- 摘要
- Self-Supervised Learning
- Contrastive Learning
- Deep InfoMax
- MoCo
- SimCLR
- SwAV
- BYOL
- SimCLR V2
- MoCo V3
- 参考文献
摘要
- MoCo
- SimCLR
- SwAV
- BYOL
- MoCo V3
排行榜: https://paperswithcode.com/sota/self-supervised-image-classification-on
Self-Supervised Learning
自监督学习 vs 无监督学习:
- 无监督学习指的是不使用标签来从数据集中学习特征的学习方法
- 自监督学习指的是从数据集中自定义新的 pretext task (包括 samples 和 labels) 来完成预训练
- (Method 1) 自监督学习是无监督学习的一种, 都是为了从数据 \(x\) 中生成 有代表性的特征 \(h = f(x)\), 用于下游任务. 那么什么是有代表性的特征?
在无监督学习中, 有一些的研究认为, 如果可以从 \(h\) 中很好的恢复 \(x = g(h)\) 的话, 那么 \(h\) 就是有代表性的特征. 由此, 出现了大量的生成式方法, 比如 AutoEncoder, 这类模型希望从低维特征 \(h\) 中生成的样本尽可能地与原始样本相同, 即:
\[\min\mathcal{L}_1(g(f(x)), x)\]但是生成式方法需要构造一个额外的生成器 \(g\), 这会存在一些问题, 比如需要两个模型, 生成的样本不尽如人意等. (待补充)
因此人们开始思考是否有其他路径来判断 \(h\) 是否为有代表性的特征, 于是人们做出了一些妥协的选择:
- (Method 2) 使用 \(h\) 可以完成特定的下游任务, 如预测空间位置, 预测部分样本, 执行拼图任务等等. 这类方法需要增加分类器或回归器 \(p\) 执行预测任务, 即
- (Method 3) 如果当样本进行一些变换时, \(h\) 能够保持不变, 那么就认为 \(h\) 就是有代表性的特征. 前面两种方法都是在输出空间进行比较, 而这第三种方法是在特征空间中进行比较:
其中 \(x^+\) 是 \(x\) 的一个变换.
Contrastive Learning
但是这第三种方法有个缺点—会产生平凡解, 即模型永远都把所有的样本映射到同一个点上. 这就意味着, 我们不仅要把相似的样本在特征空间中映射到尽量接近的位置, 还要让不相似的样本映射到尽量远的位置, 这就导出了对比学习 (Contrastive Learning):
\[\min\mathcal{L}_3(f(x), f(x^+)) - \mathcal{L}_4(f(x), f(x^-))\]如果我们把这样的无监督学习过程看做一种降维的话, 这样的学习方法还有几个好处, (1) 不需要在输入空间构造度量函数, (2) 只需要样本的邻接关系, (3) 学习到的映射可以直接应用于新的数据点而不需要额外的先验知识.
Deep InfoMax
微软: Learning deep representations by mutual information estimation and maximization1
应用对比学习, 通过最大化 \(h\) 和 \(x\) 的互信息, 并且最小化 \(h\) 和负样本 \(x'\) 的互信息来训练.
\[\min - T(x, h) + \log\sum_{x'}e^{T(x', h)}\]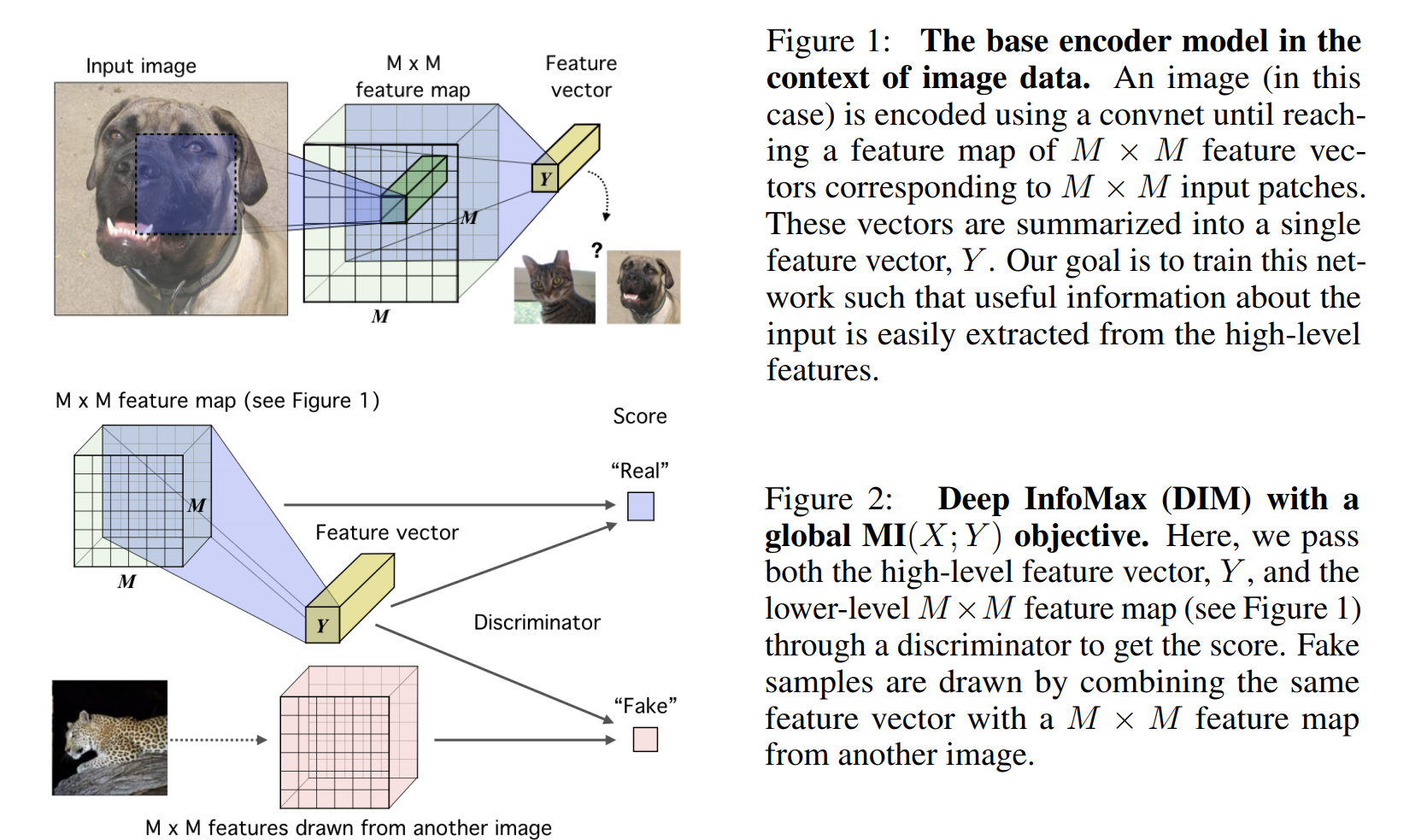
图 1. Deep InfoMax
MoCo
FAIR: Momentum Contrast for Unsupervised Visual Representation Learning2
作者假设从更多的负样本中可以学到更好的特征, 因此维护了个比 batch size 更大的查询字典, 并使用动量来保持字典中键的一致性.
\[\begin{align} \theta_q &\leftarrow \theta_q - \eta\nabla f_q(x) \\ \theta_k &\leftarrow m\theta_k + (1-m)\theta_q \end{align}\]其中 \(\theta_k, \theta_q\) 分别是字典分支和查询分支的编码器参数.
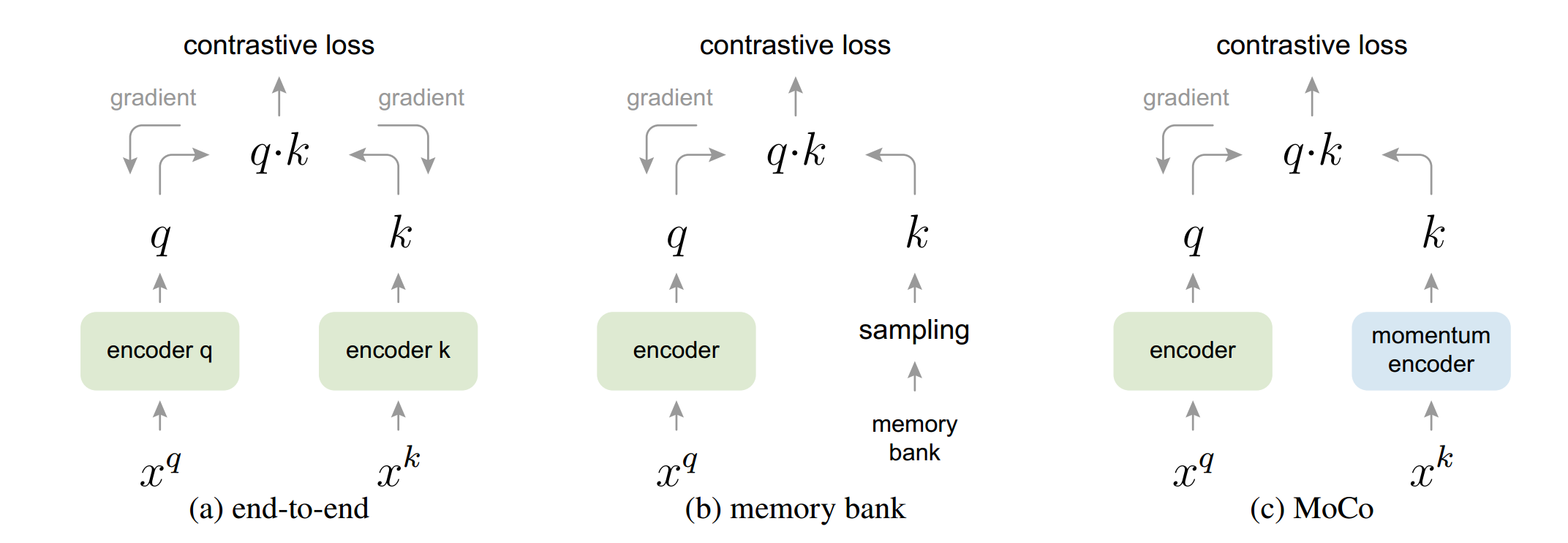
图 2. MoCo
SimCLR
Google Brain: A Simple Framework for Contrastive Learning of Visual Representations3
本文贡献: (1) 组合使用多种 data augmentation 很关键, (2) 表示层和对比学习损失层之间增加一个线性层很关键, (3) 大 batch size 和更多的 epochs 很关键.
\[\min-\log\frac{\exp(s_{i,j}/\tau)}{\sum_{k=1}^{2N}\mathbf{1}_{[k\neq i]}\exp(s_{i,j}/\tau)}\]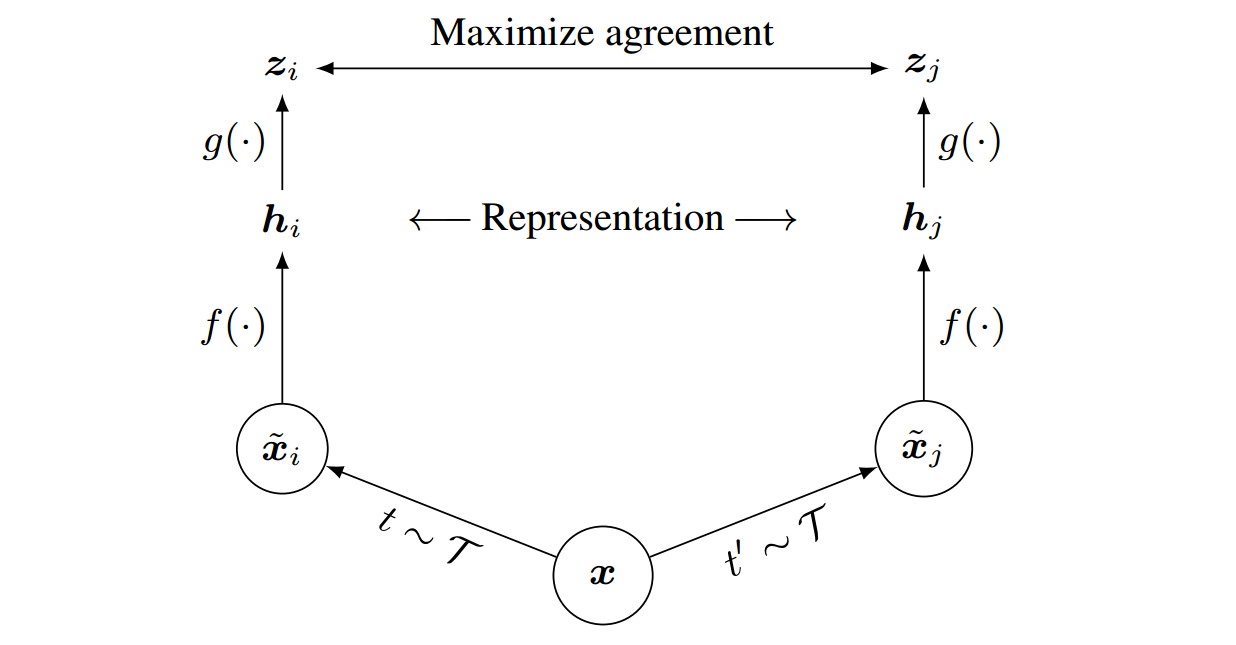
图 3. SimCLR
SwAV
FAIR: Unsupervised Learning of Visual Features by Contrasting Cluster Assignments4
基于聚类的自监督方法. 构造一个”交换的”预测问题:
\[\mathcal{L}(z_t, z_s) = \ell(z_t, q_s) + \ell(z_s, q_t)\] \[\ell(z_t, q_s) = -\sum_k q_s^{(k)}\log p_t^{(k)}, \qquad p_t^{(k)}=\frac{\exp\left(\frac{1}{\tau}z_t^Tc_k\right)}{\sum_{k'}\exp\left(\frac{1}{\tau}z_t^Tc_{k'}\right)}\]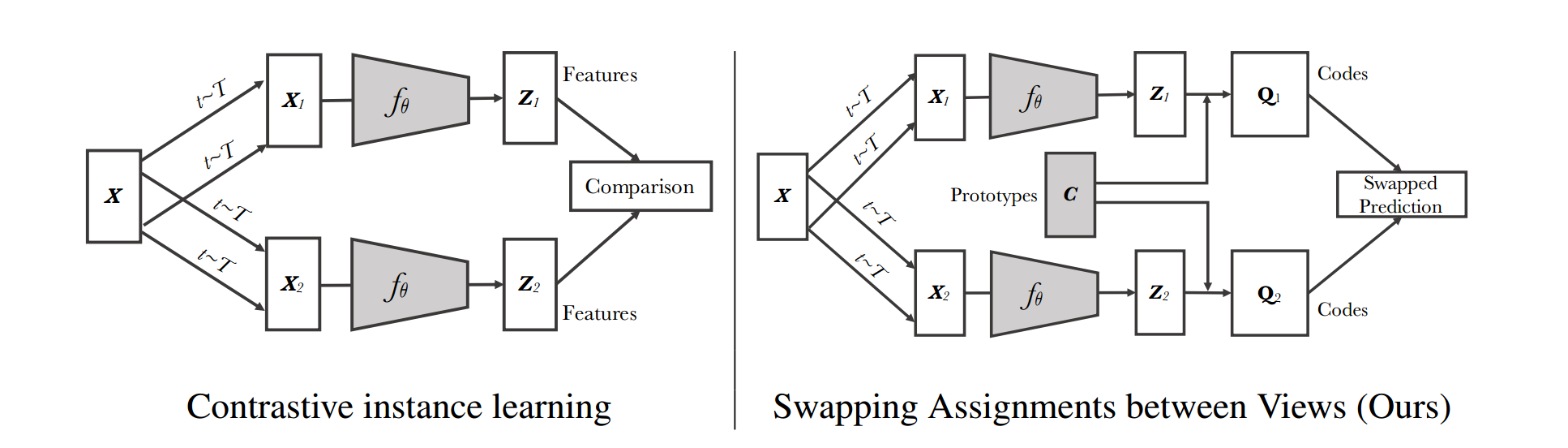
图 4. SwAV
BYOL
DeepMind: Bootstrap Your Own Latent A New Approach to Self-Supervised Learning5
不使用负样本. 有人发现实际还是隐式的用了负样本, 在 \(q_{\theta}\) 里面用了 Batch Normalization. 后来作者又发了一篇 arxiv, 把 BN 换成了 Group Normalization + Weights Standardization, 可以达到和 BYOL 接近的精度.
\[\mathcal{L}=\Vert q_{\theta}(z_{\theta}) - z_{\xi}' \Vert_2^2\] \[\theta \leftarrow \text{Optimizer}(\theta, \nabla_{\theta}\mathcal{L}, \eta) \qquad \xi \leftarrow \xi + (1 − \tau)\theta\]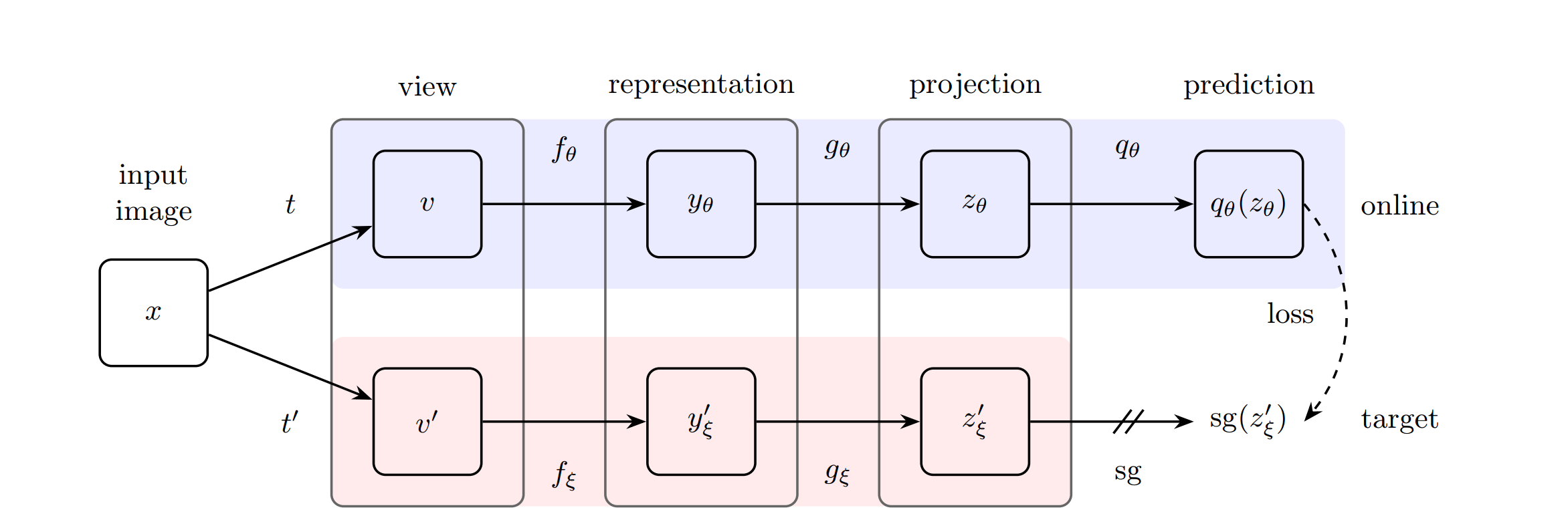
图 5. BYOL
SimCLR V2
Google Brain: Big Self-Supervised Models are Strong Semi-Supervised Learners6
- ResNet-50 –> ResNet-50 (2x) –> ResNet-50 (4x) –> ResNet-152 (3x, Seletive Kernel)
- SimCLR 使用了两层 projection head, SimCLR V2 增加到三层, 并且使用第一层的输出作为最终的结果
- 加入 MoCo 的机制
MoCo V3
FAIR: An Empirical Study of Training Self-Supervised Vision Transformers7
使用了 Visual Transformers, 使用了 InfoNCE 损失:
\[\mathcal{L}_q = -\frac{\exp(q\cdot k^+/\tau)}{\exp(q\cdot k^+/\tau) + \sum_{k^-}\exp(q\cdot k^+/\tau)}\]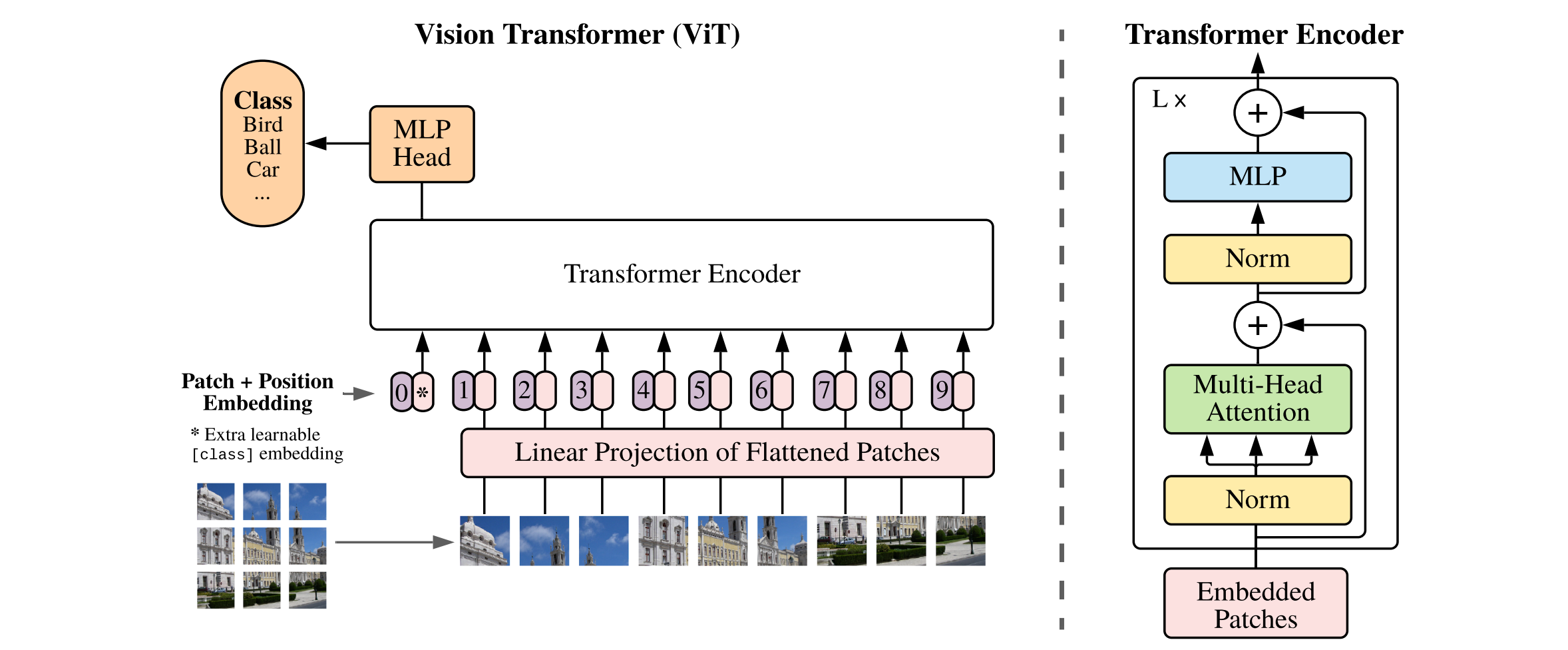
图 6. Visual Transformers, ViT
参考文献
-
Learning deep representations by mutual information estimation and maximization
R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, Yoshua Bengio
[html] In ICLR 2018 ↩ -
Momentum Contrast for Unsupervised Visual Representation Learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, Ross Girshick
[html] In CVPR, 2020 ↩ -
A Simple Framework for Contrastive Learning of Visual Representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton
[html] In ICML, 2020 ↩ -
Unsupervised learning of visual features by contrasting cluster assignments
Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, Armand Joulin
[pdf] In NeurIPS, 2020 ↩ -
Bootstrap Your Own Latent - A New Approach to Self-Supervised Learning
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, Bilal Piot, koray kavukcuoglu, Remi Munos, Michal Valko
[html] In NeurIPS, 2020 ↩ -
Big Self-Supervised Models are Strong Semi-Supervised Learners
Ting Chen, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, Geoffrey Hinton
[pdf] In NeurIPS, 2020 ↩ -
An Empirical Study of Training Self-Supervised Vision Transformers
Xinlei Chen, Saining Xie, Kaiming He
[html] In arXiv:2104.02057 ↩