- 1. (ICLR 2015) Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
- 2. TPAMI 2017: DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
- 3. arXiv 1706: Rethinking Atrous Convolution for Semantic Image Segmentation
- 4. ECCV 2018: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
- Reference
2020-11-20 更新
1. (ICLR 2015) Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs1
作者: Liang-Chieh Chen(UCLA), George Papandreou(Google Inc.), Iasonas Kokkinos(CentraleSuplec and INRIA), Kevin Murphy(Google Inc.), Alan L. Yuille(UCLA)
DeepLab V1 贡献:
- 速度: 引入膨胀卷积(
atrous卷积)提高处理速度(8fps) - 准确度: PASCAL VOC-2012 分割任务上取得 start-or-the-art (test set: 71.6%), 超过第二名7.2%
- 简单性: 仅包含 (1) DCNN (2) CRFs 两个步骤
膨胀卷积
在 VGG-16 模型中原始图像共下采样 5 次, 缩小为输入图像的 \(1/32\). 本文目标是语义分割, 而缩小 32 倍的图像无法准确的定位分割的各部分, 而直接减少 VGG-16 的两个 block 又会影响特征的提取, 因此引入膨胀卷积既能增大感受野, 也能减少下采样的次数. 一维的膨胀卷积如下图所示.
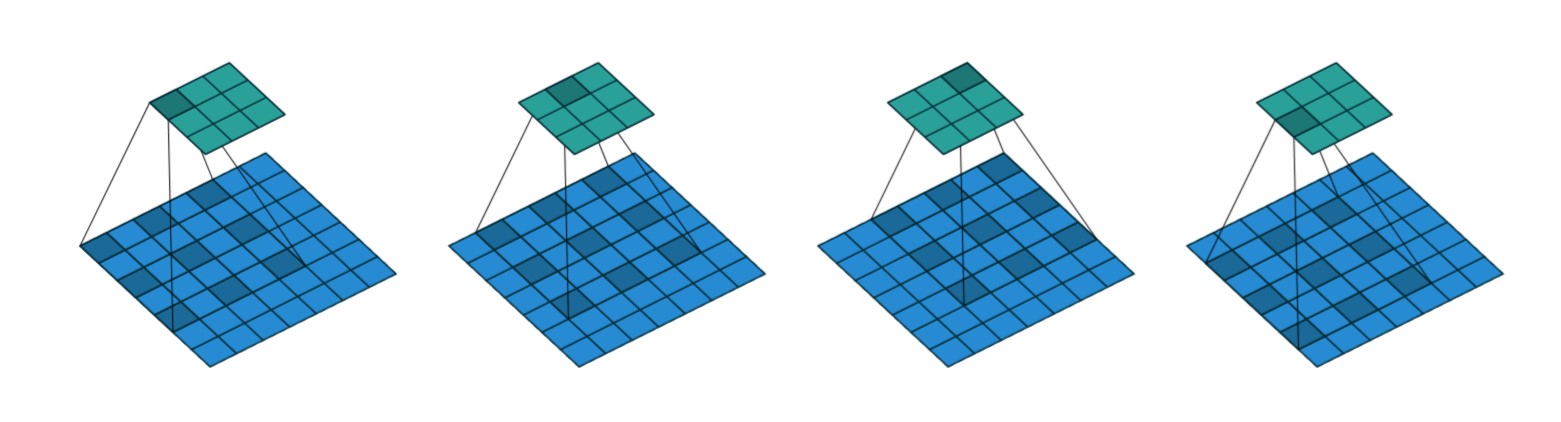
图 1. Atrous Convolution
其卷积方式就是在卷积核中引入”空洞”, 使得不增加卷积核参数的情况下能够扩大卷积核的感受野, 用公式表示为(二维情况)
\[y(i, j) = \sum_{m = 1}^M\sum_{n = 1}^Nx(i + dm, j + dn)w(m, n),\]其中 \(M, N\) 是卷积核两个维度上的长度, \(d > 1\) 时为膨胀卷积, \(d = 1\) 时为普通卷积.
代码实现中 VGG-16 最后两个 MaxPooling 层步长改为 1, 最后三个卷积层改为 \(2\times\) 膨胀卷积, 第一个全连接层改为 \(4\times\) 膨胀卷积, 使用 \(4\times4\) 的卷积核(在精度略微损失(损失了0.5)的前提下相比原来 \(7\times7\) 的卷积核速度翻倍).
CRFs 恢复边界细节
在分类精度和定位精度上有一个自然的 trade-off, 网络越深, 下采样的次数越多, 分类的精度就越高, 同时损失的位置信息也越多. 目前文献中针对该问题有三类主流的方法:
- 利用多个网络层的信息
- 采用超像素表示
- 全连接 CRFs2 (这也是本文使用的方法)
实验结果
最终实验中最好的配置 DeepLab-CRF-LargeFOV (val set: mIOU = 67.64%)为 \(3\times3\) 的卷积核, \(12\times\) 的膨胀卷积, 参数量最少, 精度与 \(7\times7\) 的卷积核相同, 速度接近前者的 3.5 倍. 此外本文实验中还引入了 multi-scale 的策略(FCN 的做法, 把多个层次的特征图上采样后), 也提升了一定的精度(DeepLab-MSc-CRF-LargeFOV val set: mIOU=68.70%).
2. TPAMI 2017: DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs3
作者: Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, Alan L. Yuille
DeepLab V2 主要贡献:
- 提出膨胀空间金字塔池化(atrous spatial pyramid pooling, ASPP)
多尺度图像表示
多尺度是目前针对同时有大目标和小目标物体的一种比较流行的策略.
利用多尺度图像特征的方法有很多种:
- 相当于标准的多尺度处理
- 编码-解码器
- 膨胀卷积代替下采样
- ASPP 结构
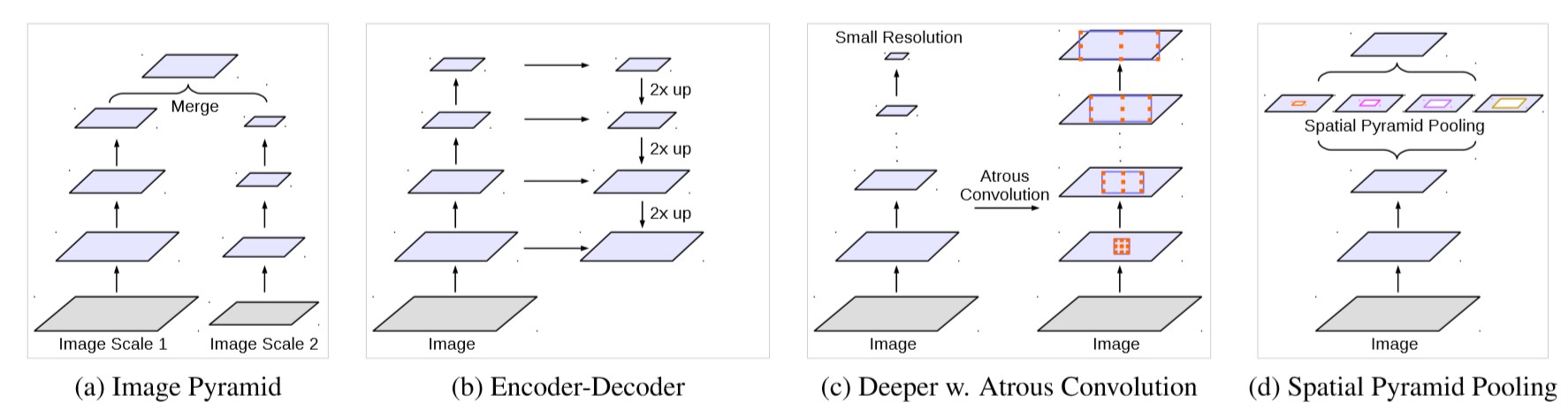
图 2. Alternative architectures to capture multi-scale context
本文试验了第 1 种和第 4 种.
标准的多尺度处理: 并行输入多个尺度的图像(经过缩放的), 并行的 DCNN 之间共享参数. 为了产生最终的结果, 多个尺度的输出经过双线性插值为原始图像的大小, 然后进行融合, 融合的方式选择 max() 函数.
ASPP: 结构如下图所示, 使用不同的膨胀率使得网络提取到不同尺度的信息.
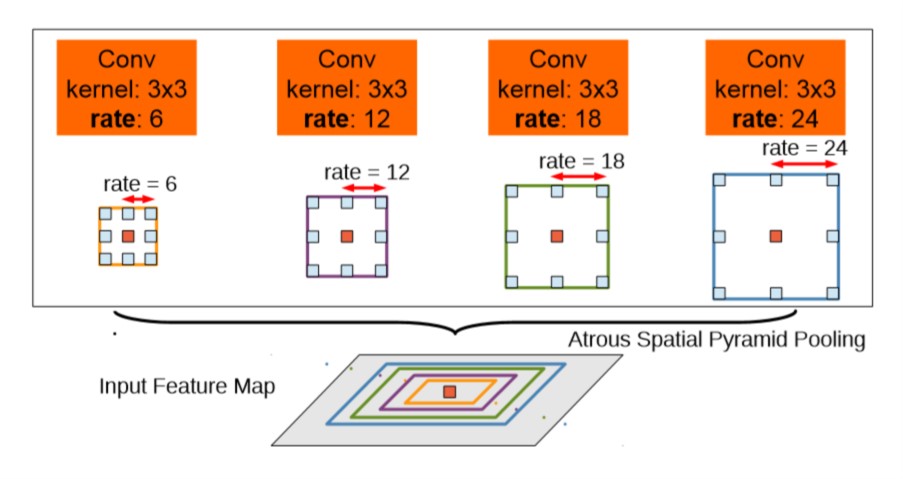
图 3. ASPP 结构
使用了 ASPP 结构的 DeepLab 网络称为 DeepLab-ASPP, 其中 ASPP 结构增加在了最后一个池化层(已修改步长为 1)之后, 如下图(d)所示.
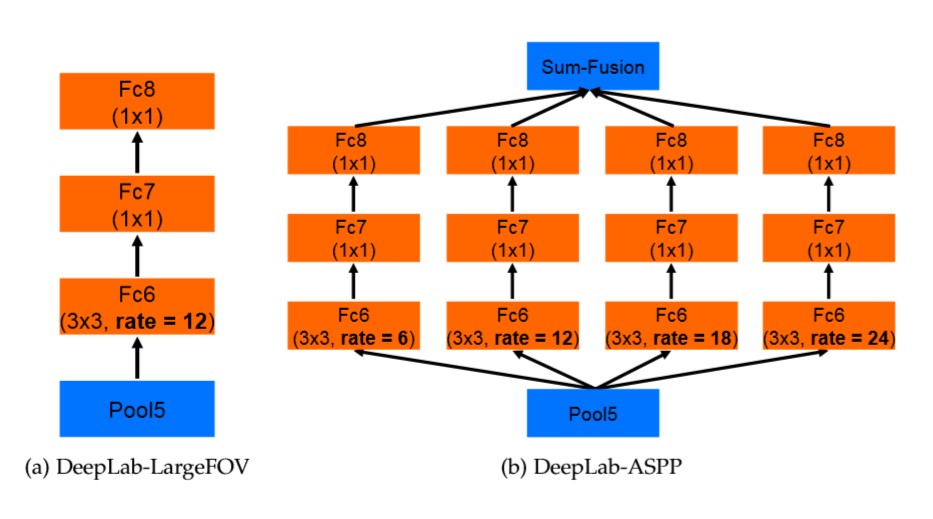
图 4. DeepLab-ASPP
实验结果
仍然在最后增加 CRFs 修整边界, 以 Resnet-101 作为主干网络, DeepLab-ASPP-CRFs 达到了 mIOU=79.7% 的精度.
3. arXiv 1706: Rethinking Atrous Convolution for Semantic Image Segmentation4
作者: Liang-Chieh Chen, George Papandreou, Florian Schroff, Hartwig Adam
DeepLab V3 贡献:
- 把 image-level 的特征整合到 ASPP 模块中
- 给出较为详细的实现细节和训练经验
在更深的层使用膨胀卷积
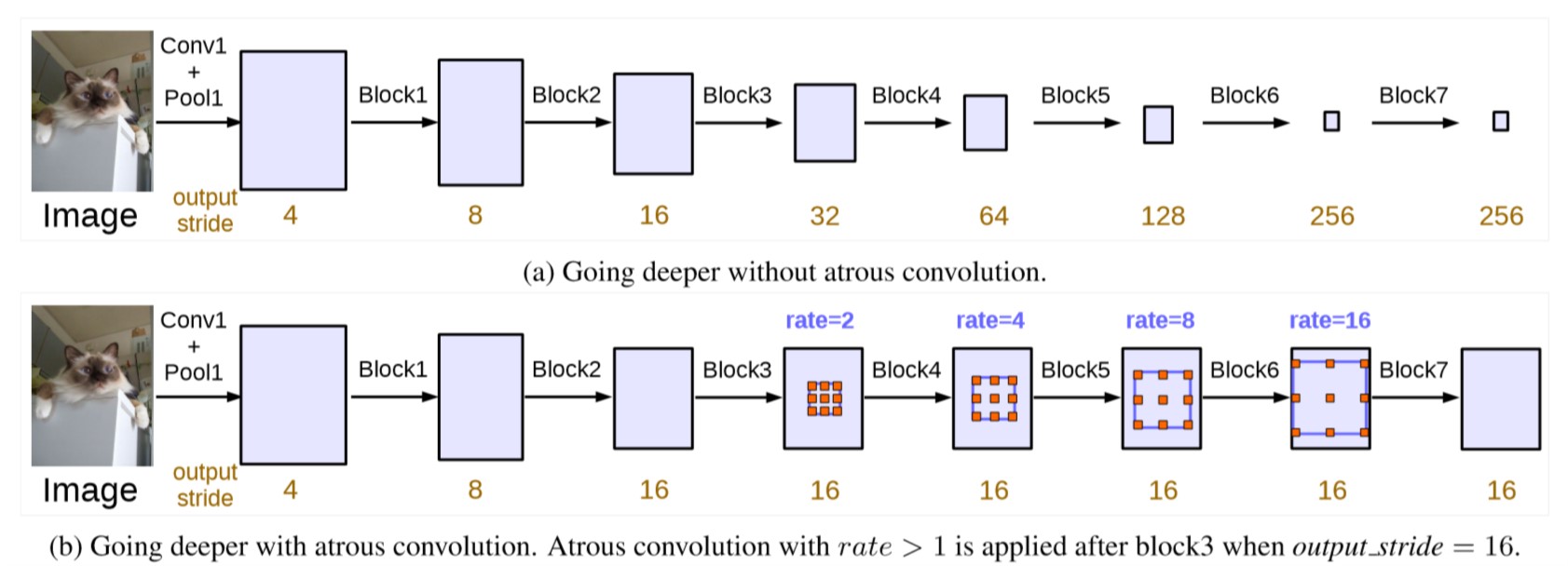
图 5. 使用膨胀卷积的级联结构
这一节主要对比了深度网络模型中使用和不使用膨胀卷积, 并说明了膨胀卷积的优势. 主干网络选择了 ResNet, 使用膨胀卷积的 ResNet 把 Block4 到 Block7 的卷积替换为膨胀卷积(按照 DeepLabv1 相应的池化也应当改为步长为 1 避免减少图像分辨率), 如上图所示. 由于每个 ResBlock 中包含 3 个卷积, 本文采用了 Multigrid 的策略, 每个 ResBlock 设置一个基准膨胀率 \(Baserate\) (即上图中的 rate), 给定一个长度等于 3 的网格 \(Multigrid\) (就是每个 ResBlock 中卷积层的数目), 那么每个卷积层的膨胀率就可以通过公式计算
\[rate = Baserate * Multigrid.\]举个例子, block4 的基准膨胀率是 2, 给定网格 \(Multigrid = (1, 2, 4)\), 那么最终 block4 的三个卷积层的膨胀率依次为 \(rates = 2 * (1, 2, 4) = (2, 4, 8)\).
ASPP 再思考
DeepLab V2 中的 ASPP 直接接在了网络头部, 那么特征图大小和卷积核大小不变时, 随着膨胀率的增大, 有效的卷积核权重会越来越少. 极端情况下比如 \(3\times3\) 的卷积核仅有中间的一个值有效(其他值都作用在填充的 0 上了), 那么 \(3\times3\) 的卷积核就退化成了 \(1\times1\) 的卷积核. 所以本文加入了 image-level 的信息, 对最后一个特征图应用全局平均池化, 然后使用 \(1\times1\) 的 256 个卷积核和批正则化, 然后上采样到需要的大小和其他三种膨胀率的卷积分支融合. 具体如下图所示.
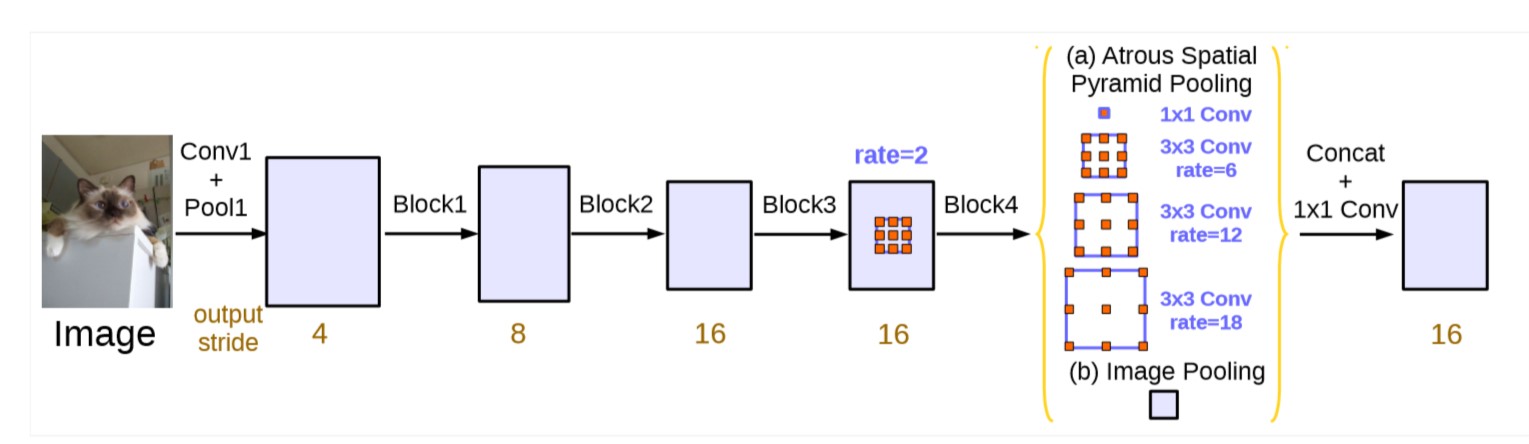
图 6. ASPP 的平行结构, 使用 image-level 的特征做增广
实验细节和实验结果
- 学习率策略: 多项式学习率, \((1 - \frac{iter}{max_iter})^{power}\), 其中 \(power=0.9\).
- 裁剪大小: 为了使大的膨胀率仍然有效, 增大裁剪大小到 513 像素.
- 批正则化: 本文增加在 ResNet 头部的模块均包含批正则化结构. 首先使用
output_stride=16, batch_size=16, decay=0.9997, learning_rate=0.007在增广的trainaug数据集上训练 30K 步, 然后固定 BN 层, 使用output_stride=8, batch_size=8, learning_rate=0.001在 PASVAL VOC 2012 数据集trainval上训练 30K 步. 先用输出步长 16 训练的好处是输出图片小, 可以加快训练速度, 然后再用步长为 8 的图片训练, 提高定位精度. - 上采样 logits: 由于网络输出的大小缩小为 groundtruth 的 \(1/8\), 因此需要对齐, 本文发现训练时对输出上采样到原始图像大小要比把 groundtruth 下采样到 \(1/8\) 更好.
- 数据增广: 放缩(\(0.5~2.0\)), 随机左右翻转.
DeepLab V3 在 PASVAL VOC 2012 测试集上达到 85.7% 的精度, 接近当时最好的水平. 如果使用在 ImageNet 和 JFT-300M 数据集上预训练的 ResNet-101 作为主干网络, 则可以达到 86.9% 的精度.
4. ECCV 2018: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation5
作者: Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam
DeepLab V3+ 贡献:
- 提出一个编码-解码结构, 采用 DeepLab V3 作为编码器
- 在编码器中(提取特征), 可以利用膨胀卷积任意的控制精度和速度的平衡
- 采用 Xception 模型用于分割任务, 并把 depthwise-separable convolution 应用到 ASPP 和解码器结构中, 使得速度更快, 更强大.
- 在 PASVAL VOC 2012 数据集和 Cityscapes 数据集上成为了新的 state-of-the-art.
深度可分离卷积
Depthwise separable convolution 就是把一个标准的卷积分解成一个 depthwise convolution(不同通道应用不同的) 和一个 point-wise convolution(\(1\times1\) 卷积), 大幅减少计算量. (Tensorflow>=1.8 中的 nn 模块已经实现了第一个分步的 tf.nn.depthwise_convolution() 和总的分解 tf.nn.separable_convolution()).
编码-解码器设计
DeepLab V3 去掉计算 logits 的层后作为 Encoder. 由于 DeepLab V3 结构最后输出的 output_stride=16, 因此需要 16 倍的上采样. 考虑到直接上采样 16 倍仍然会使网络丢失过多信息而在细节上不够精确, 因此 Decoder 把这个上采样分成两部分:
- 把
DeepLab V3的输出双线性上采样 4 倍后与低层特征拼接 - 低层特征可能有过多的通道数(256 或 512)而把 Encoder 中的特征掩盖掉(有 256 个通道), 因此低层特征首先要经过一个 \(1\times1\) 的卷积调整通道数, 然后再拼接
- 拼接的特征经过几层 \(3\times3\) 卷积融合特征, 最后再次双线性上采样 4 倍.
整个网络结构如下图所示.
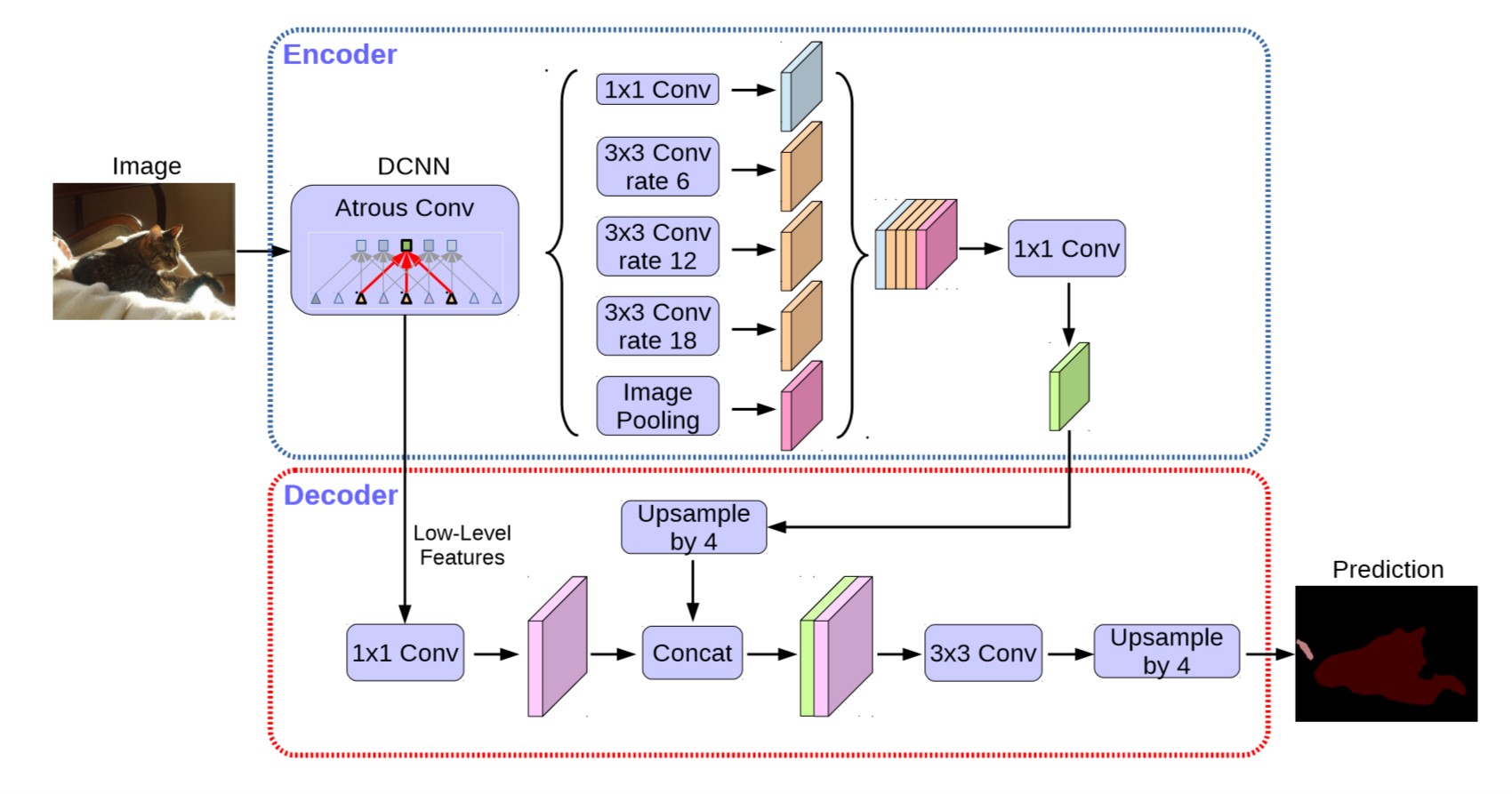
图 7. DeepLab V3+ 结构
Xception 结构的递进修改
- 原始: Xception
- MSRA的修改: Aligned Xception
- 本文的修改: (1) 继承 Aligned Xception, 但不修改所有的层 (2) 所有最大池化替换为
depthwise separable convolution(3) 添加额外的 BN 层和激活函数层.
修改后的结构如下图所示.
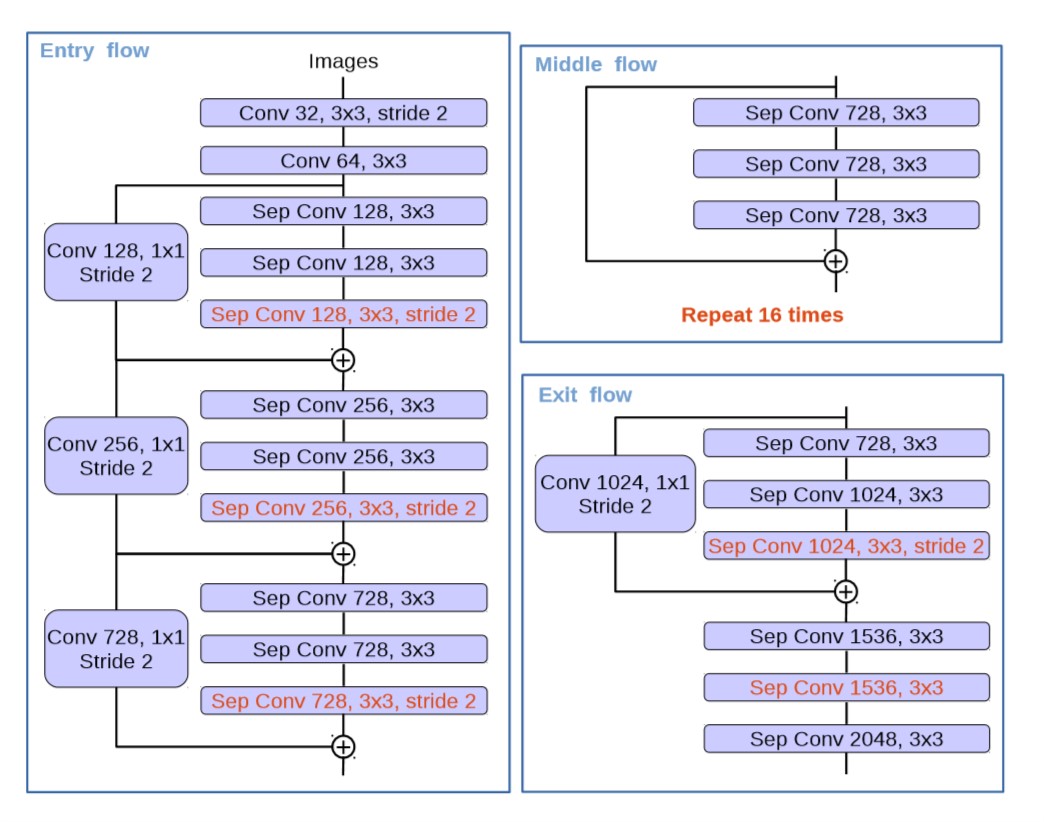
图 8. 改进的 Xception
实验结果
DeepLab V3+ (Xception) 在 PASCAL VOC 2012 测试集上获得 mIOU=87.8% 的精度. DeepLab V3+ (Xception-JFT) 获得 mIOU=89% 的精度.
Reference
-
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, Alan L. Yuille.
[html]. In ICLR, 2015. ↩ -
Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials
Philipp Krähenbüh, Vladlen Koltun.
[html] ↩ -
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille.
[html]. TPAMI 2017. ↩ -
Rethinking Atrous Convolution for Semantic Image Segmentation
Liang-Chieh Chen, George Papandreou, Florian Schroff, Hartwig Adam.
[html]. arXiv: 1706.05587, 2017. ↩ -
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam.
[html]. In ECCV, 2018. ↩