本文假设读者已经懂得了 Tensorflow 的一些基础概念, 如果不懂, 则移步 TF 官网 .
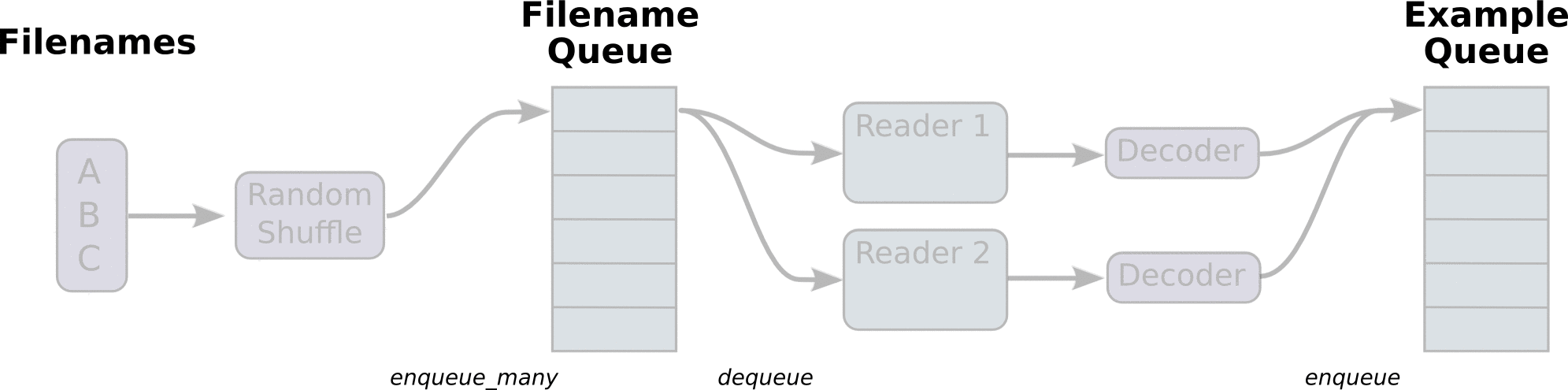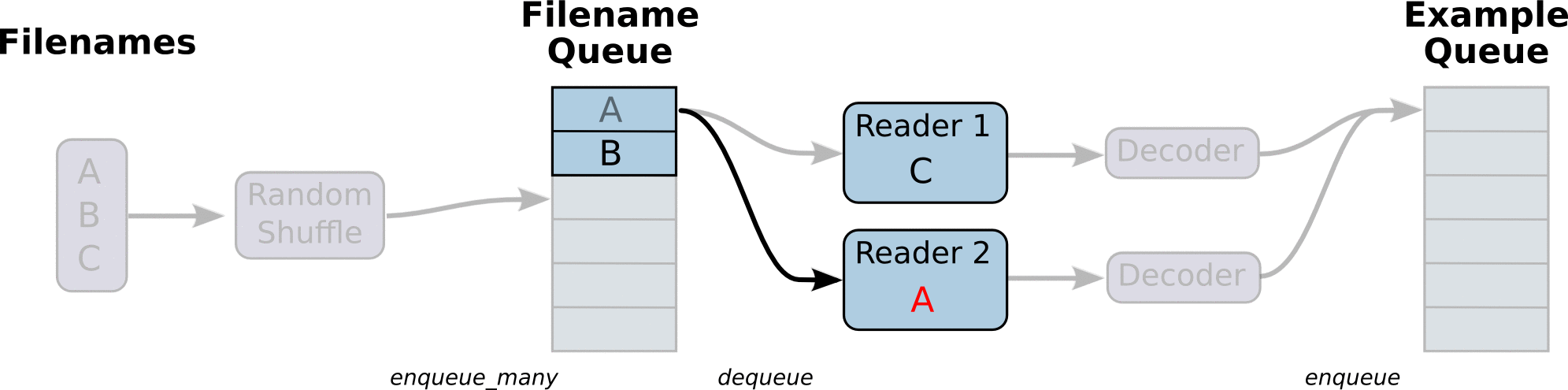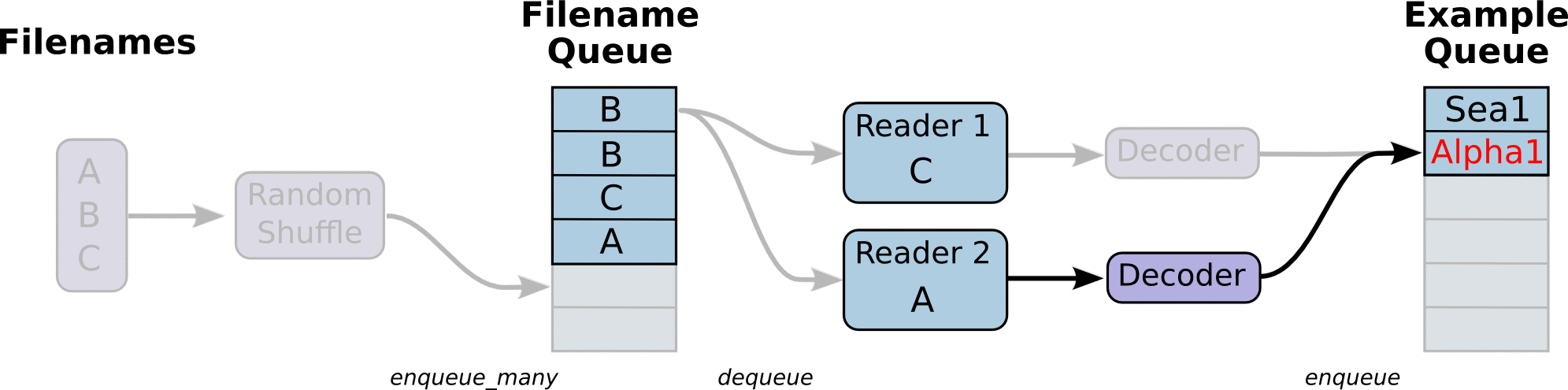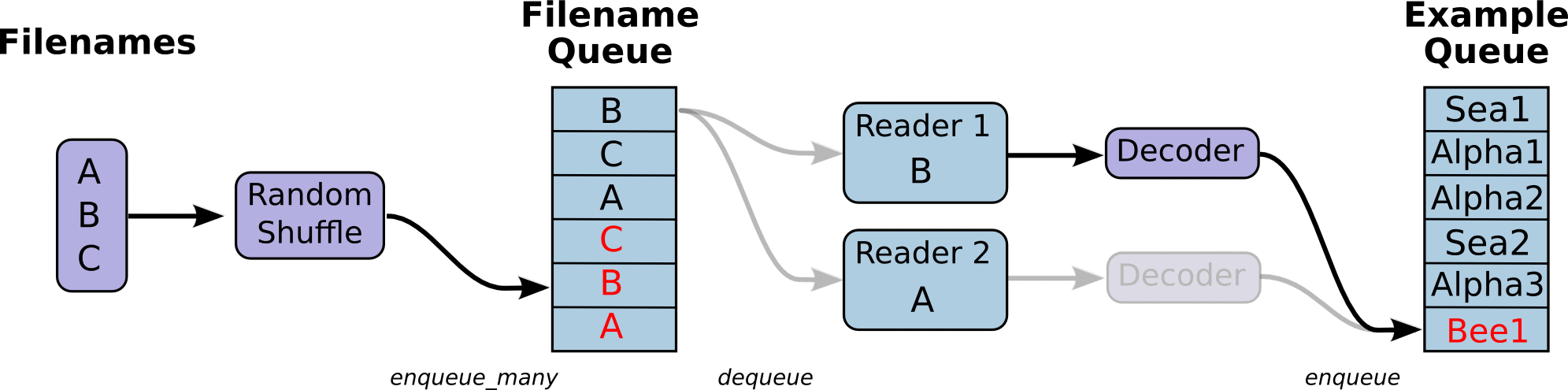
图 1. Tensorflow 数据输入管线
1. 数据预处理: Data —> TFRecord
由于 Tensorflow 使用 *.tfrecord 文件的效率是极高的, 所以预处理数据并保存为该格式可以有效地提高训练速度. 当然了, 预处理数据也是需要时间的, 但是这一次性的制作可以保证之后长久的训练过程都能够高效地使用该数据集, 这样显然是更合理的.
1.1 数据协议栈的简略分析
1.1 节介绍一下 TF 中序列化数据的表达方式, 不感兴趣可以跳过, 直接看 1.2 节.
在 TF 中, 每个独立的数据成为视为一个 tf.train.Example 对象(这里的 Example 是使用 proto3 协议来序列化数据的), Example 的定义如下(protobuf 语言):
1
2
3
message Example {
Features features = 1;
};
而每个 Example 只有一个 Features 属性, 我们要做的就是给该属性赋值, 我们先看一下 Features 的定义:
1
2
3
4
message Features {
// Map from feature name to feature.
map<string, Feature> feature = 1;
};
可以看到, 我们需要给其中 feature 属性赋值, 而 feature 是一个 map<string, Feature> , 在 Python 中其实就是字典. 字典的键是一个字符串, 值是一个 Feature 对象, Feature 的定义如下:
1
2
3
4
5
6
7
8
message Feature {
// Each feature can be exactly one kind.
oneof kind {
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};
每个特征可以从 BytesList , FloatList 和 Int64List 中三选一, 这三个数据类型定义如下:
1
2
3
4
5
6
7
8
9
message BytesList {
repeated bytes value = 1;
}
message FloatList {
repeated float value = 1 [packed = true];
}
message Int64List {
repeated int64 value = 1 [packed = true];
}
其中重复字段表示这是一个数组(Python 中称为列表). 这里解释一下 [packed = true] 的用法:
- 只有原始数值类型的重复字段才可以声明为
packed - 使用
packed后表示该字段会采用更加紧凑的编码格式, 同时不会造成数据的损失.
1.2 创建 Example 对象
接下来我们给出一个创建 Example 对象的示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 创建要写入的文件
record_writer = tf.python_io.TFRecordWriter(filename)
# 图像数组, 标签, 图像大小, 图像名称
image = np.arange(3*1024*768).reshape(3, 1024, 768)
label = 1
height, width = 1024, 768
name = "a_string"
# 定义 Example 对象
example = tf.train.Example(
features = tf.train.Features(
feature = {
"i": tf.train.Feature(bytes_list=tf.train.BytesList(value=[image.tobytes()])),
"n": tf.train.Feature(bytes_list=tf.train.BytesList(value=[str.encode(name)])),
"l": tf.train.Feature(int64_list=tf.train.Int64List(value=[label])),
"h": tf.train.Feature(int64_list=tf.train.Int64List(value=[height])),
"w": tf.train.Feature(int64_list=tf.train.Int64List(value=[width]))
}
)
)
# 写入文件
record_writer.write(example.SerializeToString())
2. 创建数据输入管线 Data —> Input
使用 Tensorflow 较为标准的数据输入一般来说有如下四种方法, 四种方法各有针对性, 简介如下:
- 最简单的方法, 完全在 python 中准备数据, 使用
tf.placeholder作为数据占位符, 训练/验证的每一步送入一批新的数据 - 消耗 NumPy 数组. 当所有的数据都已经载入内存时, 可以直接从数组创建数据集(警告: 此种方法会多次复制数组内容, 慎用)
- 消耗 TFRecord 数据. 当使用大型数据集(如图像数据集)时, 最好用这种方法.
- 消耗文本数据. 略
接下来详细介绍前三种数据输入的方法.
2.1 使用 Python 准备数据
这种方法是最简单的, 也最可能成为程序运行的瓶颈, 因为如果数据生成比较慢, 那么 GPU 每次算完都必须等待 CPU 产生下一批数据并馈送到 feed_dict 中才能继续计算, 这样很容易让 CPU 上的部分程序成为整个程序运行的瓶颈.
1
2
3
4
5
6
7
8
9
10
image = tf.placeholder(tf.float32, shape=[batch_size, None, None, channels])
label = tf.placeholder(tf.float32, shape=[batch_size])
# 直接使用 image 和 label 构建计算图
...
# 在 Python 中创建数据生成器, 每次迭代中产生一批数据并执行计算图
for i in range(max_iter):
image_batch, label_batch = data_generator.next()
sess.run(fetches, feed_dict={image: image_batch, labels: label_batch})
2.2 从 NumPy 数组创建数据集
这种方法对于 CV 中不太实用, 毕竟使用深度学习一般来说是大数据. 不过考虑到如果可以一次把数据载入内存, 也可以使用此种方法:
1
2
# features: [num_examples, ...], labels: [num_examples]
dataset = tf.data.Dataset.from_tensor_slices((features, labels))
请注意,上面的代码段会将 features 和 labels 数组作为 tf.constant() 指令嵌入在 TensorFlow 图中。这非常适合小型数据集,但会浪费内存,因为这会多次复制数组的内容,并可能会达到 tf.GraphDef 协议缓冲区的 2GB 上限。
作为替代方案,可以根据 tf.placeholder() 张量定义 Dataset,并在对数据集初始化 Iterator 时馈送 NumPy 数组。
1
2.2 从 TFRecord 创建 TF 数据集
假设我们已经创建好了 TFRecord 文件 filenames = ["data.tfrecord"] , 那么我们首先创建一个 TFRecordDataset , 同时可以指定数据集重复的次数, repeat 函数不指定参数则表示无限次遍历:
1
2
3
4
# 数据集只能便利一次
dataset = tf.data.TFRecordDataset(filenames)
# 数据集无限遍历
dataset = tf.data.TFRecordDataset(filenames).repeat()
接下来设置预处理数据缓冲区的大小(量内存大小而设置) (可选):
1
dataset = dataset.prefetch(2 * batch_size)
然后指定数据映射函数, 该映射函数用于把数据记录转为 Tensorflow 中的张量, 其中 num_parallel_calls 参数表示并行处理的元素个数. 注意, parser 函数中应当使用标准的 TF 操作, 具体示例稍后给出.
1
dataset = dataset.map(parser, num_parallel_calls=2)
一般来说训练时为了随机性, 需要对数据进行打乱, 首先给定一个缓冲区长度, 要求长度可以有效地保证打乱后的随机性, 然后执行打乱操作:
1
2
min_queue_samples = num_examples_per_epoch * 0.4 + 3 * batch_size
dataset = dataset.shuffle(buffer_size=min_queue_samples)
最后我们指定批大小, 并产生新的一批数据:
1
2
3
4
dataset = dataset.batch(batch_size)
# 创建迭代器, 由于我们一开始已经对数据集设置了 repeat 属性, 所以 one shot 的迭代器仍然可以无限迭代
iterator = dataset.make_one_shot_iterator()
image_batch, label_batch = iterator.get_next()
注意: 这里返回的 image_batch 和 label_batch 均为 Tensor , 所以 get_next() 函数在每个训练周期中定义一次即可.
注意到所有的 tf.data.TFRecordDataset 类中的方法均返回 dataset 本身, 所以我们可以一次性完成所有定义:
1
2
3
4
5
6
7
8
image_batch, label_batch = tf.data.TFRecordDataset(filenames) \
.repeat() \
.prefetch(2 * batch_size) \
.map(parser, num_parallel_calls=2) \
.shuffle(buffer_size=min_queue_samples) \
.batch(batch_size) \
.make_one_shot_iterator() \
.get_next()
映射函数
上文提到的数据映射函数应当按照如下的模板定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
def parser(serialized_example):
# 这里解析数据所使用的 features 的格式必须与创建 TFRecord 时一致.
features = tf.parse_single_example(
serialized_example,
features={
"image": tf.FixedLenFeature([], tf.string)
"label": tf.FixedLenFeature([], tf.int64)
}
)
# 这里的类型应当与保存图像时的类型一致
image = tf.decode_raw(features["image"], tf.float32)
image.set_shape([DEPTH * HEIGHT * WIDTH])
label = tf.cast(label, tf.int32)
# 调整通道
image = tf.transpose(tf.reshape(image, [DEPTH, HEIGHT, WIDTH]), [1, 2, 0])
# 数据增广
image = data_augmentation(image)
return image, label
使用同一个数据集对象产生不同的数据集迭代器
此外, tf.data.TFRecordDataset() 的参数还可以是张量, 也就是说我们可以使用占位符生成不同的数据集对象:
1
2
3
4
5
6
7
8
9
10
11
# 创建文件名的占位符
filenames = tf.placeholder(tf.string, shape=[None])
dataset = tf.data.TFRecordDataset(filenames)
dataset = ...
iterator = dataset.make_initializable_iterator()
# 使用训练数据集初始化数据集对象
training_filenames = ["trainset1.tfrecord", "trainset2.tfrecord"]
sess.run(iterator.initializer, feed_dict={filenames: training_filenames})
# 使用验证数据集初始化数据集对象
validation_filenames = ["validation1.tfrecord", ...]
sess.run(iterator.initializer, feed_dict={filenames: validation_filenames})
注意, 上面的示例代码中给出了另一种从 dataset 上产生迭代器的方法 make_initializable_iterator() , 这种方法需要通过运行 sess.run(iterator.initializer) 来初始化迭代器, 而 make_one_shot_itreator() 由于只迭代一遍, 所以它会自动初始化迭代器而不需要我们再次初始化.
使用 tf.py_func 应用任意的 Python 逻辑
参看官方文档
2.4 消耗文本数据
目前没做过 NLP 相关, 暂不考虑