论文题目: Group Normalization
作者: Yuxin Wu, Kaiming He
研究机构: Facebook AI Research
时间: 2018.03.22
前言
批归一化 (Batch Normalization, BN)[1] 提出后, 在深度学习领域扮演了一个重要的归一化的角色. 深度学习中由于经常使用大数据作为训练集, 所以无法把所有训练数据一次性载入内存而产生了批训练的方法(梯度下降). 从统计学的角度我们认为神经网络的学习特征的过程是一个学习数据分布的过程, 如果每一批的训练数据彼此的分布差异较大, 那么网络就需要不断地去适应不同的分布, 导致学习速度慢, 最终训练结果的精度也不够好.
但是 BN 也存在一些问题. 顾名思义, BN 的效果是依赖于批的, 批比较大时, 数据标准化的结果会与整个数据集更为接近; 批比较小时, 仍然会存在较大的局部偏差. 如图 1 所示, 随着批大小的减小, BN 的误差会快速增大, 尤其是极小的批(batch size = 1 ~ 4).
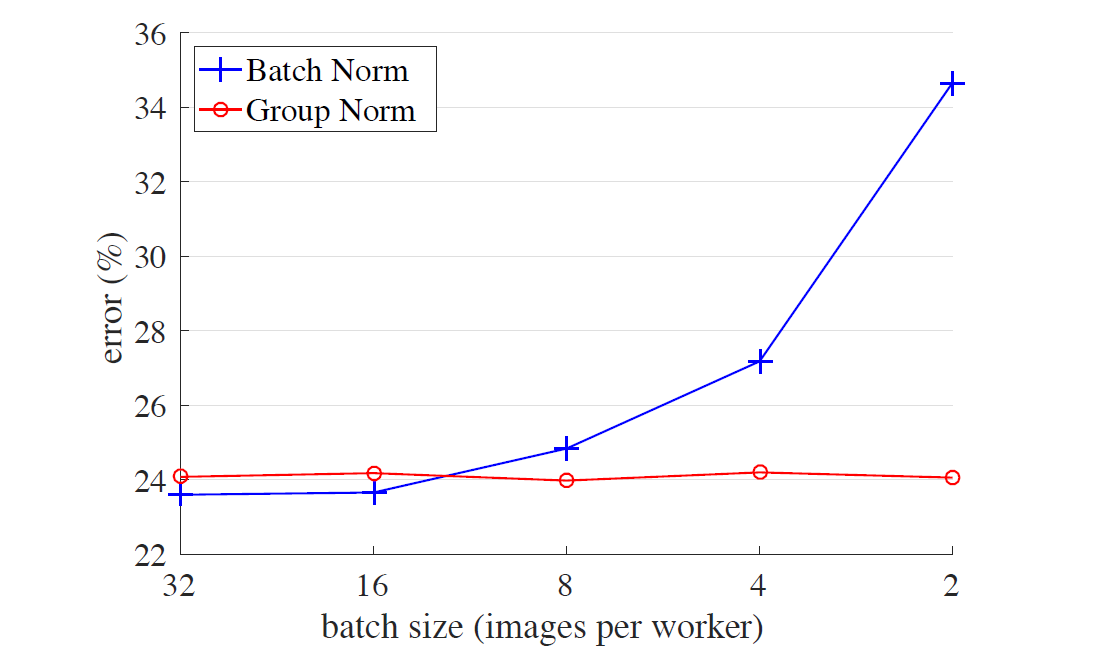
图1: ImageNet 分类误差 vs. 批大小. 这是一个在 ImageNet 上使用 8 个 GPUs 训练的 ResNet-50 的模型, 在验证集上评估.
本文的想法来源于以前的特征提取方法比如 SIFT, HOG 等提取出的是 group-wise 的特征, 并涉及到了 group-wise 的标准化. 比如 方向梯度直方图 (Histogram of oriented gradient, HOG) 特征检测算法把图像分为了多个块, 每个块分为四个 cell, 在每个 cell 内统计梯度方向, 从而每个块可以获得一个 k 维的特征向量, 然后对每个特征向量进行标准化. 这是一种组标准化的思路, 本文借鉴后提出了在神经网络的张量上, 把多通道分成组, 实施组标准化. 目前已有的标准化方法有
- 批标准化 (Batch Norm, BN)
- 层标准化 (Layer Norm, LN)
- 实例标准化 (Instance Norm, IN)
- 权重标准化 (Weight Norm)
如图 2 所示.
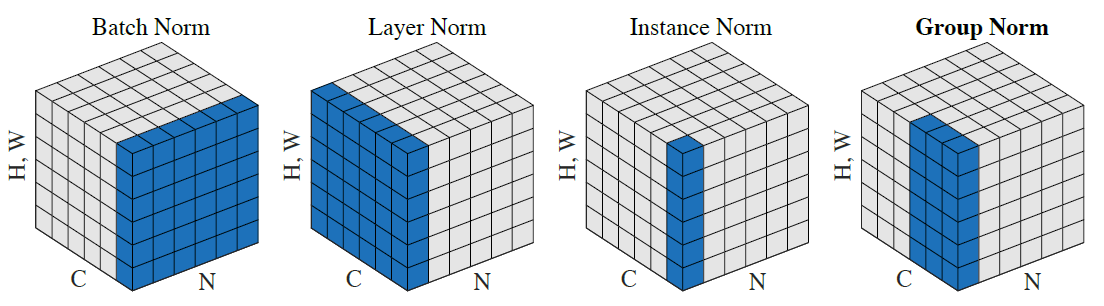
图 2: 标准化方法. N 表示 batch 轴, C 表示通道轴, H,W 表示空间轴
从图 2 可以看出 LN, IN 和 GN 都是在每个样本上单独计算的. 而 LN 和 IN 是 GN 的两种极端情况.
Group Normalization
标准化的通用公式是 \(\hat{x_i} = \frac1\sigma(x_i-\mu_i).\)
其中 \(x\) 是某层输出的特征. 在 2D 图像时, \(i = (i_N, i_C, i_H, i_W)\). \(\mu\) 和 \(\sigma\) 是均值和标准差
\[\mu_i = \frac1m\sum_{k\in \mathcal{S}_i}x_k, \qquad \sigma_i = \sqrt{\frac1m\sum_{k\in \mathcal{S}_i}(x_k - \mu_i)^2 + \epsilon},\]其中 \(\epsilon\) 是一个小的常数. \(\mathcal{S}_i\) 是计算均值和标准差的像素集合, 不同的标准化方法本质上也就是集合 \(\mathcal{S}_i\) 的不同.
| 标准化方法 | \(\mathcal{S}_i\) 定义方式 | 解释 |
|---|---|---|
| Batch Norm | \(\mathcal{S}_i: \{k\lvert k_C = i_C\}\) | \(i_C\)(和 \(k_C\)) 表示沿着 \(C\) 轴的指标. 左式的意思是同一个通道的像素在一起标准化. 即对于每个通道, BN 沿着 \((N, H, W)\) 轴计算 \(\mu\) 和 \(\sigma\) , 得到的形状为 \(C\) . |
| Layer Norm | \(\mathcal{S}_i: \{k\lvert k_N = i_N\}\) | 对于每个样本, LN 沿着 \((C, H, W)\) 轴计算 \(\mu\) 和 \(\sigma\) , 得到的形状为 \(N\). |
| Instance Norm | \(\mathcal{S}_i: \{k\lvert k_N = i_N, k_C = i_C\}\) | 对每个样本每个通道, IN 沿着 \((H, W)\) 轴计算 \(\mu\) 和 \(\sigma\) , 得到的形状为 \(N\times C\). |
| Group Norm | \(\mathcal{S}_i: \{k\lvert k_N = i_N, \lfloor\frac{k_C}{C/G}\rfloor = \lfloor\frac{i_C}{C/G}\rfloor\}\) | \(G\) 表示分组的数量, 是一个预定义的超参数(一般选择 \(G=32\)). \(C/G\) 是每个组的通道数, 第二个等式条件表示对处于同一组的像素计算均值和标准差. 最终得到的形状为 \(N\times (C/G)\) . |
最后三种方法都会再做一个 scale 和 shift:
\[y_i= \gamma\hat{x_i} + \beta\]其中 \(\gamma\) 和 \(\beta\) 是可学习的参数, 对于所有的四种情况其形状均为 \(C\).
注意 Group Normalization 相比于 Layer Normalization, 只在每个 group 内部进行 normalization 操作, 这实际上是减弱了假设的强度. Layer Normalization 是假设所有的 channel 共享相同的均值和方差, 这会限制 channel 的表达能力; 而 Group Normlization 把这种限制减弱到 \(G\) 个 group 中 (比如 32 个), 这样不同的 group 仍然可以学习不同的分布.
实现
论文给出的 Tensorflow 下的实现方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def GroupNorm(x, gamma, beta, G, eps=1e-5):
""" Implementation of group normalization
Params
------
`x`: input features with shape [N, C, H, W]
`gamma`, `beta`: scale and shift, with shape [1, C, 1, 1]
`G`: number of groups for GN
"""
assert C % G == 0, "C should be divisible by G"
N, C, H, W = x.shape.as_list()
x = tf.reshape(x, [N, G, C//G, H, W])
mean, var = tf.nn.moments(x, [2, 3, 4], keep_dims=True)
x = (x - mean) / tf.sqrt(var + eps)
x = tf.reshape(x, [N, C, H, W])
return x * gamma + beta
但是在 Tensorflow 和 Pytorch 中的 BN 均使用了 Moving Average, 下面给出 Tensorflow 带 Moving Average 的实现方法: