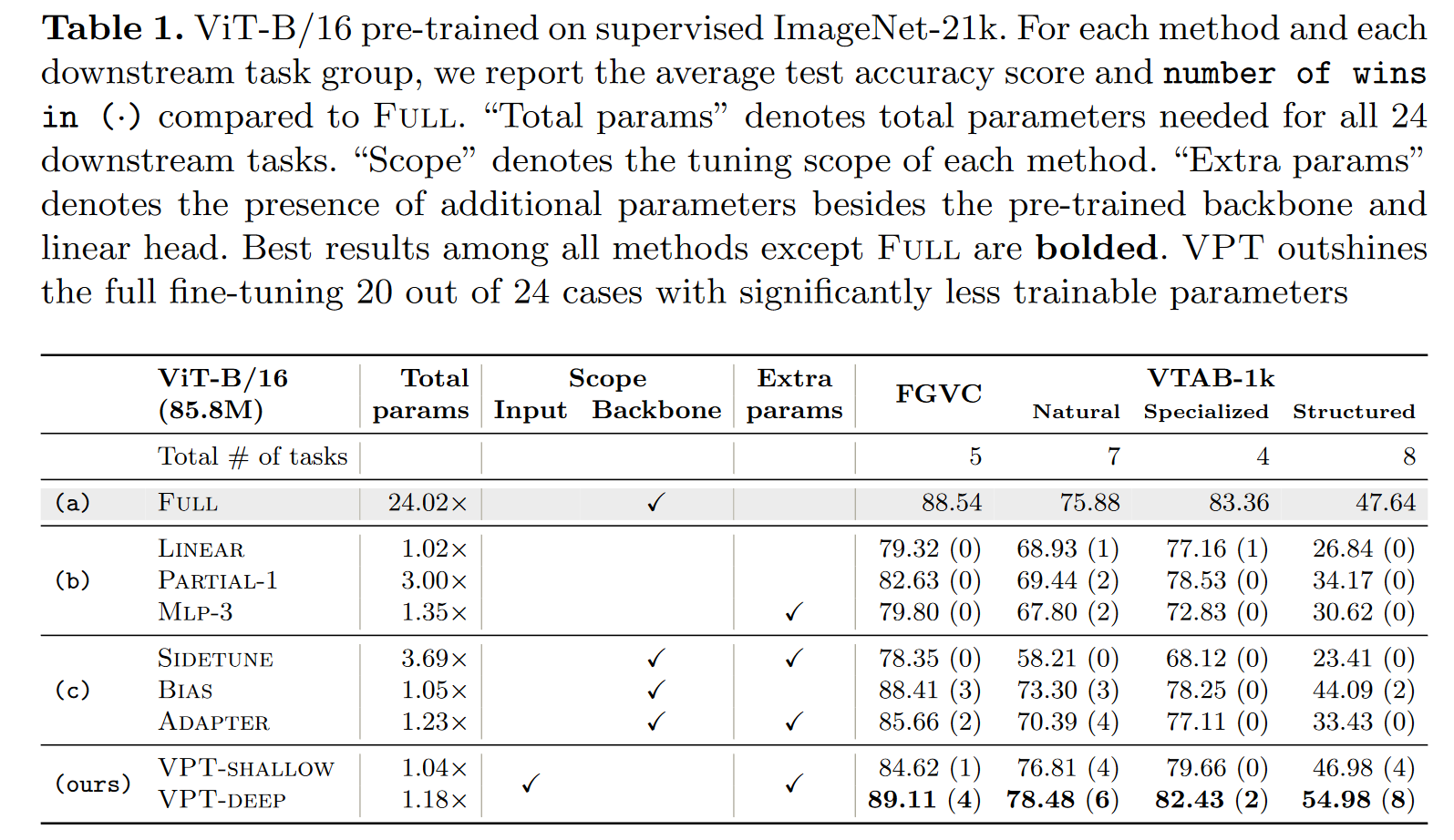
图 3. VPT Results
3.3.2 持续学习
Learning to Prompt for Continue Learning9
引入一个 prompt pool, 对每个 input, 从 pool 中取出与其最近的 N 个 prompts 加入 image tokens. input 和 prompts 距离的度量通过计算 input feature 和每个 prompt 的 key 的距离来得到, 这些 key 通过梯度随分类目标一起优化.
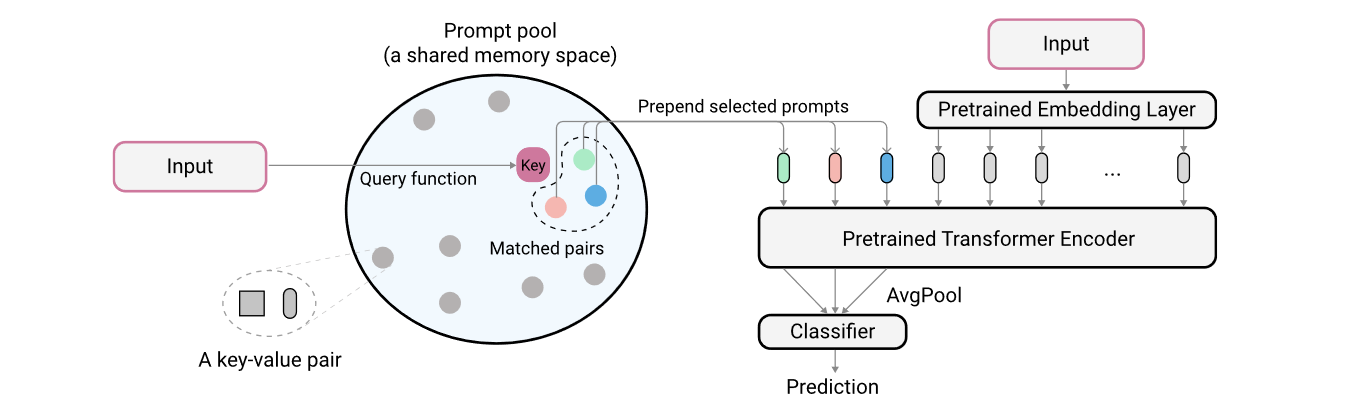
图 4. L2P
注意, 最后使用 prompt 来分类.
3.3.3 多模态模型
Vision-Language Model: Context Optimization (CoOp)10
多模态学习的预训练模型. 比如 CLIP, 通过对比学习对齐文本和图像的特征空间.
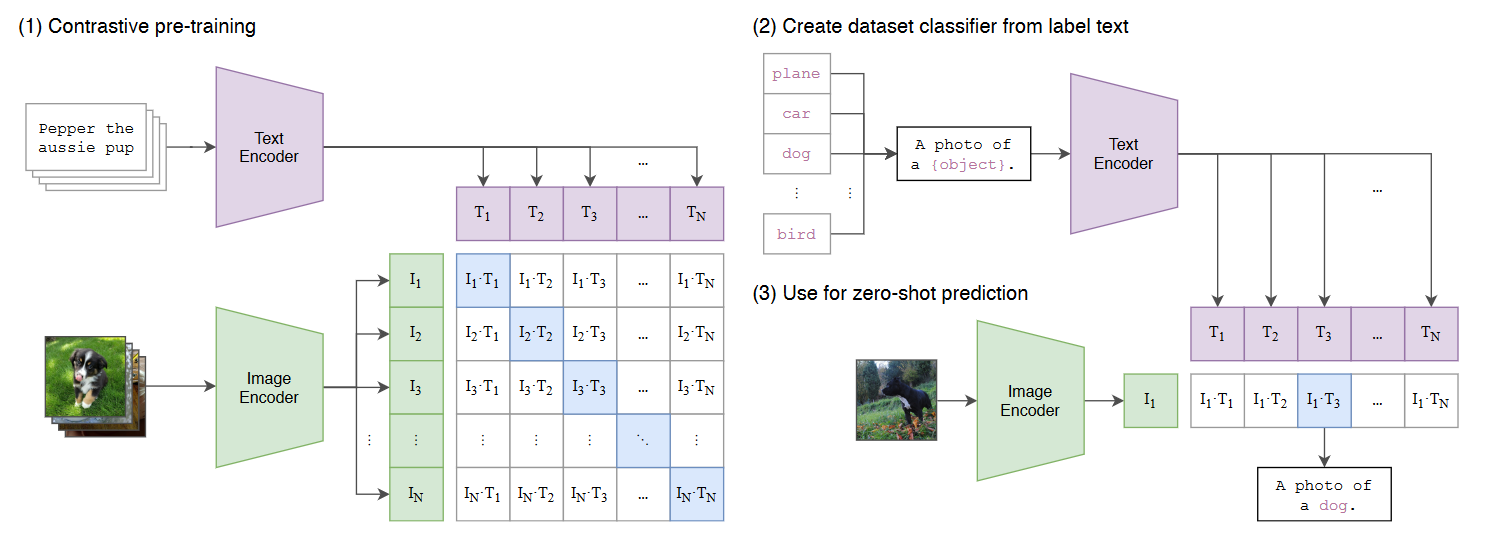
图 5. CLIP
选择不同的文本 prompt 对于精度影响较大.

图 6. Prompt engineering vs Context Optimization (CoOp)
把人工设定的 prompt 替换为 learnable 的 prompt:
- [CLASS] 放在后面: \(t = [\text{V}]_1[\text{V}]_2\dots[\text{V}]_M[\text{CLASS}]\)
- [CLASS] 放在中间: \(t = [\text{V}]_1\dots[\text{V}]_{\frac{M}{2}}[\text{CLASS}][\text{V}]_{\frac{M}{2}+1}\dots[\text{V}]_M\)
Prompt 可以在不同类之间公用, 也可以为每个类使用不同的 prompts (对于细粒度分类任务更有效).
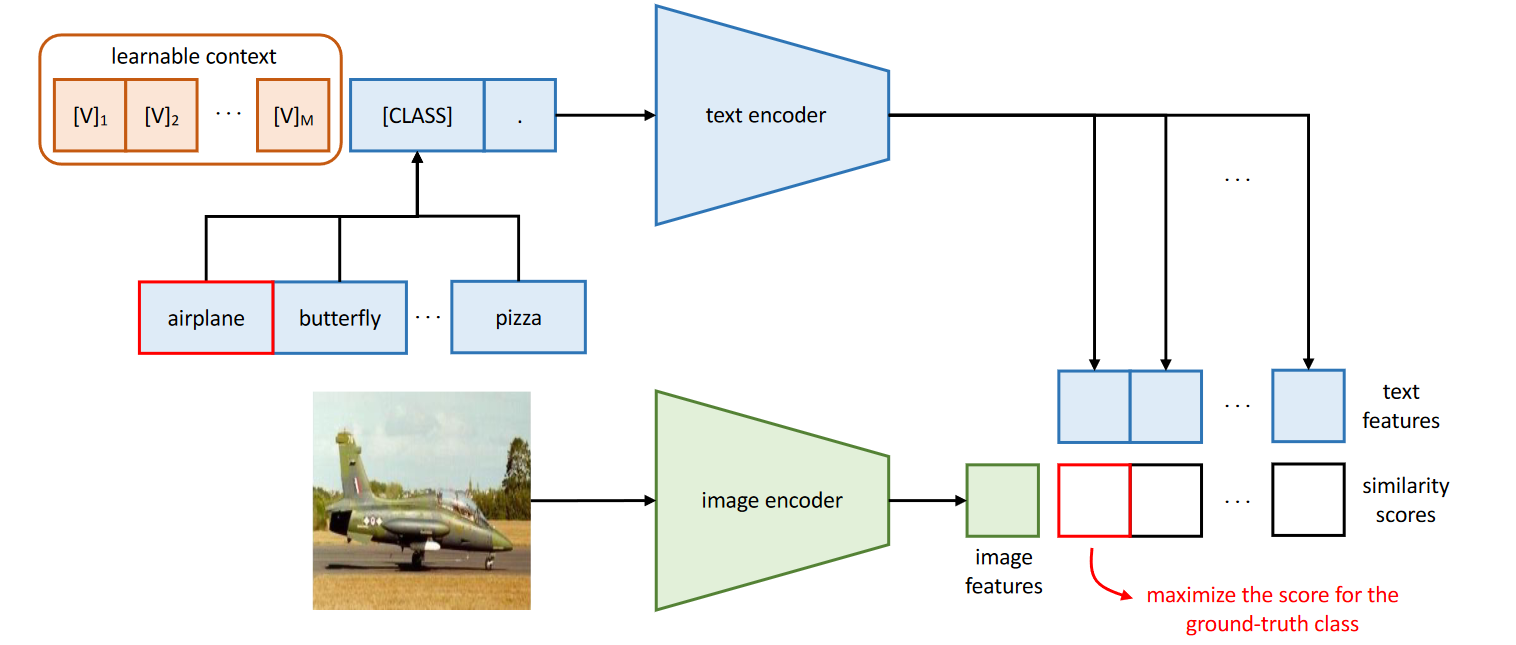
图 7. Learning to Prompt for Vision-Language Model
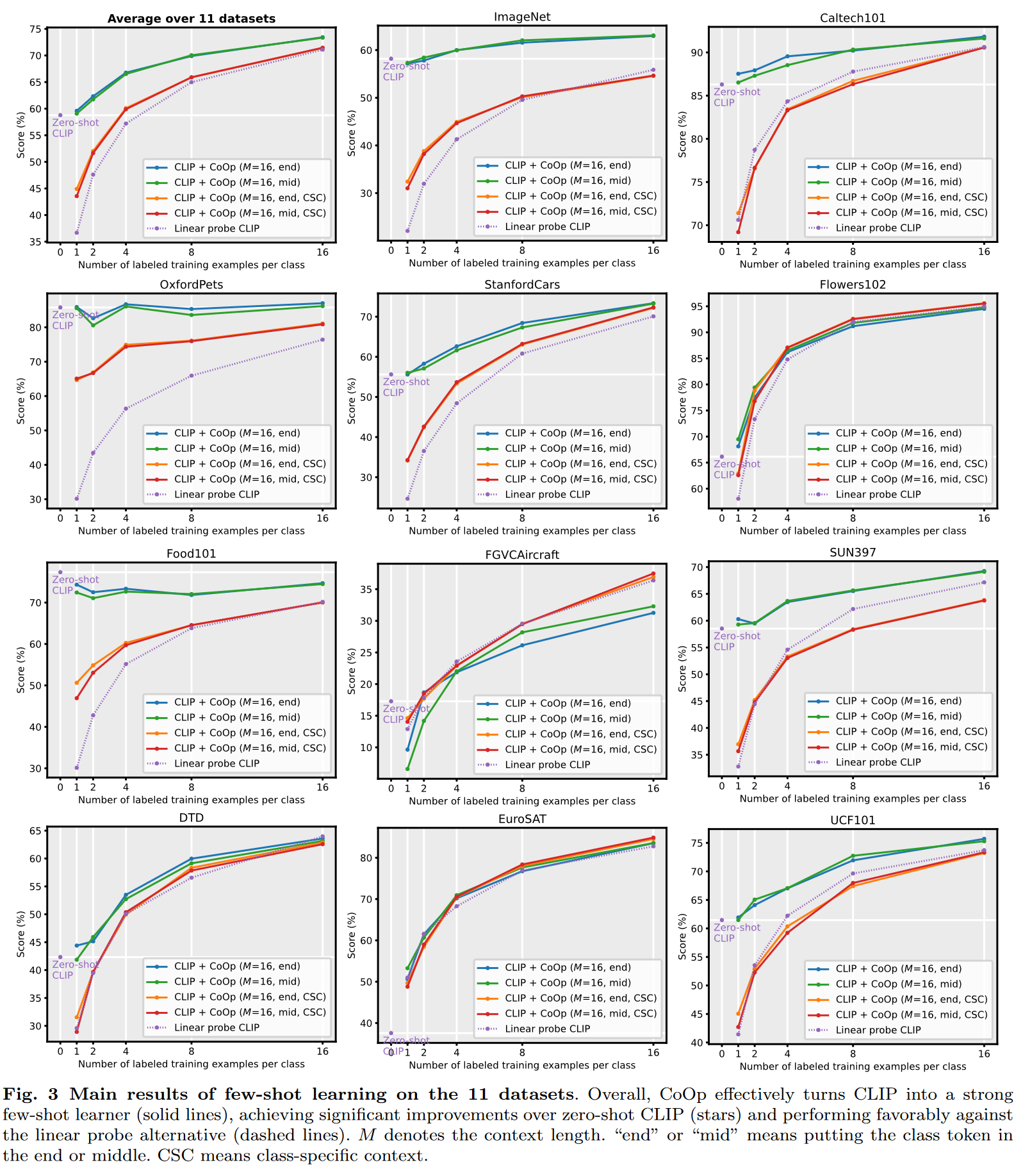
图 8. Learning to Prompt for Vision-Language Model
Conditional Prompt Learning for Vision-Language Models11
CoOp 在泛化到新的类别上时性能不好.

图 9. To learn generalizable prompts
所以把 prompt 设计为 instance-conditional 的.
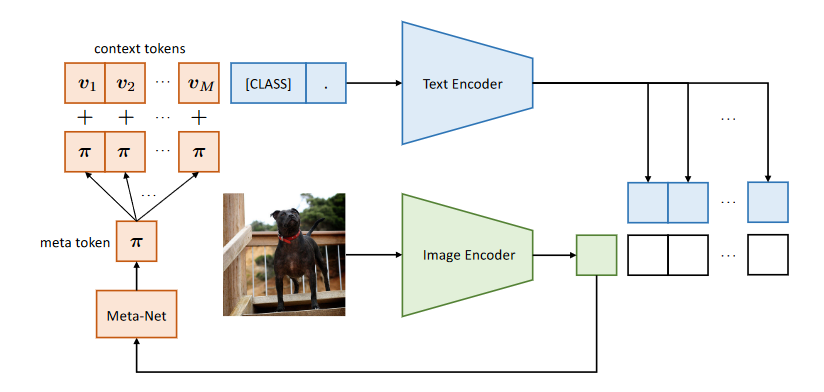
图 10. To learn generalizable prompts
为 prompt 加上一个跟当前图像相关的特征以提高泛化性能. 具体来说, 先用 Image Encoder 计算当前图像的 feature, 然后通过一个 Meta-Net 把 feature 映射到 prompt 的特征空间, 加到 prompt 上面.
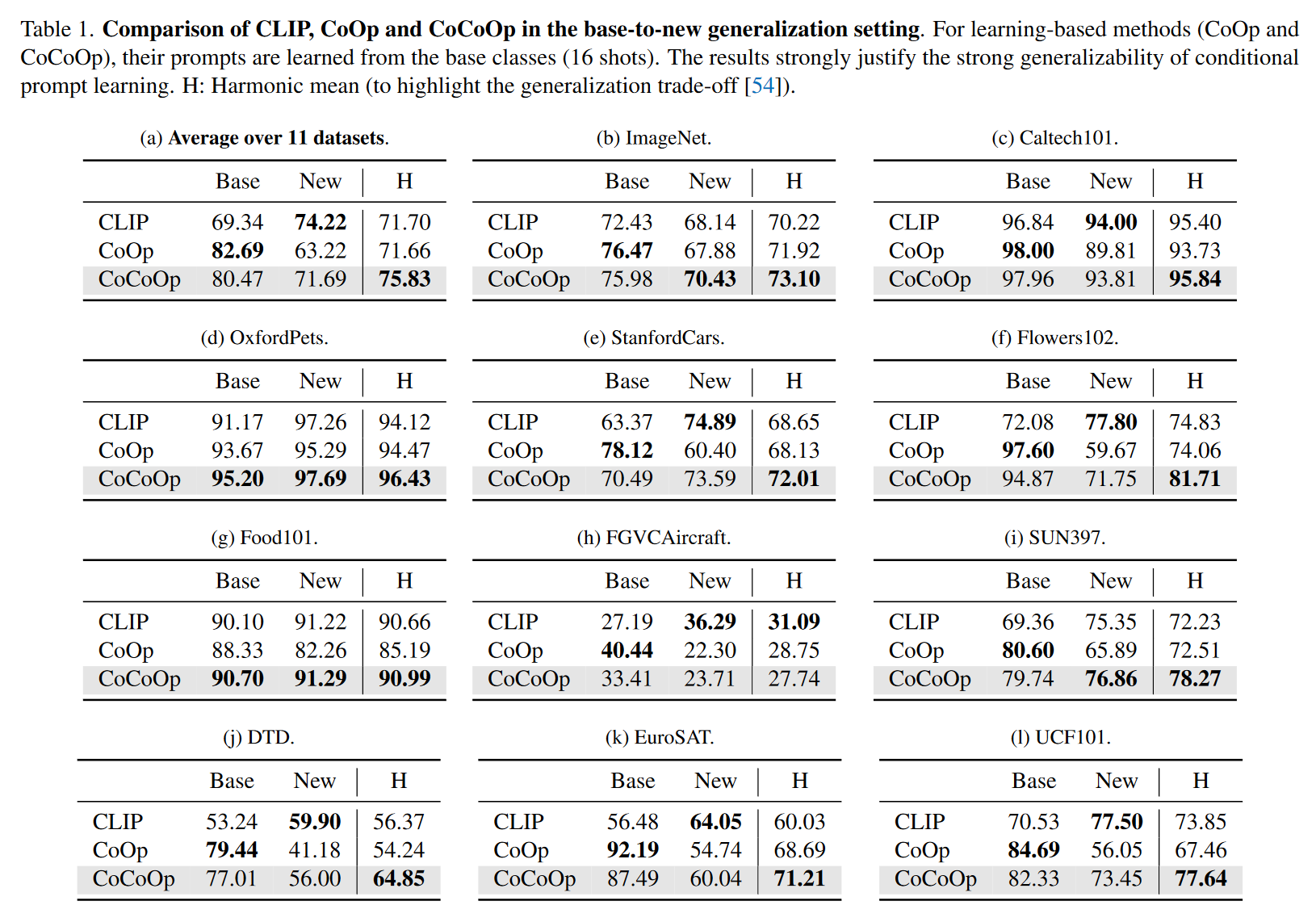
图 11. To learn generalizable prompts
3.3.4 域适应
Domain Adaptation via Prompt Learning12
用 prompt 来标识 domain 的信息.

图 12. Example prompt structure
通过对比学习解耦 representation 中的 class 和 domain 的表示.
\[P(\hat{y}_i^s=k|\mathbf{x}_i^s) = \frac{\exp(\langle g(\mathbf{t}_k^s), f(\mathbf{x}_i^s)\rangle/T)}{\sum_{d\in\{s,u\}}\sum_{j=1}^K\exp(\langle g(\mathbf{t}_j^s), f(\mathbf{x}_i^s)\rangle/T)}\]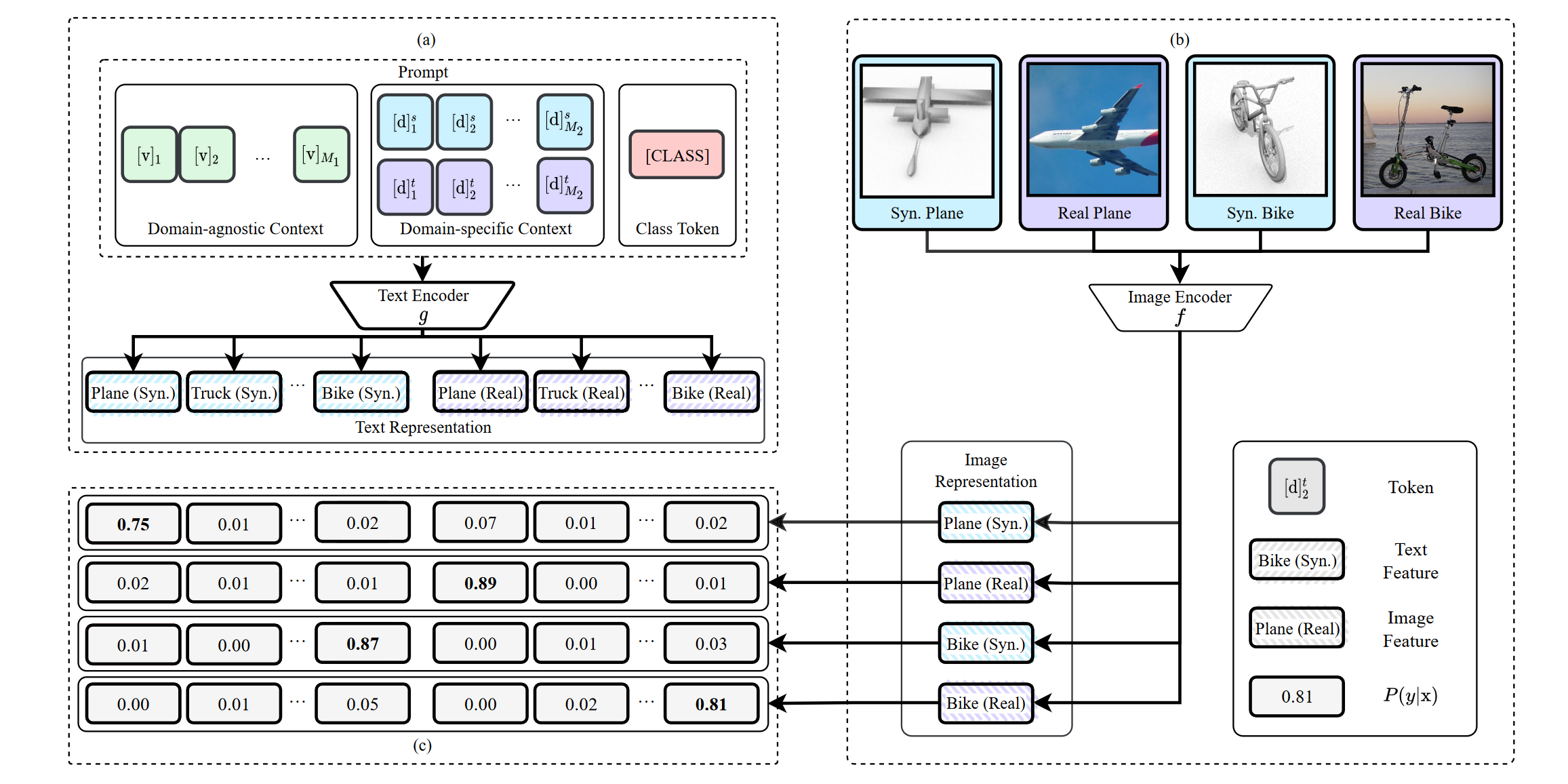
图 13. Domain Adaptation with Prompt Learning
Reference
-
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, Graham Neubig
[html] In arXiv 2021 ↩ -
How transferable are features in deep neural networks?
Jason Yosinski, Jeff Clune, Yoshua Bengio, Hod Lipson
[html] In NeruIPS 2014 ↩ -
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick
[html] In arXiv 2021 ↩ -
Side-tuning: a baseline for network adaptation via additive side networks
Jeffrey O. Zhang, Alexander Sax, Amir Zamir, Leonidas Guibas, Jitendra Malik
[html] In ECCV 2020 ↩ -
Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models.
Elad Ben Zaken, Shauli Ravfogel, Yoav Goldberg
[html] In ACL 2022 ↩ -
TinyTL: Reduce memory, not parameters for efficient on-device learning
Han Cai, Chuang Gan, Ligeng Zhu, Song Han
[html] In NeurIPS 2020 ↩ -
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, Sylvain Gelly
[html] In ICML 2019 ↩ -
Visual Prompt Tuning
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, Ser-Nam Lim
[html] In arXiv 2022 ↩ -
Learning to Prompt for Continual Learning
Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, Tomas Pfister
[html] In CVPR 2022 ↩ -
Learning to Prompt for Vision-Language Models
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, Ziwei Liu
[html] In arXiv 2021 ↩ -
Conditional Prompt Learning for Vision-Language Models
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, Ziwei Liu
[html] In CVPR 2022 ↩ -
Domain Adaptation via Prompt Learning
Chunjiang Ge, Rui Huang, Mixue Xie, Zihang Lai, Shiji Song, Shuang Li, Gao Huang
[html] In arXiv 2022 ↩