- A Random CNN Sees Objects: One Inductive Bias of CNN and Its Applications
- ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias
- 参考文献
深度神经网络为什么适合图像特征的提取和分析? 为什么近年来火热的对比学习能把无监督下的特征表示很好的学出来? 深度神经网络到底有什么魔法? 要思考上面的问题, 首先要了解一个概念: 归纳性偏好(inductive bias).
A Random CNN Sees Objects: One Inductive Bias of CNN and Its Applications1
- Yun-Hao Cao, Jianxin Wu
- 南京大学
1. Introduction
一个学习算法的归纳性偏好(inductive bias)指的是假设空间中施加的约束, 在该学习算法下可以习得满足约束的模型实例.
我们很容易想象出一个简单线性模型(linear classifier)的归纳性偏好就是特征和标签之间线性相关. 与之相对地, 深度神经网络的归纳性偏好就不那么显然了.
在自然图像的识别中, 前景物体(object)是一类重要的识别对象, 现有的目标识别算法可以不使用检测框通过弱监督或无监督方法识别物体, 然而这些算法严重依赖于 ImageNet 上的预训练模型和复杂的微调策略.
这篇文章发现了一个惊人的事实: 一个随机初始化的 CNN 有着惊人的物体定位能力. 如图 1 所示. 文中把这个现象叫做 The object is at sight, 简写为 Tobias. 一种直觉上的原因是, 相比于前景物体, 背景通常有着更弱的纹理信息, 这些弱纹理的区域天然会被 ReLU 等激活函数所抑制.

图 1. Object location of a random initialized CNN
2. Tobias
给定一张图像 \(x\), 其高层特征记为 \(Q\in\mathbb{R}^{h\times w\times d}\), 其中 \(Q\) 包含的的二维特征图的集合记为 \(S=\{S_n\}, n=1,\cdots,d\). 比如使用 ResNet-50 作为特征提取器, 输入图像的尺寸为 \(224\times224\), 那么 \(Q\) 的大小就是 \(7\times7\times2048\). 接下来把集合 \(S\) 中的二维特征图加起来得到:
\[A = \sum_{n=1}^d S_n,\]从而我们可以获得一个掩膜矩阵:
\[M_{i,j}=\begin{cases} 1 & \text{if } A_{i,j} > \bar{a}, \\ 0 & \text{otherwise.} \end{cases}\]其中 \(\bar{a}=\frac1{h\times w}\sum_{i,j}A_{i,j}\) 是 \(A\) 的平均值. 也就是我们构造了一个取值高于平均值的掩膜矩阵, 该矩阵作为最终的目标检测器, 我们认为它表示了前景物体.
SCDA2 使用该方法做图像检索, 但它是基于 ImageNet 预训练模型的. 而 Tobias 把该方法直接用到了随机初始化的模型中, 发现效果也相当好.
3. Tobias for SSL
本文把 Tobias 的这个现象应用于了无监督学习, 并提出了一种数据增广的方法.
首先使用一个随机初始化的模型提取所有图像的掩膜矩阵 \(M\), 然后把图像划分成多个 patches, 从而和掩膜矩阵的元素一一对应. 对于掩膜矩阵中的每一个元素, 值为 1 时对应的 patch 记为前景, 否则记为背景. 注意这里的掩膜矩阵是使用中位数作为预知的, 这样可以保证前景和背景的 patches 数量一样多 (尽管实际的图像里前景和背景像素的比例并不一致). 然后给定图像 \(x_1\) 和 \(x_2\), 我们可以通过组合一张图的前景 patches 和另一张图的背景 patches 来构造新的图像. 其中前景 patches 的位置保持不变, 剩余位置填充背景 patches.
考虑自监督方法 MoCo. 给定图像 \(x\), 通过数据增广可以获得两个不同的视图 \(x'\) 和 \(x''\). 其损失函数定义如下:
\[L^{self} = -\sum_{i}\log\frac{e^{z_i'\cdot z_i''/\tau}}{\sum_{j\neq i}e^{z_i'\cdot z_i''/\tau} + \sum_j e^{z_i'\cdot z_i''/\tau}},\]其中 \(z=f(x)\) 表示图像的特征. 为了应用 Tobias, 把 \(x''\) 以概率 \(p\) 替换为通过 Tobias 增广的数据即可.
4. Experiments
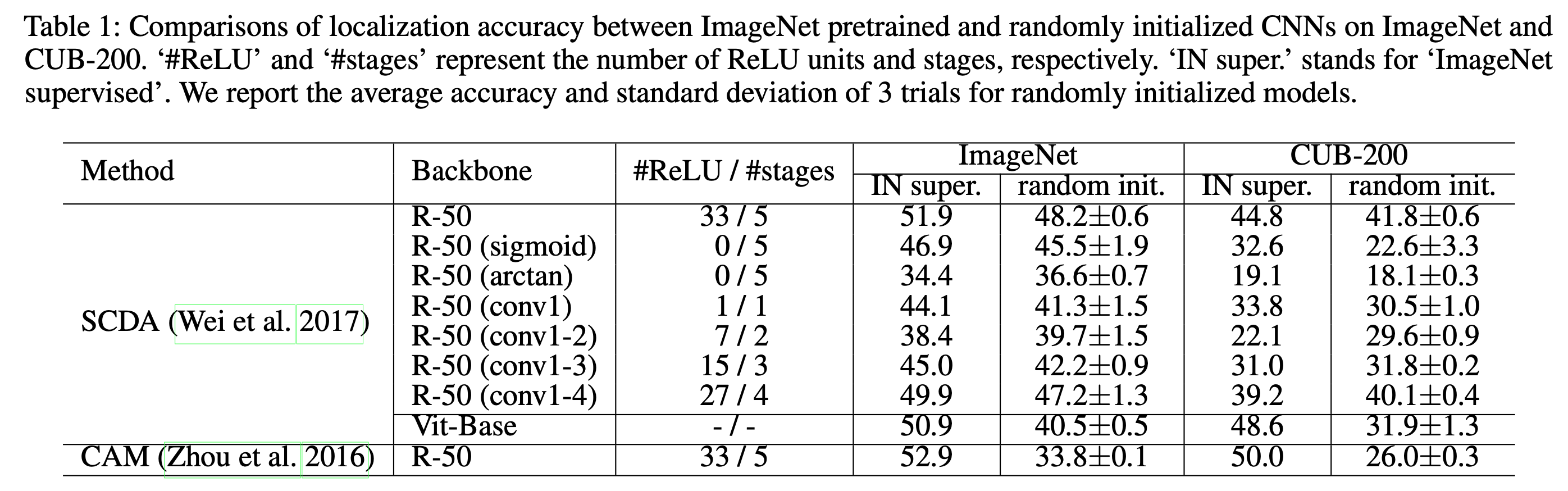
图 2. Results
从上面的实验我们有如下结论:
- 随机初始化的 ResNet-50 在物体定位上和 ImageNet 预训练模型是可比的.
- 随机初始化也可以定位一张图中的多个物体 (图 1)
- 定位结果对于随机初始化是稳健的 (方差小)
- Tobias 主要存在与 CNN, ViT 这类 MLP-base 的方法会大打折扣.
作者这样解释原因:
The background is relatively texture-less when compared to the objects, and texture-less regions have higher chances to be deactivated by ReLU when the net- work depth increases.

图 3. Results
从上面的实验我们有如下结论:
- ReLU 类型的激活都有效 (抑制负值, 激活正值)
- 模型越深效果越好
- 定位效果和模型的分类效果一致
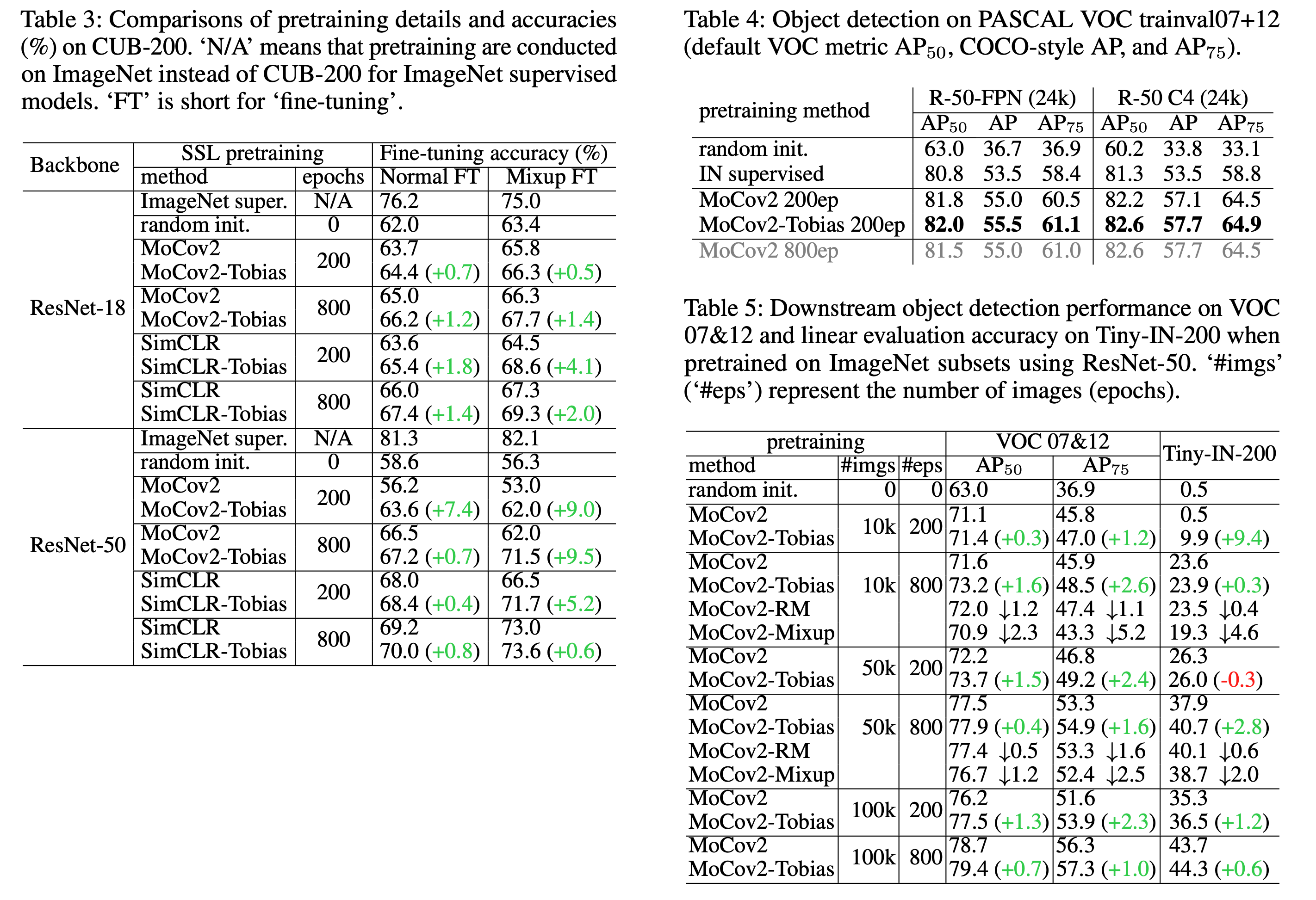
图 4. Results
Tobias 用于自监督学习的数据增广后, 在下游任务上的表现.
ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias3
- Yufei Xu, Qiming ZHANG, Jing Zhang, Dacheng Tao
- 悉尼大学, 京东探索研究员
1. Introduction and Methods
Vision Transformer 利用 self-attention 建模长程依赖, 在视觉任务上取得了非常显著地进展. 但把图像直接当做一维向量进行学习会损失掉 CNN 的天然的归纳性偏好: 特征的局部性和缩放不变性. 因此 ViT 往往需要大规模的训练数据来学习归纳性偏好才能获得不错的性能. 因此本文提出 Vision Transformer Advanced by Exploring intrinsic IB (ViTAE), 把 CNN 的归纳性偏好引入 ViT 以降低对大规模数据的依赖性并提高收敛速度.
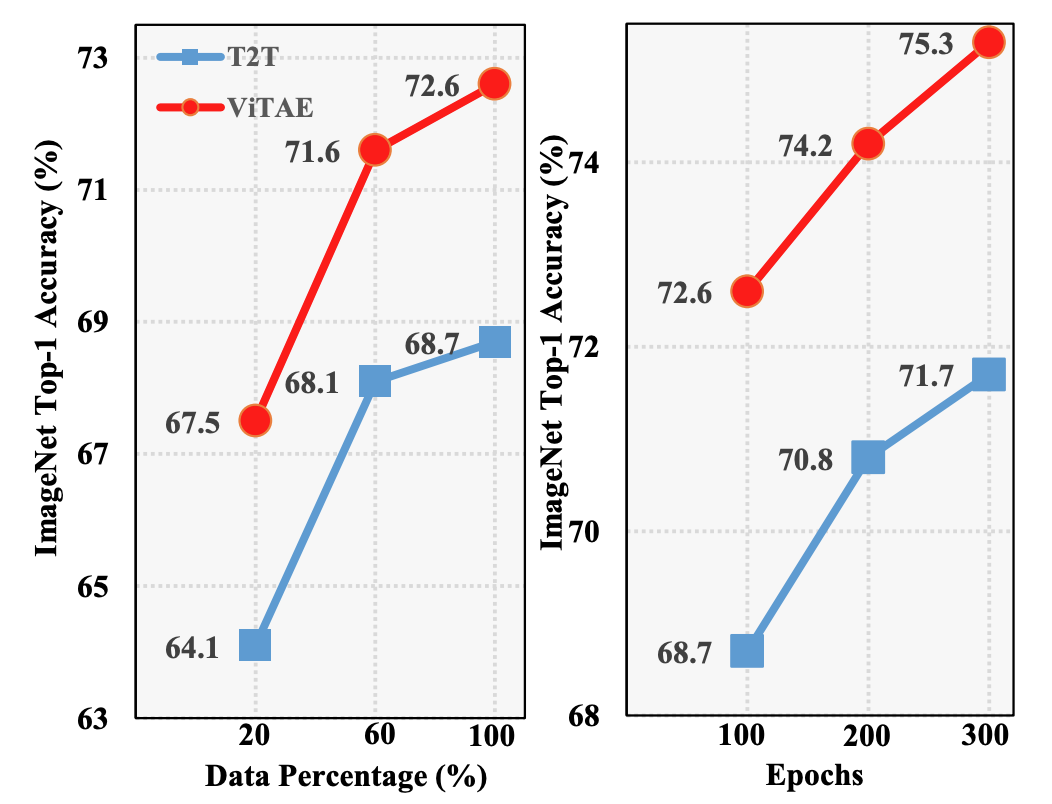
图 5. T2T-ViT-7 和 ViTAE 的数据使用量和训练效率比较
ViTAE 模型结构如下图所示.
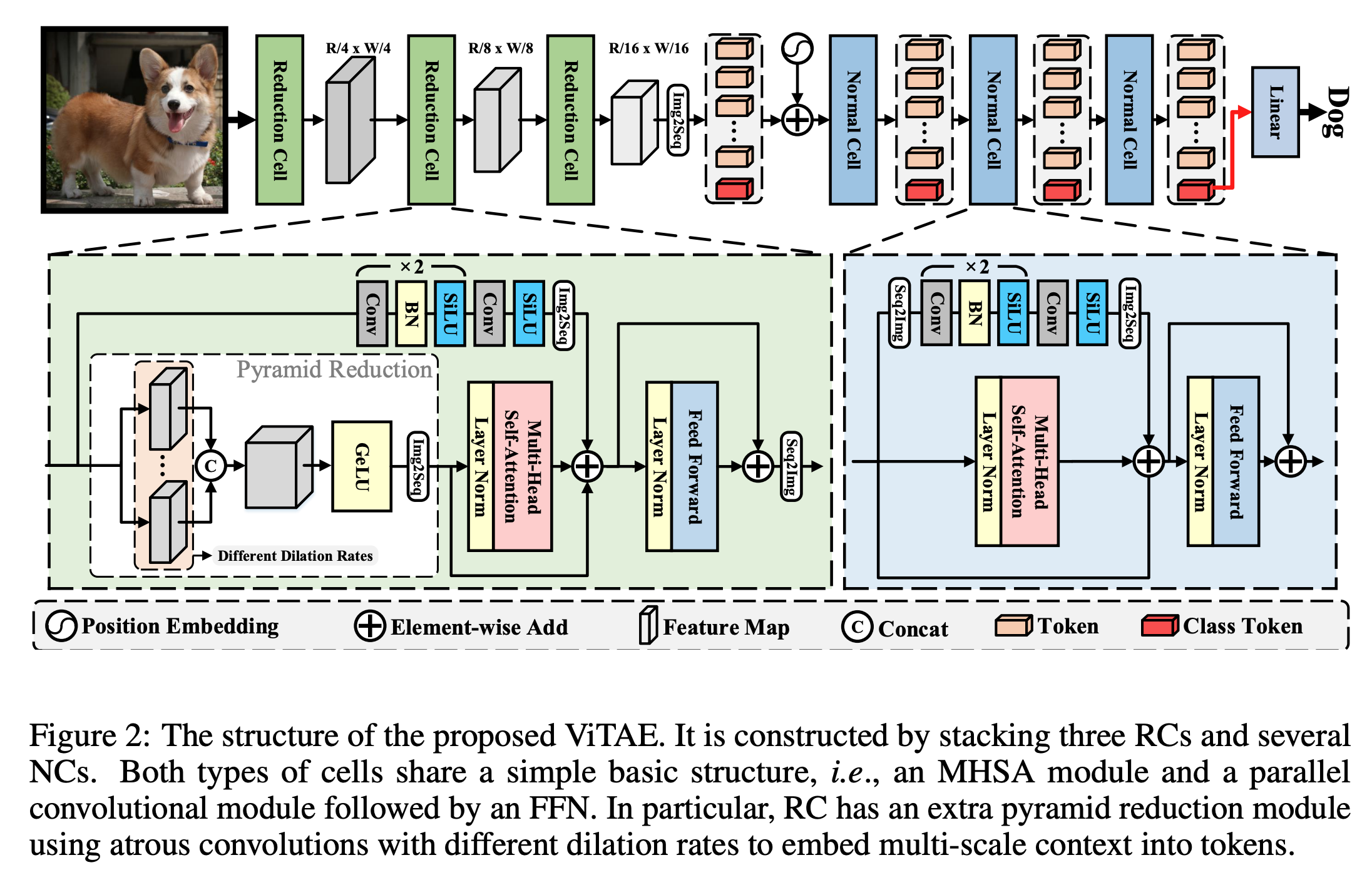
图 6. ViTAE 模型结构
模型包含两种模块: Reduction Cell 和 Normal Cell.
-
Reduction Cell: 用于把多尺度和局部信息编码到 tokens 中
-
Normal Cell: 用于把局部信息和长程依赖编码到 takens 中
2. Experiments
- ImageNet 结果
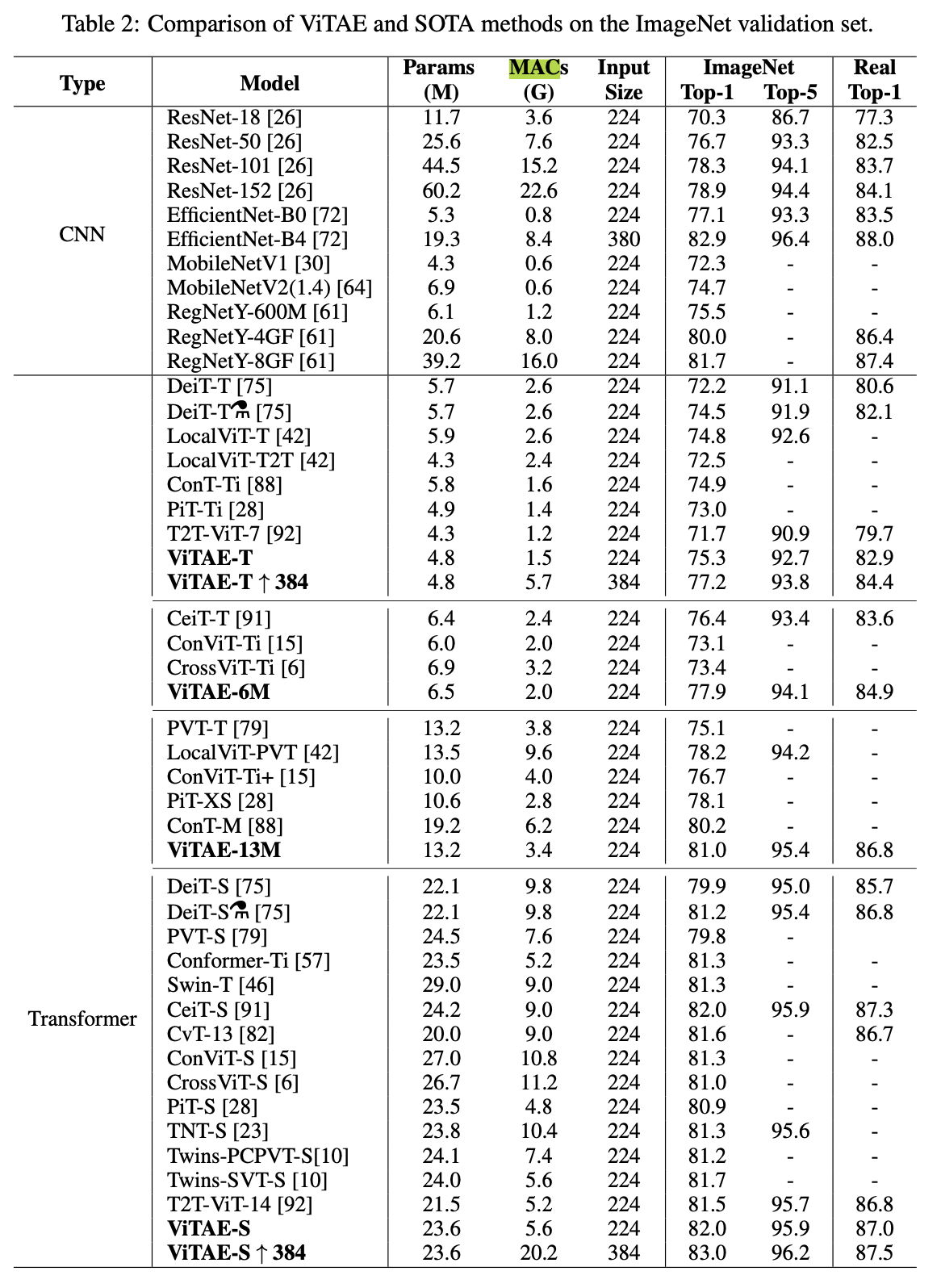
图 7. Results on ImageNet
- 下游任务结果. [link]
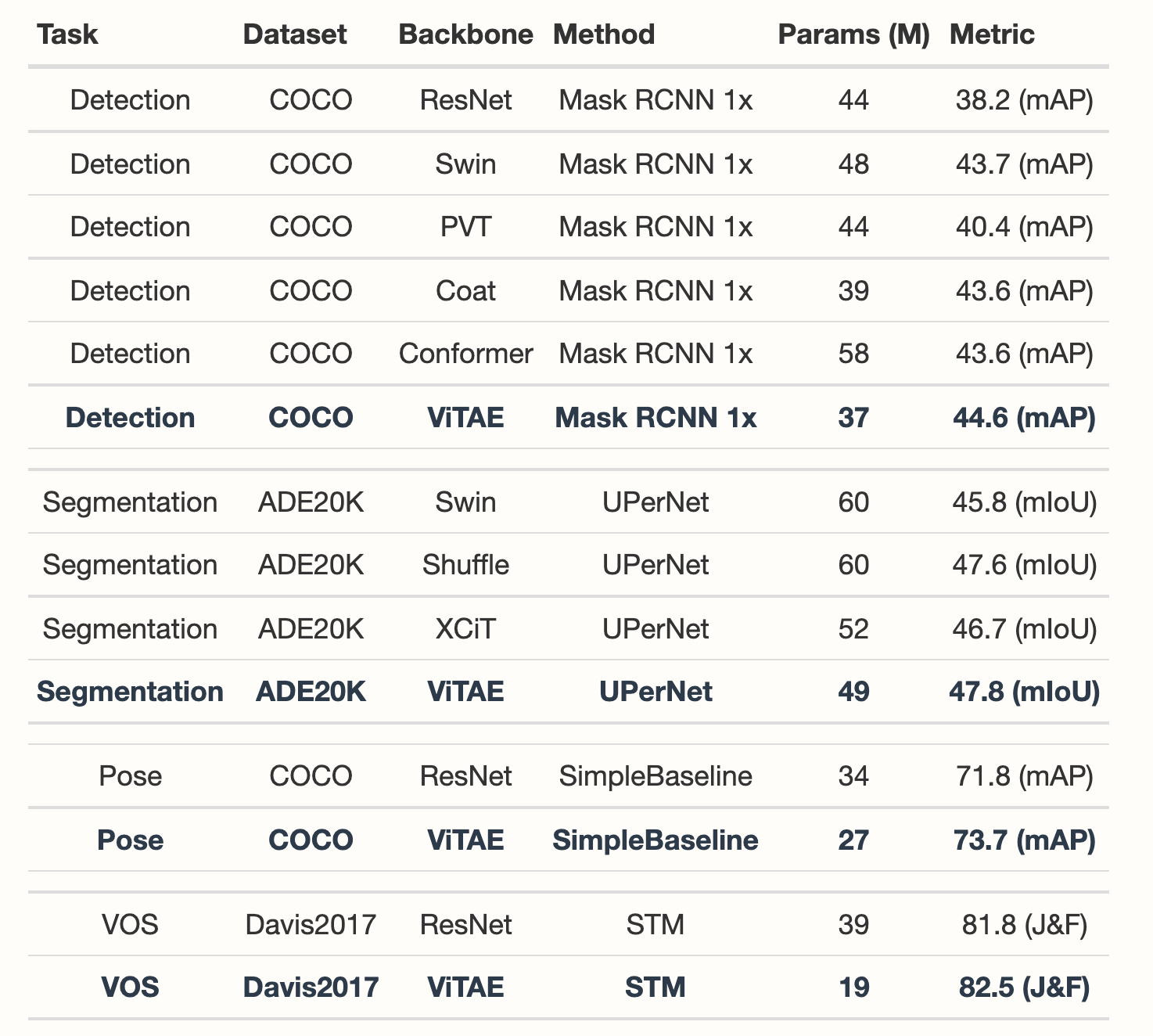
图 8. Results on downstream tasks.
参考文献
-
A Random CNN Sees Objects: One Inductive Bias of CNN and Its Applications
Yun-Hao Cao, Jianxin Wu
[ArXiv] In AAAI 2022 ↩ -
Selective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval
Wei, X.-S.; Luo, J.-H.; Wu, J.; and Zhou, Z.-H.
[html] [ArXiv] In IEEE TIP 2017 ↩ -
ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias
Yufei Xu, Qiming ZHANG, Jing Zhang, Dacheng Tao
[html] In NeruIPS 2021 ↩