Tensorflow 中目前主推的科研向API为 tf.keras, 而另一个封装性更高的高阶API Estimator 集成了常用的深度学习模型的操作:
- 训练
- 评估
- 预测
- 导出以供使用
由于 Estimator 的封装性太高, 导致定制性较差. 因此本文的目的是解剖 Estimator 的内部结构, 从而可以让我们在需要时既能使用到 Estimator 的简化性和分布式训练等功能, 也能随心所欲的添加我们额外需要的功能(通过仿照源码重写 Estimator 类, 本文写作时使用的 Tensorflow 版本为 1.13, 此版本中 Estimator 类不允许继承, 因此我们要添加复杂的功能只能重写, 这部分会在后面讲到).
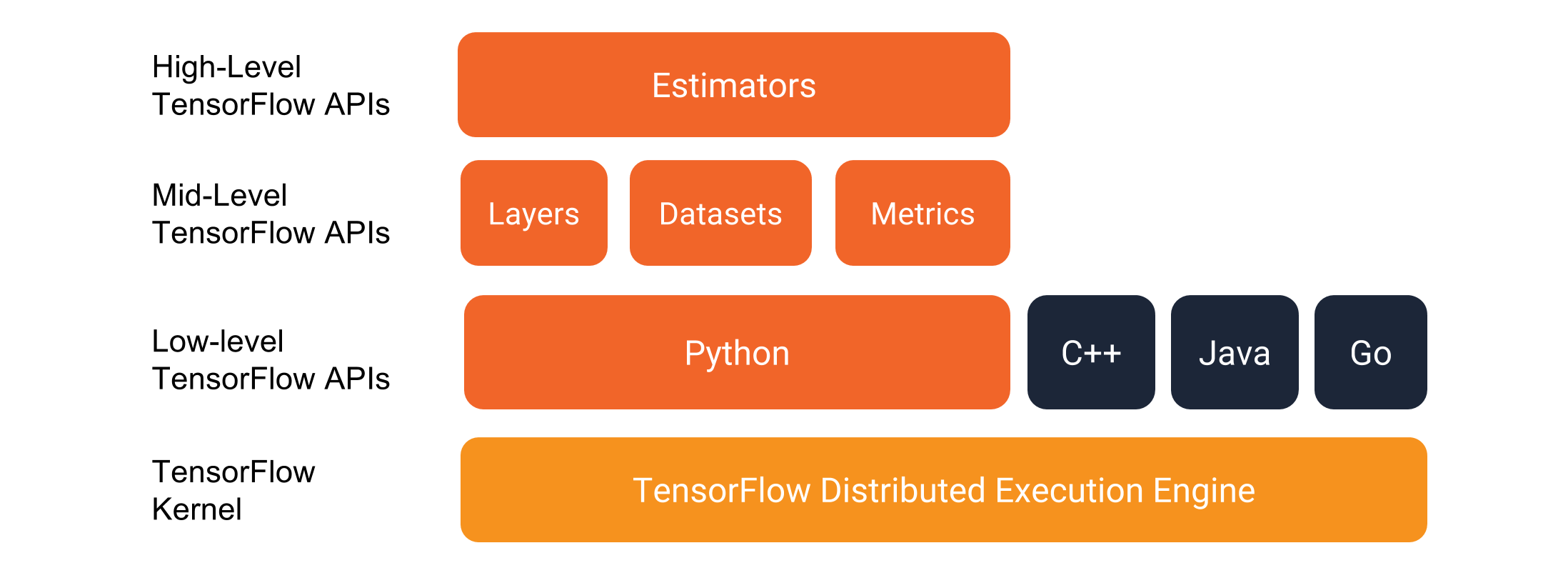
图 1. Tensorflow 多级API编程堆栈
1. Estimator 基本结构
Estimator 本质上就是一个管理员, 他同时负责了模型的训练, 评估, 预测和导出.
1.1 预创建的 Estimator
Tensorflow 官方提供了一些简单的预创建 Estimator 以供直接使用:
tf.estimator.BaselineClassifiertf.estimator.BaselineRegressortf.estimator.DNNLinearCombinedClassifiertf.estimator.DNNLinearCombinedRegressortf.estimator.LinearClassifiertf.estimator.LinearRegressor
但是这类 Estimator 的功能太简单, 难以拓展, 因此常用的是自定义的 Estimator.
1.2 自定义的 Estimator
Estimator 类创建的签名如下:
1
2
3
4
5
6
7
8
class EstimatorV2(object):
def __init__(self,
model_fn,
model_dir=None,
config=None,
params=None,
warm_start_from=None):
pass
使用 Estimator 训练/验证/预测模型的代码如下:
1
2
3
4
5
6
7
8
# 创建 Estimator
esti = tf.estimator.Estimator(model_fn, model_dir, config, params)
# 训练
esti.train(input_fn, hooks, steps, max_steps, saving_listeners)
# 验证
esti.evaluate(input_fn, steps, hooks, checkpoint_path, name)
# 预测
esti.predict(input_fn, predict_keys, hooks, checkpoint_path, yield_single_examples)
创建自定义的 Estimator 需要编程人员编写以下几部分:
- 模型函数
model_fn - 数据输入函数
input_fn - 定义所有传入 Estimator 的参数:
config,params及其他参数 - 钩子
hooks
1.3 模型函数
函数参数. 模型函数应当是一个可以调用的函数, 其函数签名如下:
1
2
def model_fn(features, labels, mode, params, config):
pass
其中 mode, params, config 参数是可选的, 即自定义 model_fn 时这三个参数可以不使用, 比如可以定义成
1
2
def model_fn(features, labels, mode, params):
pass
其中 features 和 labels 是数据输入函数 input_fn 返回的两个对象, 通常表示数据特征和对应的标签. features 和 labels 既可以是 Tensor, 也可以是 Python 字典, 其值为 Tensor, 因此这两个参数可以通过字典传递任何数据(一批)到模型中使用.
Estimator 的训练流程(session.run())是封装在类内部的, 同时没有提供 feed_dict 的参数结构, 因此我们不能像 Tensorflow 低阶API中那样使用 placeholder 馈送数据到模型中. 官方建议的方式是用 tf.data.Dataset 类创建数据输入管线, 其用法也相当灵活, 可以参考 Tensorflow 数据输入管线, 这里就不再赘述. 其最终目标就是数据输入函数 input_fn 返回的必须是 tf.Tensor 或其嵌套(nested)对象, 从而 model_fn 接收到的也是 Tensor.
函数体. 接下来就只需要在 model_fn 内部写入创建模型的代码, 可以使用 tf.layers API(在2.0版本中被移除了)或 tf.contrib.slim API(也在2.0版本中被移除了)或低阶API(tf.Variable + tf.nn).
函数体内需要使用 mode 参数来对训练/验证/预测定义不同的代码. mode 的取值为:
tf.estimator.ModeKeys.TRAINtf.estimator.ModeKeys.EVALtf.estimator.ModeKeys.PREDICT
分别对应了训练/验证/预测模式.
函数返回. 模型函数应当返回一个 tf.estimator.EstimatorSpec 对象. EstimatorSpec 是一个很简单的类, 作用仅仅是保存模型函数输出对象(如模式, 训练操作, 损失, 要预测的Tensor, 评估指标, 钩子等). 该类的签名为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class EstimatorSpec(
collections.namedtuple('EstimatorSpec', [
'mode', 'predictions', 'loss', 'train_op', 'eval_metric_ops',
'export_outputs', 'training_chief_hooks', 'training_hooks', 'scaffold',
'evaluation_hooks', 'prediction_hooks'
])):
def __new__(cls,
mode,
predictions=None,
loss=None,
train_op=None,
eval_metric_ops=None,
export_outputs=None,
training_chief_hooks=None,
training_hooks=None,
scaffold=None,
evaluation_hooks=None,
prediction_hooks=None):
pass
一般来说, 在不同的模式下, 需要返回不同的 EstimatorSpec:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# Construct networks...
if mode == tf.estimator.ModeKeys.TRAIN:
# ...code...
return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)
if mode == tf.estimator.ModeKeys.EVAL:
# ...code...
metrics = {'accuracy': accuracy}
tf.summary.scalar('accuracy', accuracy[1])
return tf.estimator.EstimatorSpec(mode=mode, loss=loss, eval_metric_ops=metrics)
if mode == tf.estimator.ModeKeys.PREDICT:
# ...code...
predicted_classes = tf.argmax(logits, 1)
predictions = {
'class_ids': predicted_classes[:, tf.newaxis],
'probabilities': tf.nn.softmax(logits),
'logits': logits,
}
return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)
1.4 数据输入函数
函数参数. 数据输入函数不需要固定格式, 但是如果有 mode, params, config参数的话, Estimator 会把自身的这三个参数传入 input_fn, 函数签名如下:
1
2
3
4
5
6
7
# 仅从 Estimator 传入 mode 参数
def input_fn(args1, args2, kwargs1, kwargs2, mode):
pass
# 从 Estimator 传入 mode, params 和 config 参数
def input_fn(args1, args2, kwargs1, kwargs2, mode, params, config):
pass
通常使用 mode 参数的话方便统一使用 input_fn 同时定义训练/验证/预测模式下的数据加载器(data loader). 上面已经说过了, input_fn 需要返回 Tensor 或者嵌套的 Tensor.
函数体. 建议使用 tf.data.Dataset 构造数据集.
函数返回. 需要注意的是 input_fn 返回的应当是 tf.data.Dataset 的实例, 不需要调用 make_initialiable_iterator() 和 get_next() 函数. Estimator 会负责从 Dataset 创建迭代器并获取下一批数据并送入 model_fn. 下面解析 Estimator 源码时会看到内部创建迭代器的过程.
1.5 Estimator 参数
Estimator 中关键的参数主要是 params 和 config.
1.5.1 config 参数
config 参数是一个 tf.estimator.RunConfig 实例, 包含了配置设备, 训练流程控制, 分布式等参数. 类的签名如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class RunConfig(object):
"""This class specifies the configurations for an `Estimator` run."""
def __init__(self,
model_dir=None,
tf_random_seed=None,
save_summary_steps=100,
save_checkpoints_steps=_USE_DEFAULT,
save_checkpoints_secs=_USE_DEFAULT,
session_config=None,
keep_checkpoint_max=5,
keep_checkpoint_every_n_hours=10000,
log_step_count_steps=100,
train_distribute=None,
device_fn=None,
protocol=None,
eval_distribute=None,
experimental_distribute=None,
experimental_max_worker_delay_secs=None):
pass
下面对一些参数做简要的解释:
model_dir参数和 Estimator 中的同名参数相同, 两种方式都可以提供, 同时提供必须保证相同. 该参数指定了summary和模型保存的文件夹.session_config是一个tf.ConfigProto实例, 用于提供硬件设备配置, 如显存使用率, 显存是否按需增长, 是否允许变量所在设备的妥协(没有GPU时放在CPU上), CPU的使用数量, 操作内并行和操作间并行的线程数量等等.train_distribute用来指定分布式训练策略, 如tf.distribute.MirroredStrategy.
1.5.2 params 参数
params 参数就是一个Python字典, 可以传入任何用户定义的参数, 从上面的讨论我们知道该参数可以传递到 model_fn 和 input_fn, 为用户参数传递提供了方便.
1.5.3 warm_start_from 参数
这是一个可选参数, 用于在开始训练之前载入热身参数(如可以避免模型冷启动导致的loss突变).
- 该参数可以传入一个Tensorflow检查点, 此时会把计算图中所有的可训练参数从检查点中初始化.
- 该参数也可以传入一个
tf.estimator.WarmStartSettings的实例, 该类也是一个属性类, 提供了参数可以指定需要从检查点初始化的变量, 从而避免初始化所有变量.
Estimator 是使用 tf.train.init_from_checkpoint() 载入检查点的.
1.6 钩子
(未完待续)