论文题目: Learning to Segment Every Thing
作者: Ronghang Hu, Piotr Dollar, Kaiming He, Trevor Darrell, Ross Girshick
研究机构: BAIR UC Berkeley, Facebook AI Research
时间: 2017.11.28
1. Introduction
目前在 COCO 数据集有大量的物体有 bounding box (short for bbox) 可用于有监督的物体检测算法, 但是实例分割的标注就少得多. 本文的目的是利用已有的充足的 Bbox 和少量的 segmentation mask 来对所有的物体进行实例分割, 同时作者指出这将会是让实例分割模型拥有对整个世界的认知能力的第一步.
本文提出了一个部分监督 (partial supervised) 的模型:
- 给定一个多类别的数据集, 一个有实例分割标注的小型子集, 其他样本仅有 bounding box 标注.
- 训练一个网络利用 1 中的数据来分割所有的样本.
本文的核心想法是利用迁移学习 (transfer learning) 把 bbox 网络的参数用于实例分割, 但并非直接复制, 而是乘以一个权重后迁移, 即加权迁移函数 (weight transfer function).
- Training: 使用所有的 Bbox 训练整个网络参数, 使用分割的标注数据训练加权迁移函数
- Inference: 应用加权迁移函数到 Bbox 回归的网络参数上作为实例分割的网络参数.
最终在两个数据集上进行训练:
- COCO 数据集 - 80类: 分为有分割标注和无分割标注两部分
- Visual Genome (VG) 数据集 - 3000类: 该数据集质量不高, 且是语义分割的标注, 所以由于物体语义上的重叠导致评估结果不可靠.
2. Learning to Segment Every Thing
注: 下文提到的 Bbox 分支同时包括 bbox 分类和回归.
2.1 使用权重迁移的 Mask 预测
本文基于 Mask R-CNN 提出了 Mask\(^X\) R-CNN . 在 Mask R-CNN 中 bbox 分支和 Mask 分支的参数是各自单独学习来的, 由于训练 Mask 的数据不足, 所以我们希望充分利用 bbox 分支的信息, 通过一个加权迁移函数把 Bbox 分支的参数映射到 Mask 分支. 下面我们定义该函数.
给定一个类别 c , 定义
- \(w^c_{det}\) 是目标检测的权重, 特指 bbox 子网络中的最后一层卷积的参数;
- \(w^c_{seg}\) 是目标分割的权重, 特指 mask 子网络中的最后一层卷积的参数.
这样我们仅需要训练变量 \(w^c_{det}\) , 而 \(w^c_{seg}\) 通过如下的公式得到:
\[w^c_{seg} = \mathcal{T}(w^c_{det};\theta),\]其中 \(\theta\) 是类别无关的可训练参数. 我们期望相同函数 \(\mathcal{T}(\cdot)\) 可以应用于任意的类别上, 因此 \(\theta\) 的取值应当使得 \(\mathcal{T}\) 可以泛化到其他训练过程中没有分割标注的类别上. 然后 (玄学来了) 我们认为这种泛化是可行的, 因为检测权重 \(w^c_{det}\) 可以被看作类别的一种基于外观的视觉嵌入 (apperence-based visual embedding).
当然了这里 \(\mathcal{T}(\cdot)\) 可以通过多种方法来实现, 文中使用了一个小型的全连接网络 (2-layer, LeakyReLU). 由于 Bbox 分支包含分类和回归两部分的权重 \(w^c_{cls} \& w^c_{box}\), 所以, 可以单独使用其中的一种进行迁移 (即 \(w^c_{det}=w^c_{cls}~or~w^c_{det}=w^c_{box}\)) 或者拼接在一起迁移 (即 \(w^c_{det} = [w^c_{cls}, w^c_{box}]\)) . 网络结构如图 1 所示:
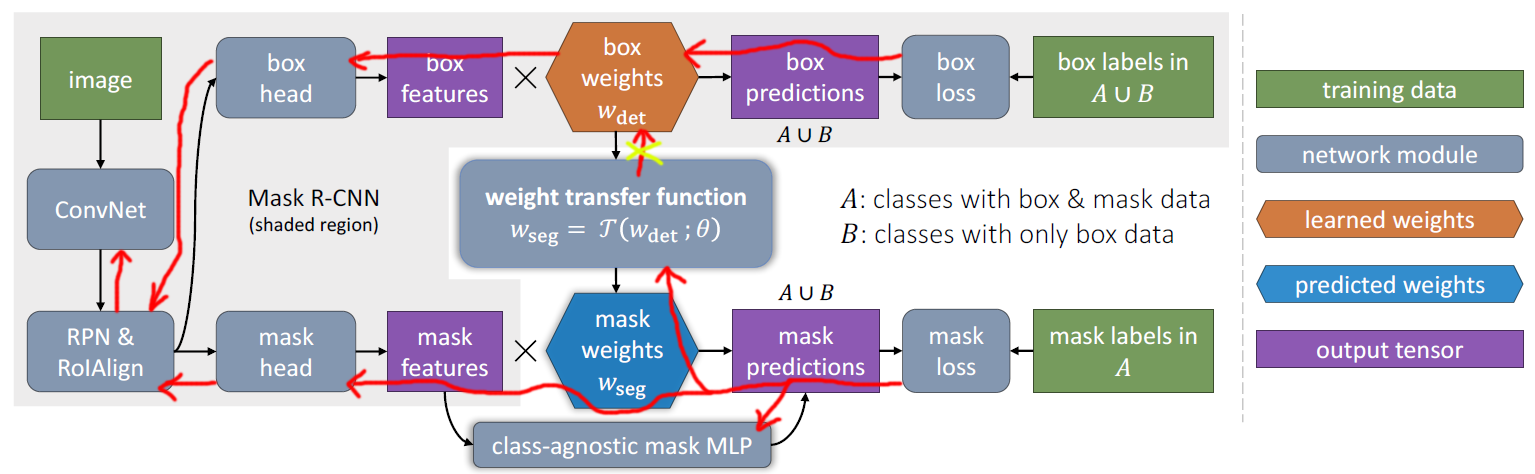
图 1: MaskX R-CNN 网络结构示意图. 基本结构延续 Mask R-CNN , 在 Bbox 分支使用可学习 (使用分割标注学习) 的权重迁移函数 $$ \mathcal{T} $$ 进行权重迁移, 在验证时可以使用所有的数据验证. 另外还使用了一个附加的全连接多层感知机来增广 mask 的头部.
2.2 训练细节
训练集分两部分 (这里是指目标类别的划分):
- A: 包含实例分割标注 (那么相应的 bbox 也可以从分割图中很容易的获取)
- B: 仅包含 bbox 标注
那么就可以使用 \(A\cup B\) 训练 bbox 分支, 仅使用 A 训练 mask 分支和迁移函数 \(\mathcal{T}\) . 下面介绍文中给出的两种训练策略:
多阶段训练
- 第一阶段: 仅使用 \(A\cup B\) 中的 bbox 标注训练 bbox 分支
- 第二阶段: 固定主干和 bbox 分支的权重不变, 使用 A 训练 mask 分支.
这样训练的好处是第一阶段训练好之后可以放着不动, 然后在第二阶段尝试不同的迁移函数. 但是最大的缺点是分离的训练会导致表现不佳, 原因是两阶段的信息分离会导致网络学习的不充分.
端到端联合训练
类似于 Mask R-CNN , 我们可以采取多任务的策略同时训练两个分支, 但是这样训练会导致 bbox 的权重 \(w^c_{det}\) 对待数据集 A 和 B 存在差异, 一个简单的解释就是 \(w^c_{det}\) 从权重迁移层只收到了数据集 A 传来的梯度. 所以文中采取的策略是: 反向传播时, 我们阻止 mask 损失对 \(w^c_{det}\) 的梯度, 即我们只计算 \(\mathcal{T}(w^c_{det}; \theta)\) 对 \(\theta\) 的梯度, 而不计算对 \(w^c_{det}\) 的梯度. 如图 1 所示, 梯度沿着红色线条反向传播, 在加权迁移函数的地方断开与 bbox 权重的连接, 这样可以达到与两阶段同样的训练效果而不会使 \(w^c_{det}\) 对数据集 B 存在歧视.
2.3 混合 FCN+MLP 的 mask 头部
考虑两种 mask 头部用于 Mask R-CNN:
- FCN, 使用全卷积网络产生 M×M 的 mask
- MLP, 使用多层感知机预测 mask , 这与 DeepMask 相似.
作者认为 MLP 更能抓取全局信息, 而 FCN 更能抓取细节信息, 比如边界. 可以看到图 1 中 mask prediction 的来源有两个:
- mask features × mask weights, 该预测是类别相关的, 所以会产生 \(K\times M\times M\) 的输出, \(K\) 是类别数.
- mask MLP , 该预测是类别无关的, 所以会产生 \(1\times M\times M\) 的输出,
为了把两个结合起来, 我们把输出 2 叠加 \(K\) 次然后与输出 1 加起来, 最后先经过 sigmoid 再经过二值交叉熵后 resize 到 bbox 的大小得到最终的输出 mask .
2.4 Baseline 和 oracle
- Baseline 是使用类别无关的 FCN mask 分支的 Mask R-CNN .
- oracle 是 Mask R-CNN 在数据集 \(A\cup B\) 上使用全部的分割标注来训练的 Mask R-CNN, 容易看出 oracle 是全监督的, 从而也是本文提出的部分监督的一个上界.
3. 对照实验
下面列出文中提到的对照试验的一些结论:
| 对照实验项目 | 实验组 | 最优选项 |
|---|---|---|
| 加权迁移函数 \(\mathcal{T}\) 的输入 | 1. 随机高斯向量 (randn) 2. 预训练的 GloVe 向量 3. Mask R-CNN 的 box 分支的分类权重 cls 4. Mask R-CNN 的 box 分支的回归权重 box 5. cls + box (concatenate) |
cls + box |
| 加权迁移函数 \(\mathcal{T}\) 的结构 | 1. 1-fc-layer + 不激活 2. 2-fc-layer + ReLU 3. 2-fc-layer + LeakyReLU 4. 3-fc-layer + ReLU 5. 3-fc-layer + LeakyReLU |
2-fc-layer + LeakyReLU |
| MLP 分支的影响 | 1. baseline 2. baseline + MLP 3. transfer 4. transfer + MLP |
加上 MLP 对 Mask R-CNN 和 MaskX R-CNN 的结果均有提升 |
| 训练策略 | 1. baseline + stage-wise 2. transfer + stage-wise 3. baseline + end2end 4. transfer + end2end 5. transfer + end2end + stop gradient on \(w_{det}\) |
端到端并且阻止部分梯度传播最好 |
| 类别组 \(A/B\) 的划分方法 | 1. 20 ~ 80 2. 30 ~ 50 3. …… 4. 60 ~ 20 5. 20 VOC ~ 60 non-VOC 6. 60 non-VOC ~ 20 VOC |
集合 A 中实例分割样本数越多, 网络在集合 B 上的预测结果越好, 如图 2 所示. |
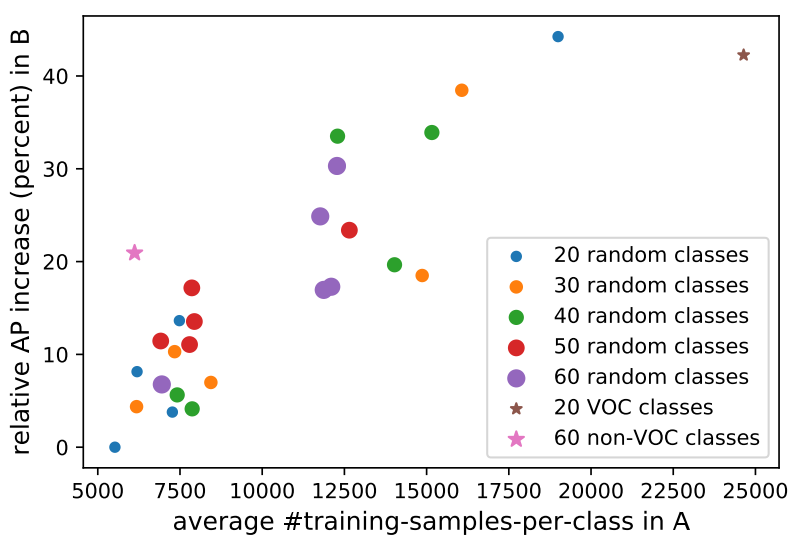
图 2: 每个点表示一种集合划分的方法. 纵坐标为采用每一种划分方法训练一次网络得到集合 B 上相应的 mask AP 值, 横坐标为集合 A 中所有类别拥有的平均的分割标注的数量