光流(Optical flow or optic flow)是关于视域中的物体运动检测中的概念。用来描述相对于观察者的运动所造成的观测目标、表面或边缘的运动。光流法在样型识别、计算机视觉以及其他影像处理领域中非常有用,可用于运动检测、物件切割、碰撞时间与物体膨胀的计算、运动补偿编码,或者通过物体表面与边缘进行立体的测量等等。

1. FlowNet
想法: 探索CNN在学习不同尺度上特征的能力, 以及通过这些特征寻找图像之间的关联.
1.1 相关工作
总结一下就是: (1)以前计算光流的方法都是从Horn 和 Schunck的变分方法衍生而来的(2)已有的用到CNN的方法都是基于小块(pased based)的. 所以本文是用完整图像计算光流的头一篇.
涉及到逐像素预测的CNN的应用包括(1)语义分割(2)深度预测(3)关键点检测(4)边缘检测. 当然了, 本文的光流预测也是逐像素的.
1.2 网络结构
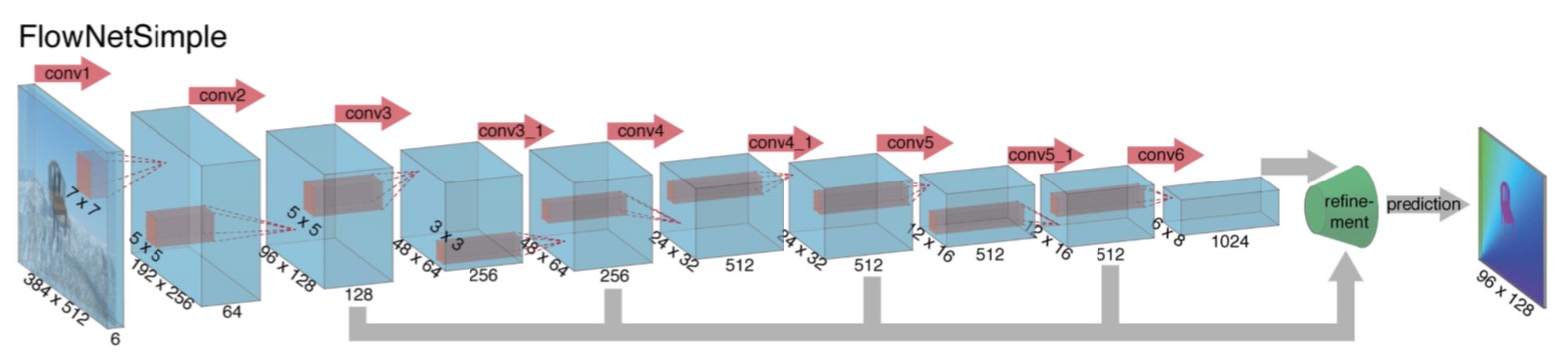
FlowNetSimple 结构示意图
FlowNetSimple: 简单地把两个图片作为两个通道输入网络.
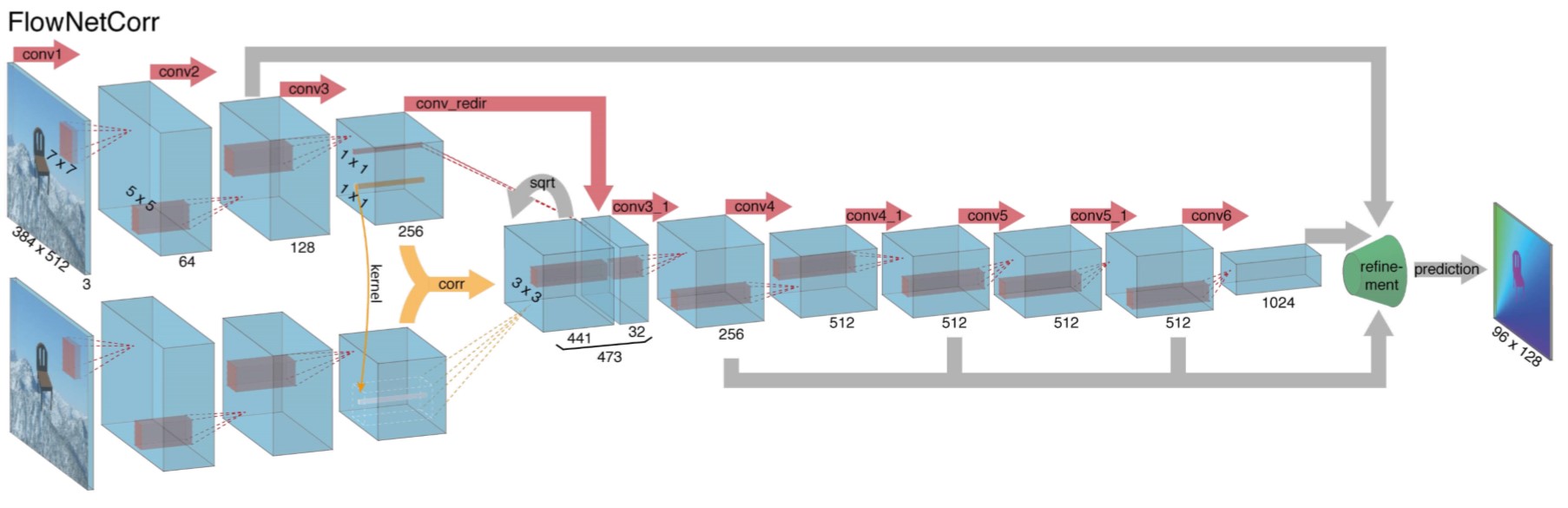
FlowNetCorr 结构示意图
FlowNetCorr: 两个图片分别在两个自网络学习, 中间通过correlation layer融合在一起. correlation layer是两组特征图之间的卷积, 即大小为[h, w, c]的图像(记为A)中的 \(k\times k\) 的patch和另一个大小为[h, w, c]图像(记为B)中的patch之间的卷积. 由于计算量太大(\(h^2\times w^2\) 次卷积), 所以本文假设位移大小是有限的(最大位移大小为 \(d\)), 这样对于图A中的每一个anchor上的patch, 不必遍历图B的所有anchor, 仅需要遍历 \(D\times D\) (其中 \(D=2d+1\))个anchor上的patch即可, 因此计算量降低到 \(h\times w\times D^2\). 此外我们给出卷积的公式:
其中 \(<\cdot>\) 表示向量的点积, 向量的长度就是特征图的通道数.
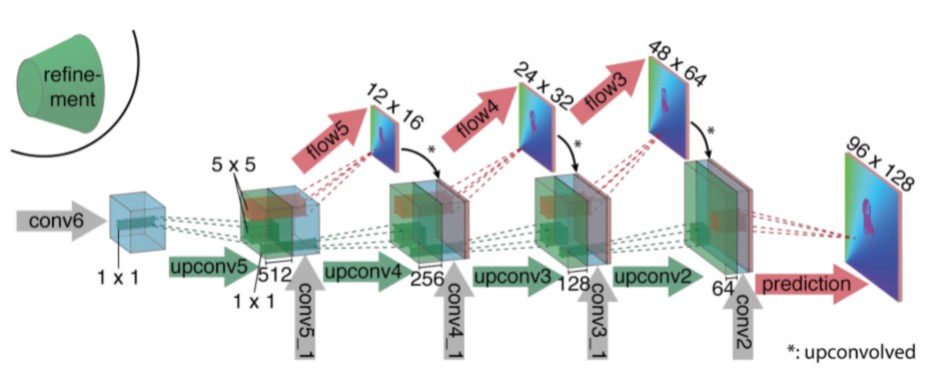
末尾的 Refinement(Decoder) 结构
Refinment部分是接在前面两个网络的末尾用于增大光流图像的分辨率, 方法是反卷积, 网络最后输出图像的边长是原图的 \(1/4\), 最后直接插值回原始图像大小. 最后两次上采样用插值代替因为实验效果最好.
但实际上最终的两次上采样是通过variational refinement实现的. 这样虽然相比双线性插值增大了计算量, 但是能够得到变分法的好处: 分割更加光滑且准确.
网络的输出是光流场, 实际上是一个大小为[h/4, w/4, 2]的向量场, 每个点都预测当前点的光流\((u, v)\), 损失函数为端点误差(endpoint error, EPE):
其中 \((u_{GT}, v_{GT})\) 是ground truth.
1.3 实验及结果
已有的数据集(Middlebury: 72, KITTI: 194, Sintel: 1041)大小都无法满足神经网络训练的需求, 因此本文造了一个假数据集: 飞天椅(Flying Chairs), 包含22872帧图片. 训练时包含的数据增强不再赘述.
实验时FlowNetS和FlowNetC各包含三种配置: 默认, +v: 变分方法, +ft: 微调. 其中微调是用数据集Sintel的Clean和Final版本以 \(1e-6\) 的学习率进行的.
结果总结如下:
- 除Chairs数据集外, 传统方法都要比本文的方法好. 说明了神经网络方法在大数据集下可以表现的更好.
- FlowNetC 基本上都要比FlowNetS好, 除了KITTI数据集. 推测的原因是KITTI数据集的位移都比较大, FlowNetC由于参数设定的限制, 无法对大位移的图像很好的捕捉光流.
1.3.1 演示:
2. FlowNet 2.0
2.1 Introduction
继承了FlowNet的优势:
- 能处理大的位移
- 在光流场中对小的细节的估计
- 对具体的场景可以学习潜在的先验
- 快的运行时间
FlowNet 2.0有其额外的优势:
- 能处理小的位移
- 解决了光流场中的噪声artifacts的问题
- FlowNet老版没比过传统方法, 2.0版和传统方法持平
FlowNet 2.0 的贡献:
- Dataset Schedule: 评估了数据集排序的影响
- 引入了一个变形操作, 并说明了使用该操作stack多个网络能够显著提高表现
- 针对小的位移和现实世界的数据给出了解决方案
2.2 数据集排序(Dataset Schedule)
这一部分讨论了同时有多个数据集可训练时, 数据集的训练次序是重要的. 此外作者还根据多个数据集设计了三种训练的策略: (1) \(S_{short}\) (2) \(S_{long}\) (3) \(S_{fine}\)
三种策略的(1)总迭代次数(2)学习率衰减规则(3)是否fine-tune 有所不同, 如下图所示:
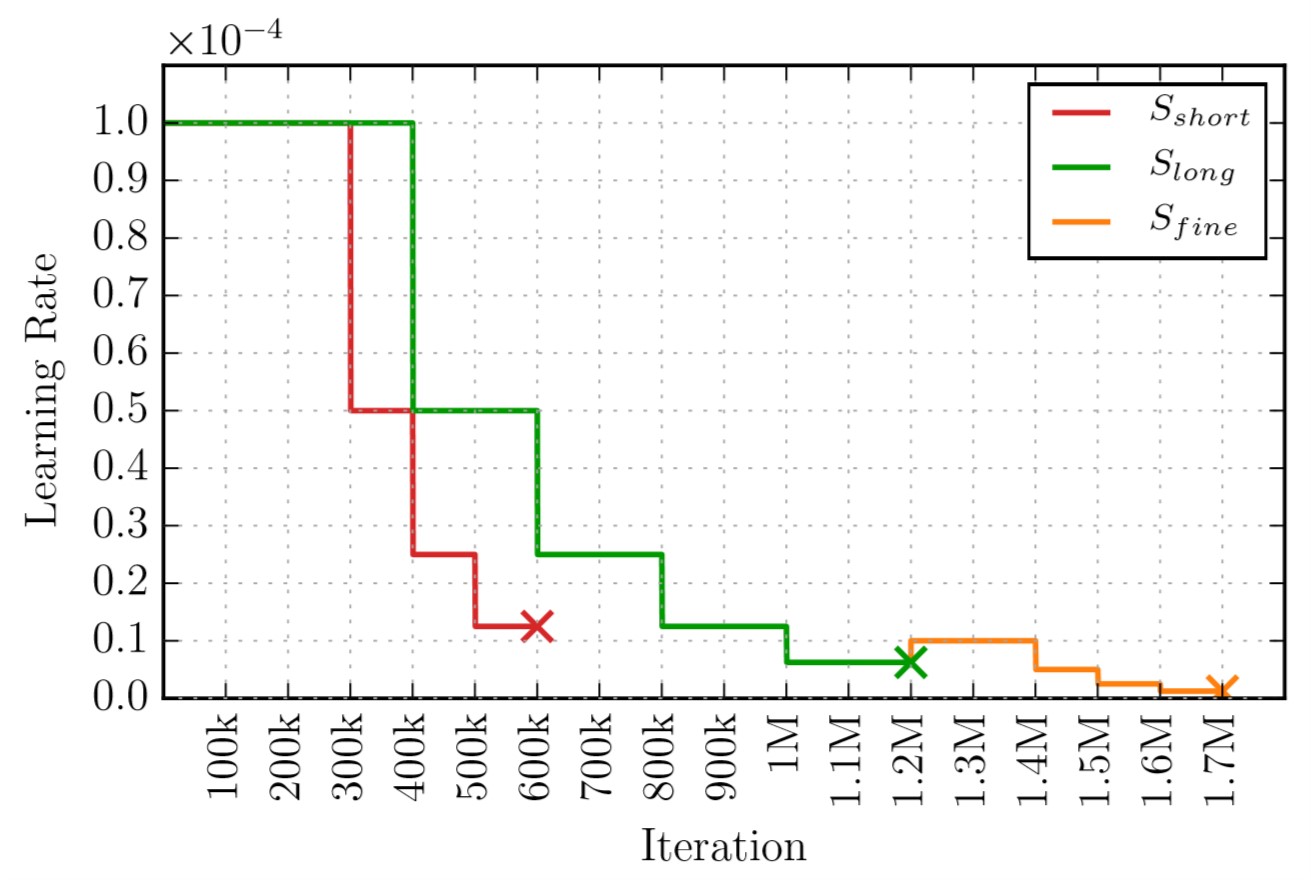
学习率规划方式
注意, 其中 \(S_{short}\) 和FlowNet一文中的训练方式基本相同, 除了使用 \(1e-6\) 的学习率热身(warm-up).
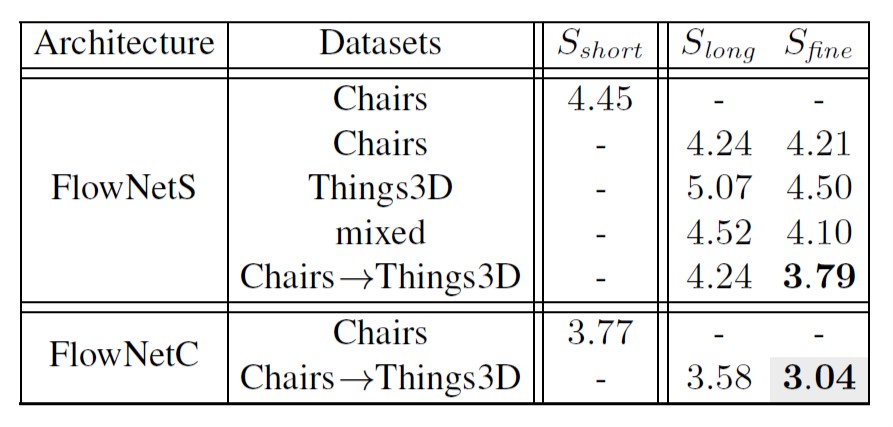
训练FlowNet的结果
从上表中可以看出先使用Chairs训练, 再使用Things3D做fine-tune比分开训练和直接混合训练都要好. 因此作者推测简单的数据集有利于网络学习颜色匹配的概念而不被复杂的属性混淆, 因此先用简单的数据集训练, 再使用复杂的数据集训练可以得到更好的效果.
2.3 堆叠网络(Stacking Networks)
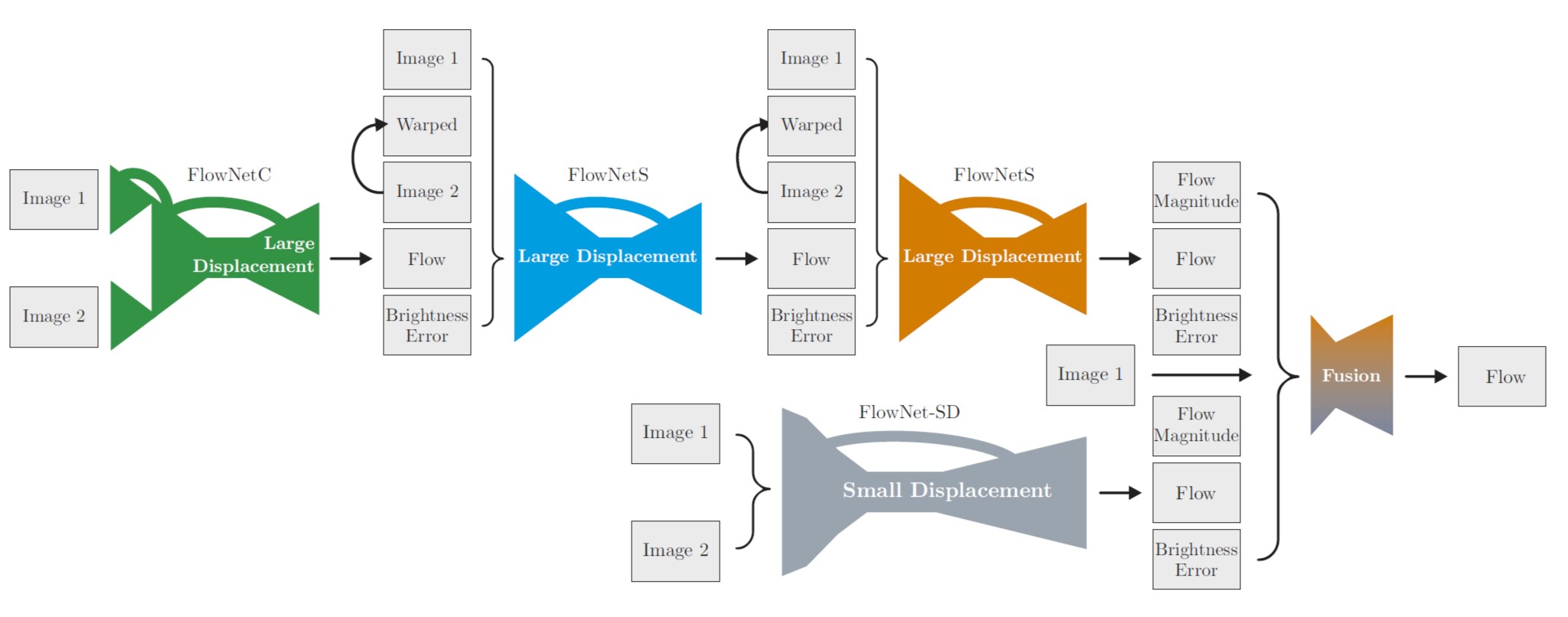
FlowNet 2.0
2.3.1 堆叠两个网络
堆叠网络是指一个网络的输出作为另一个网络的输入, 通过多个网络的迭代优化光流场. 其中后一个网络的输入包含几个部分:
- 原始图像 \(I_1\)
- 原始图像 \(I_2\)
- 光流场 \(w_i\) (其中 \(i\) 指堆叠网络中的第 \(i\) 个)
- \(I_2\) 作用 \(w_i\)之后的结果 \(\tilde{I}_{2, i}\)
- 误差 \(e_i = \lVert\tilde{I}_{2, i} - I_1\rVert\) (brightness error)
五个部分如上图所示. 作者首先使用两个FlowNetS网络堆叠训练来提炼训练准则, 并得到如下结论(表格参考原文):
- 两个网络中间不加变形(warp), Chairs的结果比Sintel更好, 说明有过拟合发生(其他细节参考原文)
- 加了变形的堆叠网络效果更好
- 对第一个网络增加监督有利于提升效果(类似于深度监督)
- 最好的结果是固定第一个网络的参数, 只训练第二个网络(其他细节参考原文)
2.3.2 堆叠多个网络
作者首先实验了不同数量的channels在最后的精度和速度之间的trade-off, 并选择了一个比较理想的状态, 即原始FlowNet网络channels数量的 \(3/8\).
其次进行多个网络的堆叠实验, 符号 \(FlowNet2\) 表示使用Chairs->Things3D训练策略的网络, \(C\) 和 \(S\) 表示两种不同的网络, 并用连续的 \(C\) 和 \(S\) 表示堆叠顺序, 大小写字母分别表示使用1倍的channels还是 \(3/8\) 的channels. 实验表明:
- \(FlowNet2-CSS\) 比 \(FlowNet2-C\) 有30%的提升, 而 \(FlowNet2-C\) 比原始的 \(FlowNetC\) 有50%的提升.
- \(FlowNet2-ss\) 在速度和精度上均好于 \(FlowNet2-S\), \(FlowNet2-cs\) 同样都好于 \(FlowNet2-C\)
- \(FlowNet2-s\) 精度和原来的 \(FlowNet\) 相当, 但是达到了140fps的速度
2.4 小位移(Small Displacements)
FlowNet 2.0对大位移图像有着很好的结果, 但是对小位移图像就gg, 作者也无法解释(There is no obvious reason why the network should not reach the same performance.). 因此作为妥协, 又加了一个小型网络专门用于处理小位移的图像, 并且为了训练该网络(需要用小位移图像)还造了个小位移的飞天椅数据集ChairSDHom.
然后那先前训练好的 \(FlowNet2-CSS\) 在Things3D和ChairSDHom上做fine-tune, 并适当减小前者的权重以强化小距离图像的影响. 最终发现在大位移图像预测精度没有损失的前提下, 对小位移图像的预测有了明显的改善.
2.4.1 小位移网络和融合
小位移的问题虽然可以用上述方法解决, 但是对于次像素运动(subpixel motion, 大概就是指小小小位移)还是不能很好的预测. 作者再次推测这是原来的网络结构问题, 所以改了改原来 \(FlowNewS\) 的卷积核大小, 反卷积后加了一个卷积层, 称为 \(FlowNet2-SD\) 网络, 所以需要融合它和 \(FlowNet2-CSS\). 融合方式看上面的结构图, 不再赘述.
2.5 实验和结果
最后看看各种网络结果的图可视化:
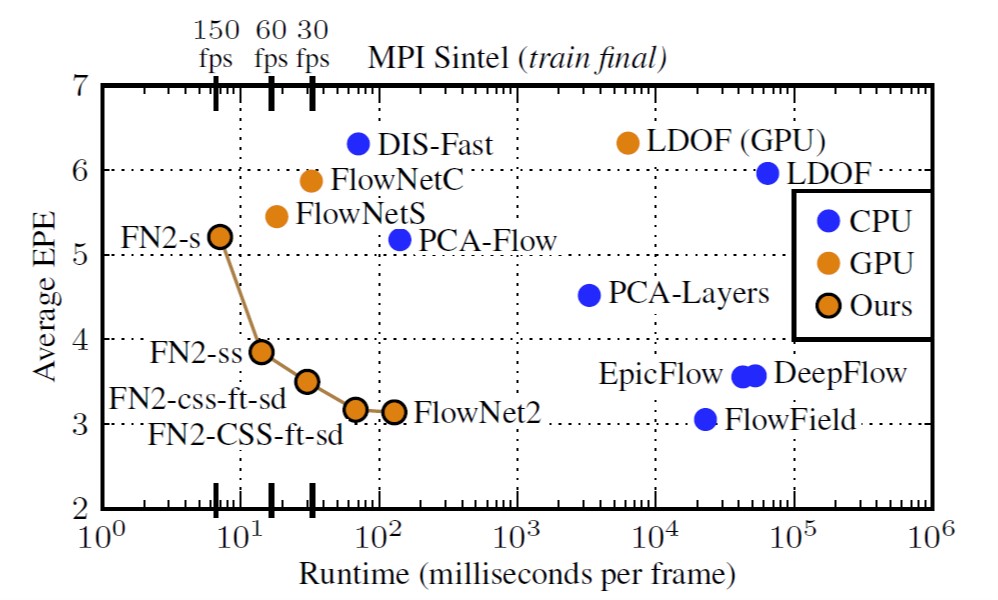
运行时间 vs 端点误差EPE
从图中可以明显的看出(1)第1代FlowNet首先引入了神经网络在整张图上计算光流, 虽然速度快, 但是效果达不到state-of-the-art(2)第2代FlowNet稍微地损失了一些计算速度(通过叠加多个网络), 明显的提升了光流的预测效果并达到了state-of-the-art, 但仍然没有超过.(3) \(FlowNet2-CSS-ft-sd\) 是看起来最好的一个结构了, 在保证了效果的前提下速度是最快的, 基本可以达到25fps(\(10^{1.6}\) ms/frame).
网络结构和实验思路就这么多了, 具体实验结果和分析可以参考原文.
2.5.1 演示
3. 光流网络的应用
Fully-Coupled Two-Stream Spatiotemporal Networks
本文的目标是低分辨率图像 (\(12\times 16\)) 中的动作识别. 网络结构如图.
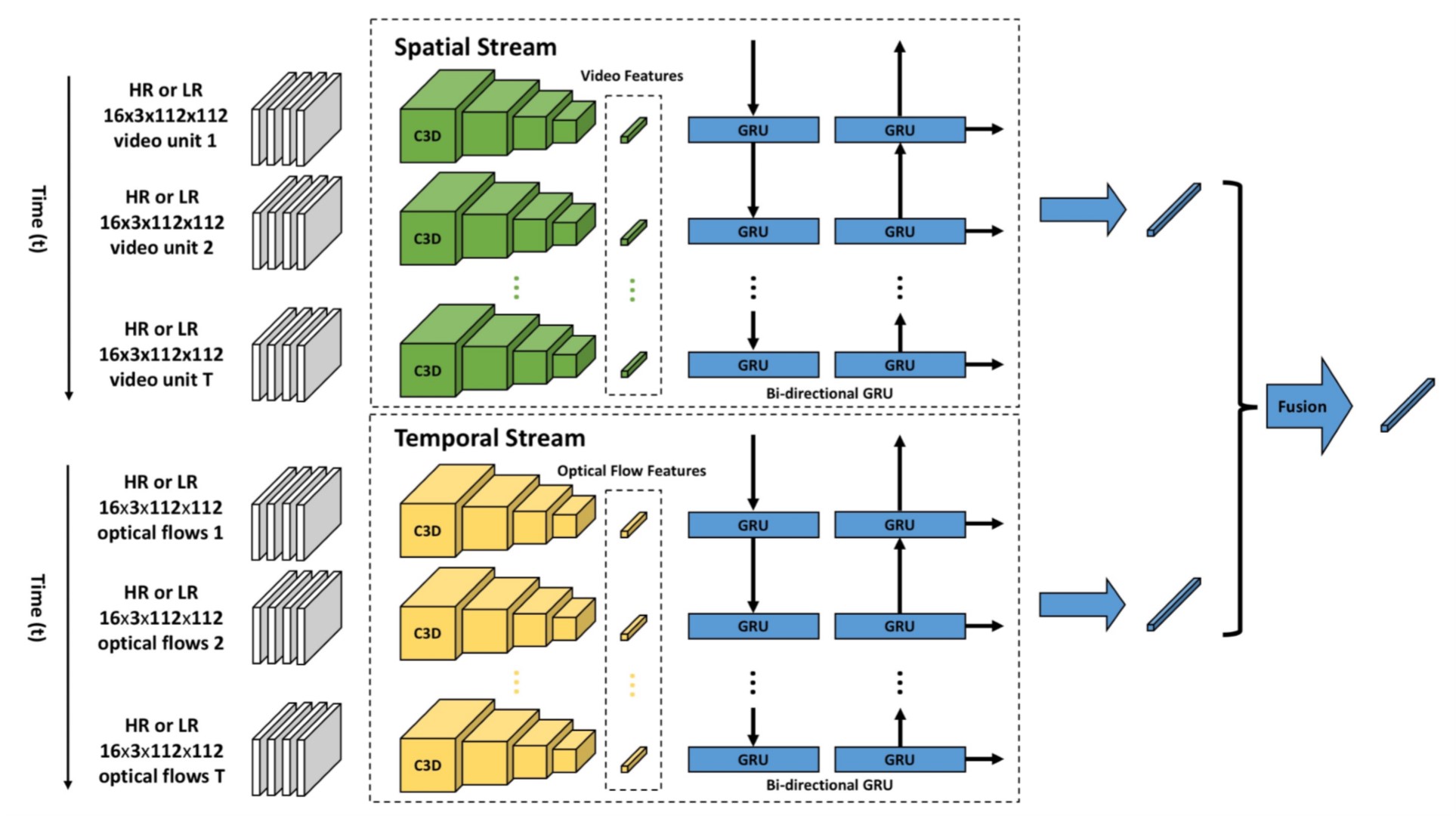
网络结构
下面对网络结构做一个简单的说明:
Two-Stream指的是上下两条路线.- 第一条线处理的是原始视频, 第二条线处理的是对应的光流.
- 输入的视频先分段, 然后使用 C3D 网络提取特征.
- C3D是一个三维卷积网络. 原文链接
- GRU对分段的视频提取上下文信息, 提高对动作识别的效果.
Fusion模块把视频和光流的特征向量融合在一起用于分类.
本文的亮点在于Fully-Coupled, 即使用高清视频做预训练, 然后混合高分辨率视频和低分辨率视频样本在同一个网络训练.